
总第63篇
本篇主要从爬虫是什么、爬虫的一般流程、爬虫各个流程的实现方法、爬虫实例四个方面分享零基础了解爬虫,并进行简单的实战。
在阅读下面之前,我们需要对网页有个基本的了解,知道什么是标签,什么是属性,以及知道标题是放在哪,内容是放在哪,这些关于网站的基础知识。
可查看我前几篇关于网页基础知识的推文:
网页是怎么构成的?
网页的修饰
网页的行为
01|爬虫是什么:
爬虫又叫网页数据抓取,就是通过向浏览器发出请求并得到回应,把回应的内容抓取保存到本地的过程叫做爬虫。


比如,我要获取猫眼电影的TOP100榜电影的信息,其中包括电影名、主演、上映时间、评分以及封面图片。我们可以选择手动一条条登记,也可以写一个爬虫(通过浏览器向猫眼电影发出一个request然后得到一个response)去获取这些信息。
02|爬虫一般流程:
1、发起请求,通过HTTP库向目标站点发起请求,即发送一个Request。一般会包括下面这些部分。

2、获取响应内容,如果服务器能够正常响应,会得到一个Response,Response的内容便是要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(图片视频等一般为二进制数据)等类型。
3、解析内容,得到的内容如果是HTML,可以用正则表达式和网页解析库进行解析;如果是Json,直接转为Json对象解析;如果是二进制数据,可以保存也可以做进一步处理。
json.dumps():对json数据进行编码。(Python编码为json类型)
json.loads():对json数据进行解码。(json解码为Python类型)
4、保存数据,保存形式有多种,可以存为文本,也可以保存至数据库,或者保存到特定格式的文件。
03|实现上述爬虫过程的具体方法:
1、获取内容
这里的获取内容包括前面提到的request和response两个过程。
Urllib库
直接将目标网站链接url传递给urlopen函数即可。
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
print(response)#打印出得到回应的一行代码
print(response.read())#打印出获得的html内容
print(response.read().decode("utf-8"))#以“utf-8”编码的格式打印出获得的html内容
关于decode和encode的一些科普
字符串在Python内部的表示是unicode编码,因此,在做编码转换时,通常需要以unicode作为中间编码,即先将其他编码的字符串解码(decode)成unicode,再从unicode编码(encode)成另一种编码。
