
总第73篇
本篇为书籍《数学之美》的一部分读书笔记,分两篇来完成,只摘录了书中我个人认为重要的、典型的部分章节的部分内容分享出来,有兴趣的可以自己买来看看。
01|文字和语言vs数字和信息:
1、数字、文字和自然语言一样,都是信息的载体,而语言和数学的产生是为了记录和传播信息。
2、通信模型
发出者发出的信息源先编码然后经过信道传输给接收者,接受者进行解码以后获得发出者的信息。
在通信时如果信道较宽,信息不必压缩可以直接传递,如果信道很窄,信息传递之前需要尽可能压缩,然后在接受端进行解压缩。
3、文字的歧义
对于一些多义字,我们不知道他在特定的环境下的含义,这样就有可能造成歧义。解决这种问题最好的方法就是联系上下文,来判断这个字在该环境下的真实意思是什么。
4、关于翻译
翻译这件事之所以能够完成,是因为不同的文字在记录信息方面的能力是等价的,也可以理解成文字只是信息的载体,而非信息本身。(这就是为啥英文和汉字表达的信息可以是一样的)
5、为什么现在用的是十进制而不是其他
因为早期人类计数是通过数指头,人类只有十根手指,所以就用的十。
02|自然语言处理从规则到统计:
1、因为我们人类在学习一种新的语言时经常会以语法作为我们第一个学习的知识,所以当我们在处理自然语言的时候也会惯性的朝这个方向去思考,但是这种是不可行的,因为对于短句子还可以凑合着用,但是一旦句子长度变长以后计算程度就会变得很复杂,是行不通的。
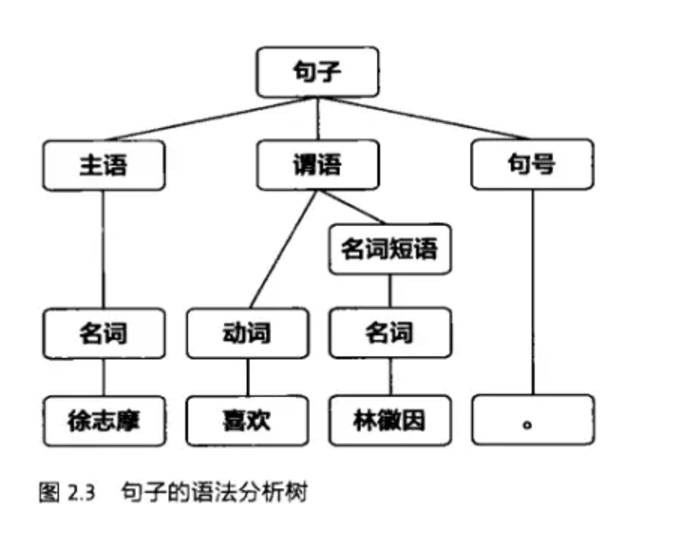
基于规则的处理就是上图那样。
2、基于统计的自然语言处理的核心模型是通信系统加隐含马尔可夫模型(后面会提到马尔科夫假设)。
03|统计语言模型:
1、自然语言从它产生开始,逐渐演变成一种上下文相关的信息表达和传递的方式,因此让计算机处理自然语言,一个基本的问题就是为自然需要这种上下文相关的特性建立数学模型,又称为统计语言模型。
2、统计语言模型的产生是为了解决语音识别的问题,在语音识别中,计算机需要知道一个文字序列是否能构成一个大家理解而且有意义的句子,然后输出给使用者。如果是基于规则分析的话就如前一章提到的,会去分析句子的语义和规则是否符合。但是前面说过这种是行不通的。
3、一个名叫贾尼克的专家提出了“一个句子是否合理,就看他的可能性大小如何”,也就是各个词排列顺序出现的可能性,至于可能性的话可以用概率衡量。
4、如果按第三条提到的去计算概率的话,需要计算第一个词以后每一个的条件概率然后相乘,但是这种遇到了同样的问题,如果句子过长,词数过多,计算起来就会很复杂。
5、针对上面第四条所面临的问题,一个名叫马尔可夫的科学家提出了一个假设,“假设任意一个词的出现的概率只与同他前面的与他紧挨着的词有关”,我们把这个假设称为马尔可夫假设。而在计算概率的时候只需要计算该词在语料库出现的相对频度即可。
6、上面第五条会有一个问题就是一个词在词库中出现的次数很少,也就是几乎接近于零,这样他的概率就是零概率。遇到这种问题我们该怎么处理,科学家古德-图灵提出了一种方案,即对这种概率越小的词继续减小他的概率。根据Zipf定理,即下图。
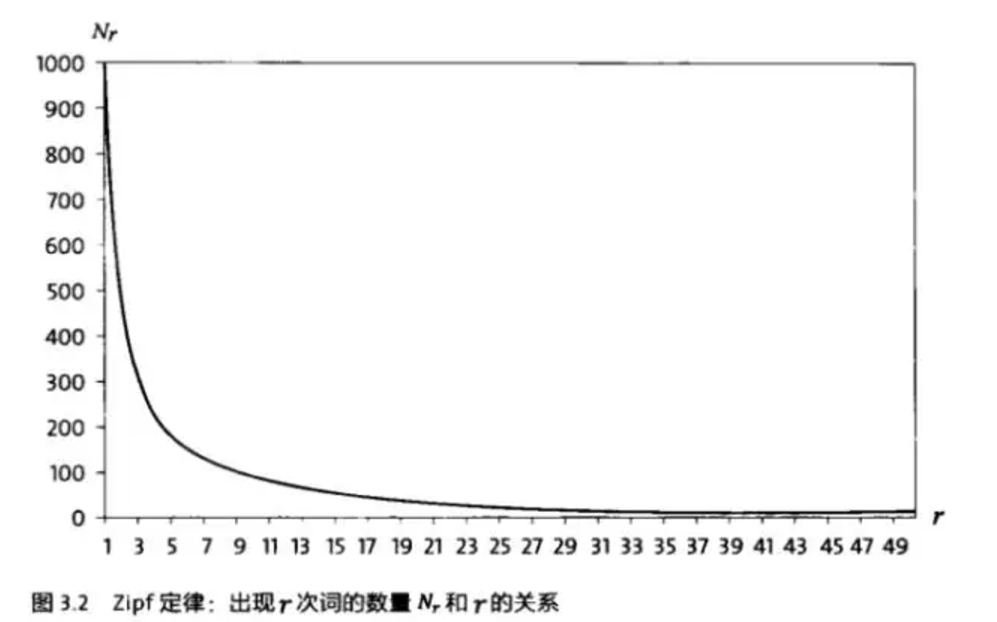
次数越多的词越少,我们为了减小这些小概率的词出现的概率,就增加他的次数。一般情况下对出现次数超过某个值的词不做概率下调,只有出现次数低于某个值的词才会对其做概率下调。
04|谈谈分词:
1、中文分词方法
在第三章我们知道了自然语言处理的统计模型,即正确语义顺序应该是看哪种排列顺序出现的概率大就用哪种。分词也是同样的道理,保证分词后这个句子出现的概率最大,就是最佳的分词效果。
05|信息的度量和作用:
1、什么是信息熵
信息熵是用来度量(量化)信息的,一条信息的信息量与其不确定性有着直接的联系,当我们需要了解清楚一件非常不确定的事情的时候,我们需要了解大量的信息。反之,当我们对一件事了解较多的时候,则不需要太多的信息就能把他搞清楚。从这个角度来看,信息量(熵)就等于不确定性的大小。
科学家香农提出了用不确定事件的概率乘他的log的对数来量化信息熵。
2、信息的作用
在前面提到过,信息量就等于不确定性的大小,而信息的作用就是为了消除不确定性,很多时候我们应该做的是寻找更多的相关信息去消除不确定性,而不是在很少或不相关的信息下面利用什么算法去计算,本质上没什么效果。
3、互信息
在第2小节中提到,我们应该寻找更多的相关信息来降低某件事情的不确定性,这里的这个相关信息我们还怎么理解,哪种程度叫相关呢,哪种程度叫不相关呢。科学家香弄提出了一个“互信息”的概念用来度量两个随机事件的“相关性”。
4、相对熵
相对熵也用来衡量相关性,但和变量的互信息不同,它用来衡量两个取值为正数嗯函数的相关性,相对熵越小,说明两个信号越接近。
在自然语言处理中常用来衡量两个常用词在不同文本中的概率分布,看他们是否同义。还可以利用相对熵得到信息检索中最重要的一个概念:词频率-逆向文档频率(TF-IDF)。
06|布尔代数和搜索引擎
1、搜索引擎的原理:
建立一个搜索引擎的大致流程是自动下载尽可能多的网页;建立快速有效的索性(这里的索性类似于图书馆的索性,图书馆里面每本书代表一个网页,那些分类索性和搜索这里的索性是一致的);根据相关性对网页进行合理的排序。
07|图论和网络爬虫:
1、图论