decode的作用是将其他编码的字符串转换成unicode编码,如str1.decode(‘gb2312’),表示将gb2312编码的字符串str1转换成unicode编码。
encode的作用是将unicode编码转换成其他编码的字符串,如str2.encode(‘gb2312’),表示将unicode编码的字符串str2转换成gb2312编码。
因此,转码的时候一定要先搞明白,字符串str是什么编码,然后decode成unicode,然后再encode成其他编码。
request库
将目标网站链接url传递给request.get函数即可。
import requests
response = requests.get('http://httpbin.org/get')
response = requests.get("http://httpbin.org/get?name=germey&age=22")#带有参数的url
print(response.text)#获取response的具体html内容
2、解析内容
所谓的解析内容就是用一定的方法从获得的全部内容中取出我们想要的某一部分内容,开头讲述的猫眼电影top100的获取,我们通过第一步获取内容取得是整个网页的所有部分,但我们只需要这所有部分中的标题、主演、评分等信息。
正则表达式
正则表达式是用一些符号去表示要匹配的内容,然后将其放在过程1中获得的全部内容中区匹配我们想要的内容。
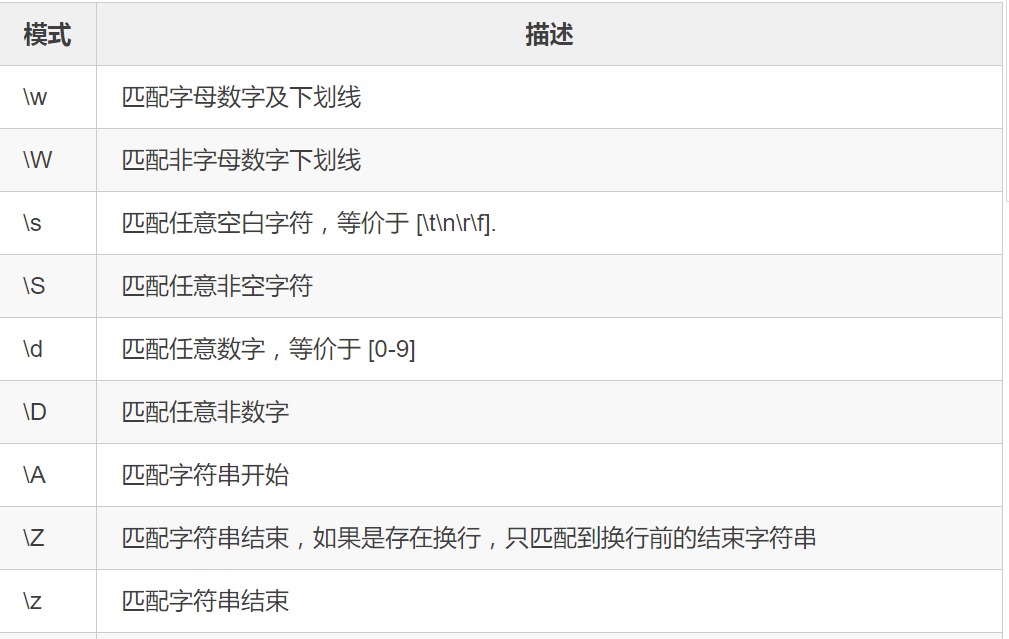
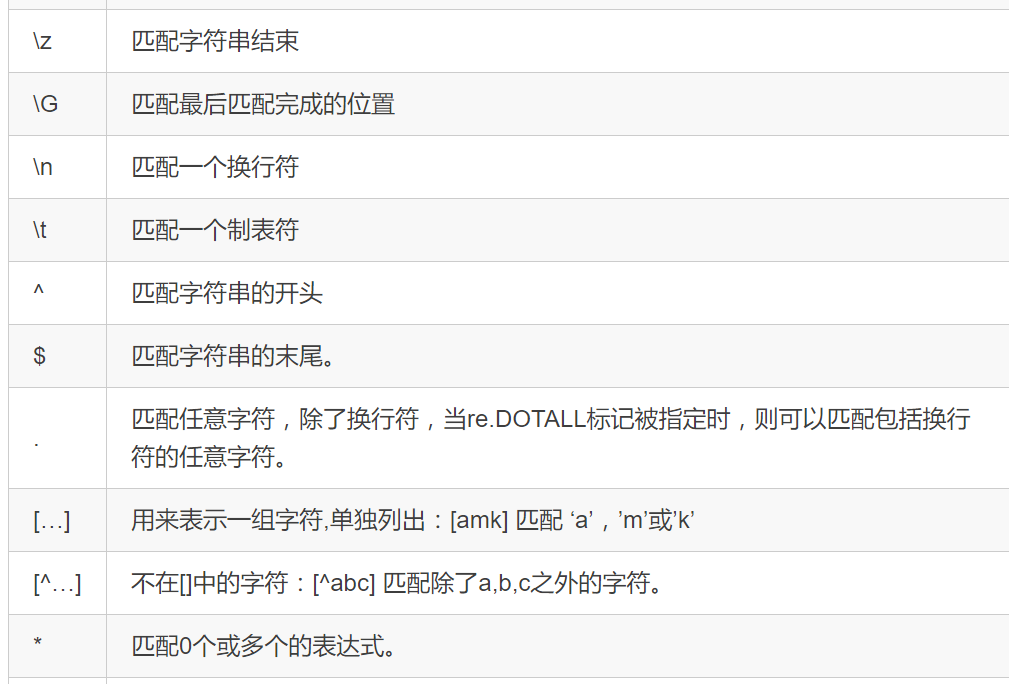
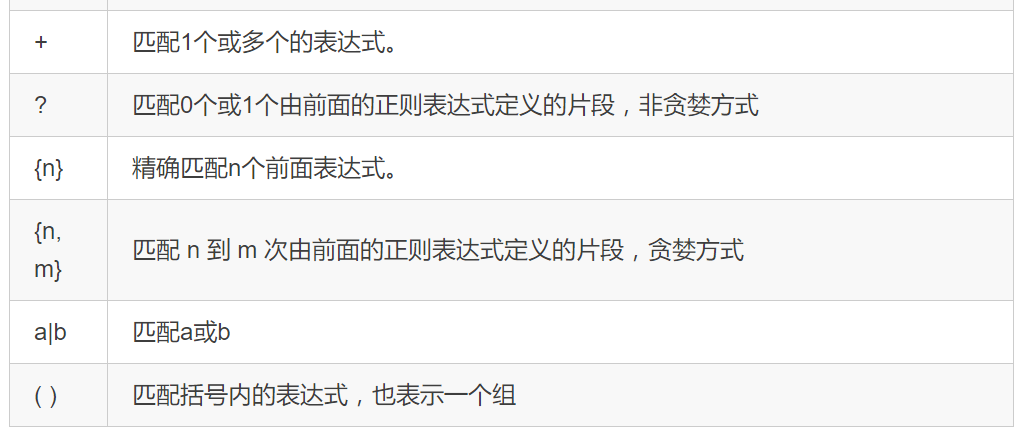
上面的表是直接copy的崔庆才老师的表,老师在天善智能有开设爬虫入门课程,课程链接:https://edu.hellobi.com/course/157/lessons
在正则表达式中我们常用的是re.findall(pattern,html,re.S),三个参数依次表示目标匹配内容(正则表达式书写的)、待匹配的全部内容(过程1获得的全部内容)、匹配模式。在后面的实例中我们就是用的正则表达式进行解析的,具体内容看后面的实例。
BeautifualSoup
BeautifulSoup是python自带的一个库,在这个库中我们常用下面这个选择器:
find_all( name , attrs , recursive , text , **kwargs )
参数依次要查找的标签名、属性和内容。该选择器输出内容为所有符合条件的项。
from bs4 import BeautifulSoup