图论〔Graph Theory〕是数学的一个分支。它以图为研究对象。图论中的图是由若干给定的点及连接两点的线所构成的图形,这种图形通常用来描述某些事物之间的某种特定关系,用点代表事物,用连接两点的线表示相应两个事物间具有这种关系。
2、网络爬虫
在前面的章节中说到搜索引擎的第一步就是下载尽可能多的网页,这里就需要通过网络爬虫去获取,但是在具体获取的过程中以一种什么样的顺序去下载呢,这里主要利用两种图论中遍历算法:BFS(广度优先搜索)和DFS(深度优先搜索),两者的区别是前者尽可能广的访问不同的节点(即更多的种类的网页),而后者是尽可能深的访问一个以后隐藏的更多节点内容(一个网页里面的超链接)。
08|网页排名技术
1、网页排名的核心原理
在前面说搜索引擎的三要素分别是下载网页,建立索性,排名。排名的核心原理就是如果一个网页被很多其他网页所链接,说明他受到普遍承认和信赖,那么他的排名就高(排名是用来说明网页质量度)。具体一点就是一个网页的排名等于所有指向这个网页的其他网页的权重之和。而其他网页的权重又等于其自身网页的排名情况。
09|确定网页和查询的相关性
1、前面一章说到网页的排名与该网页的质量度有关,质量度越高,排名越考前。排名除了与网页质量有关以外,还与查询内容与网页内容的相关性有关。
2、度量查询与网页内容相关性
依据TF-IDF原理,TF-IDF等于TF*IDF,TF(Term-Frequency)中文意思是文字词频,就是该关键词在目标网页中出现的频率,计算方法为该关键词在网页中出现的次数比网页总词数。IDF(Inverse-Document-Frequency)中文意思是逆文本频率指数,通俗一点就是该关键词的权重,计算方法为:log(全部网页数/有关键词的网页数)。
3、一个词在越多的网页中出现,他对主题的预测能力越差,权重越小。对于一些语气词,比如的、是、和之类的词对主题没什么影响,我们把这一类词叫做“停止词(StopWord)”,这一类词在计算相关性的时候不计算在内。
10|余弦定理和新闻分类:
1、新闻的分类:
所谓分类,就是把相同类型的内容放到一类,这里的重点就是如何辨别两条新闻的类型是一样的呢。在前面的章节我们学过TF-IDF用来判断搜索词与网页的相关性,我们在这里也需要用到TF-IDF的概念,具体的操作方法是:计算出两篇新闻中每个词的TF-IDF值,然后把其按次表中对应顺序排好,这样两篇新文就变成了组数字(向量)。
根据余弦定理可得,两个向量的余弦值越大,对应的所成夹角越小,夹角越小,说明两组向量挨的越近,文章越相似。反之亦然。
PS:
在后台消息框回复数学之美,可获得本书籍电子书链接。