soup = BeautifulSoup(html, 'lxml')#html表示要待解析的内容,lxml表示解析方式print(soup.find_all('ul'))#表示输出所有标签名为“ul”的内容
print(type(soup.find_all('ul')[0]))##表示输出第一个标签名为“ul”的内容
print(soup.find_all(attrs={'id': 'list-1'}))#表示输出属性id=list对应的值
print(soup.find_all(text='Jay'))#获取标签内的内容为“Jay”的项
3、保存内容到本地
先使用open创建并打开一个file对象,然后使用write方法将内容写入到这个file对象中。
with open('result.txt', 'a', encoding='utf-8') as f:#open用于打开一个文件,并创建一个file对象
f.write(json.dumps(content, ensure_ascii=False) + '\n')#write()方法的参数为字符串形式,所以需要用json_dumps将字典形式转化为字符串
f.close()
04|爬取猫眼电影实例:
获取内容
import requests
response = requests.get("http://maoyan.com/board/4")
print (response.text)

解析内容
import re#导入re库pattern = re.compile('<dd>.*?board-index.*?>(\d+)</i>.*?data-src="(.*?)".*?name"><a.*?>(.*?)</a>.*?star">(.*?)</p>.*?releasetime">(.*?)</p>.*?integer">(.*?)</i>.*?fraction">(.*?)</i>.*?</dd>', re.S)
items = re.findall(pattern, response.text)

(部分解析结果)
保存到本地
import jsonwith open('result.txt', 'a', encoding='utf-8') as f:#open用于打开一个文件,并创建一个file对象
f.write(json.dumps(items, ensure_ascii=False) + '\n')#write()方法的参数为字符串形式,所以需要用json_dumps将字典形式转化为字符串
f.close()

这样一个包含有电影信息的名为result.txt文件就保存到本地了。整个爬虫过程就完成了。


