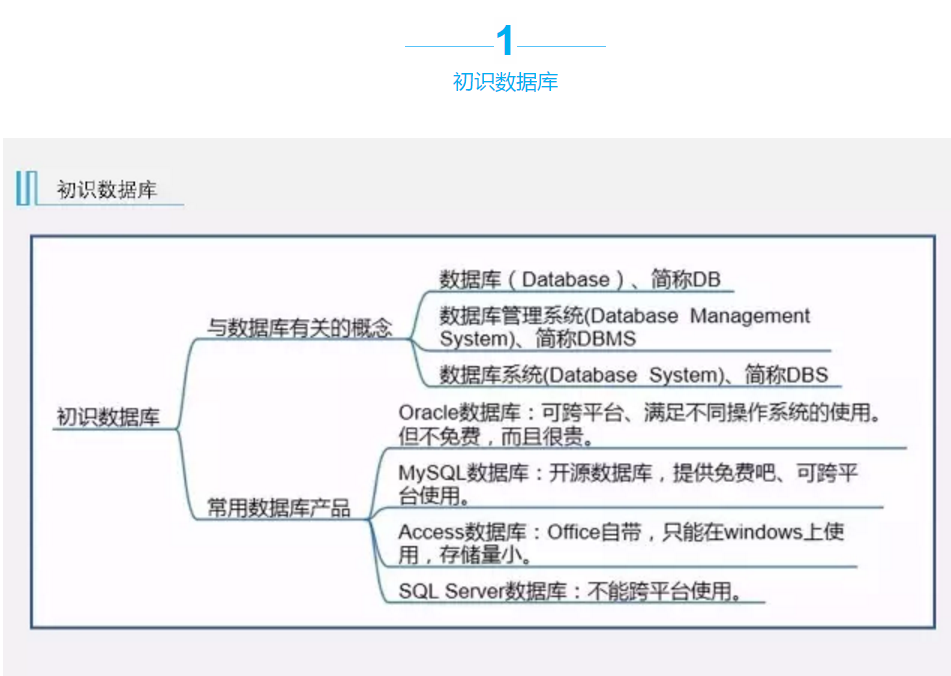
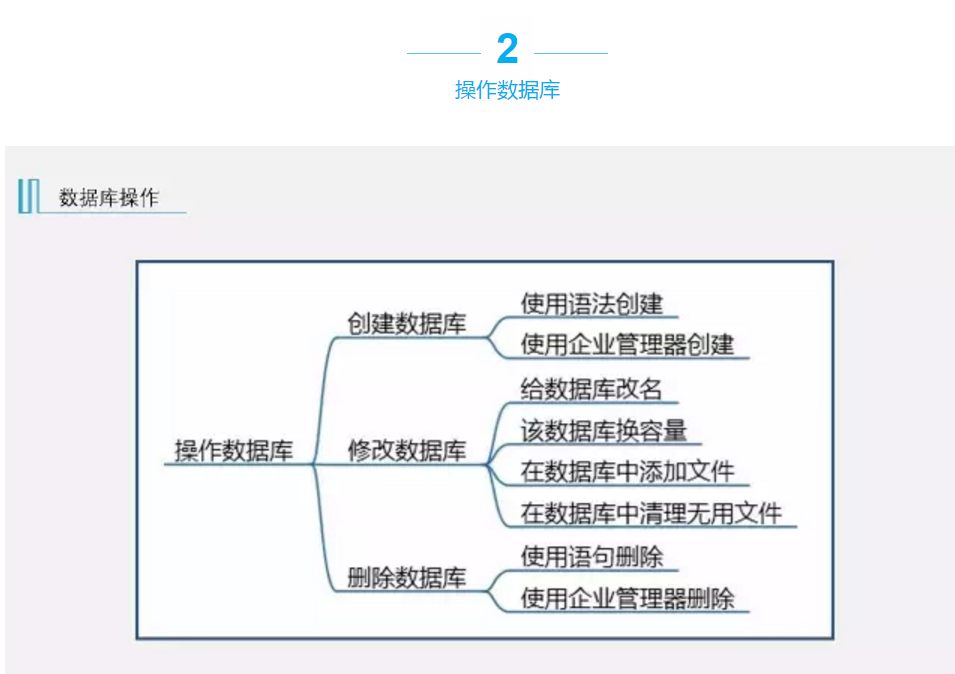
创建数据库
使用数据库时第一步就是要创建数据库,SQL中的数据库通常由数据文件和事务日志组成,一个数据库可以有一到多个数据文件和事务日志组成。数据文件就是存储数据的地方,而事务日志是用来记录存储记录存储数据的时间和操作的。数据文件的扩展名是.mdf,而事务日志文件的扩展名是.ldf。
1、创建数据库的语法:

注意事项:
(1)、chapter4表示数据库名称
(2)、ON PRIMARY表示主数据文件,一个数据库只有一个主数据文件,后缀名为.mdf,其他为次数据文件,后缀名为.ndf。
(3)、name表示数据文件的逻辑名称
(4)、filename表示数据文件的存放位置,前提是在D盘有一个database文件夹,没有的自行创建
(5)、size表示文件的大小
(6)、filegrowth表示文件的增长量
也可使用简单语句:Create database chapter 创建数据库,用该语句创建时,其他属性默认。
也可以通过企业管理器创建。
2、查看创建的数据库:
(1)、使用sp_helpdb命令可以查看所有的数据库,包括系统数据库。
(2)、使用sp_helpdb+ 数据库名字,可以查看该数据库的数据文件和事务日志。
修改数据库
1、给数据库改名
(1)、使用ALTERDATABASE 语句更改

(2)、使用存储过程sp_renamedb更改

2、给数据库换容量

以上属性中,不需要的更改的选项对应的语句不写出来即可。
删除数据库
使用语句DROP DATABASE database_name来进行删除。
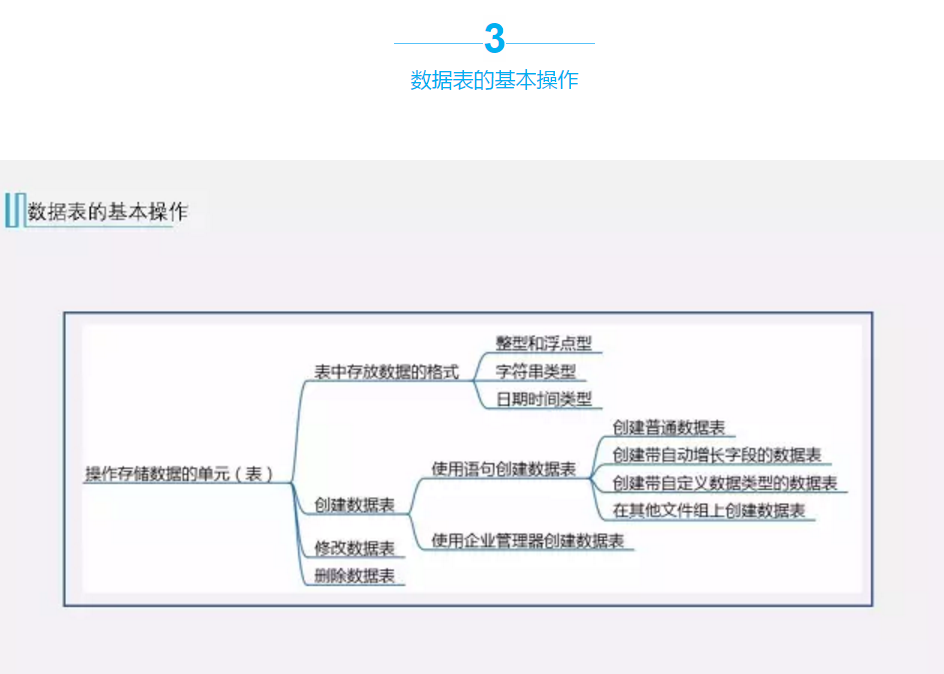
表中可存放的数据格式
1、整型和浮点型:都属于数值类型。
2、字符串类型:
任何数据都可以说成是字符串类型,汉字、字母、数字、一些特殊字符甚至是日期都可以用字符串类型来存储。
3、日期时间类型。
创建数据表

Table_name:表名,在数据库中数据表的名字不能重复,且数据表不能用数字来命名。
Column_name:字段名,表中的字段名也是不能重复的。
Datatype:数据类型,可以是系统的数据类型,也可以是用户自定义的数据类型。
修改数据表
修改表之前,都需要用USE指出引用的数据库
1、修改表中的数据类型

2、修改表中的字段数目
(1)、向表中增加字段

(2)、删除表中的字段信息

3、给表中字段改名

4、给数据表改名

删除数据表
创建和修改数据时每次只能创建或修改一张数据表,删除数据表时,一次可以删除多张数据表。删除语句如下:

也可以

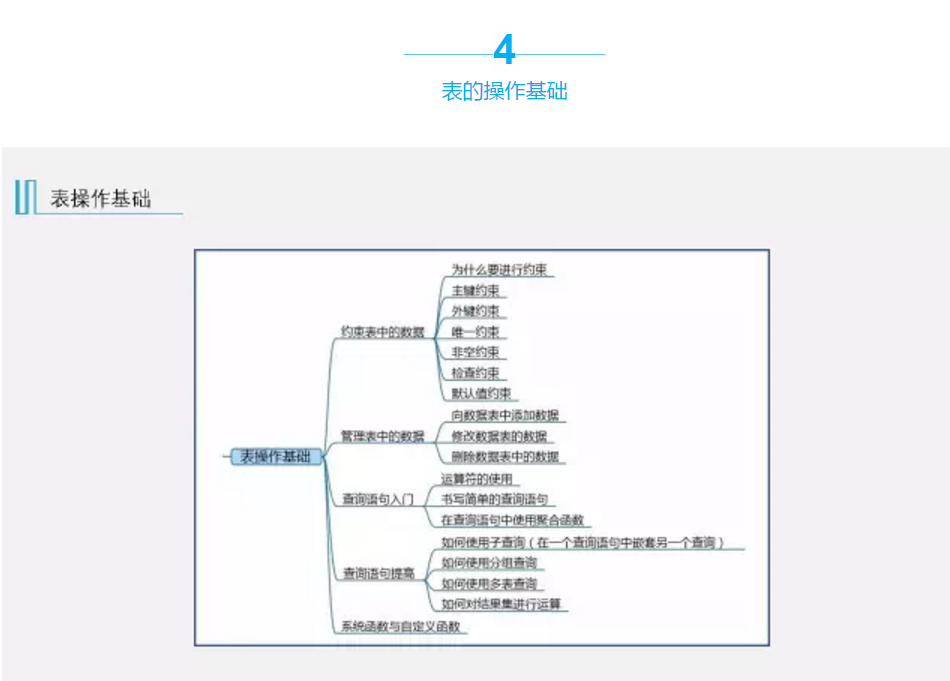
约束表中的数据
1、为什么要使用约束?
通过约束表中的数据可以使数据表不出错。
2、常见的约束有哪些?
主键约束、外键约束、默认值约束、唯一约束、检查约束、非空约束。
由于约束一般用的不多,所以就不展开描述,在用的时候直接上网学习即可。
管理表中的数据
1、向数据表中添加数据——INSERT语句

向数据库中添加数据时,列名和值要一一对应,如果未写出列名,则添加数据的默认顺序是列的存放顺序,这就引出两种添加方式,一种是向全部字段(即列)添加数据,只需不写出列名就可以;另一种是向部分字段添加数据,需要写出具体的添加数据列名,并与添加值一一对应。
一次添加多条数据的语法:

2、修改表中的数据——UPDATE

其中conditions表示更新条件,如果省略了WHERE语句,代表修改数据表中的全部记录。
修改前N条数据,使用关键词TOP(n),其中n是指前n条记录

3、删除数据表中的数据——DELETE

FROM关键字可以省略,conditions有的话按照条件删除语句,如果没有条件,则删除全部数据表全部数据。
简单查询表中的数据
1、SQL运算符
1)、算术运算符,主要包括加、减、乘、除、取余、取商。具体运算语句如下:SELECT100+200, 0.6-0.1, 500/100;其中SELECT表示运算。
2)、比较运算符,大于、小于、大于等于、小于等于。
在SQL中不能直接使用比较运算符对值进行比较,需要在查询语句中的WHERE子句或T-SQL编程时使用。
3)、逻辑运算符,and、or、not、all和in等
4)、位运算符
2、简单查询
查询操作是对表操作的一个重要操作,使用关键字SELECT。查询语句的基本语法如下:

注意:在查询之前要用USE表明使用的数据库。
1)、查询表中的全部数据:SELECT* FROM table_name;
2)、查询某几列数据,SELECT column_name1, column_name2, FROM table_name;
3)、给查询结果中的列换个名称
使用AS关键字给列设置别名,
SELECTcolumn_name1 AS ‘别名1’,column_name2 AS ‘别名2’,…….
FROM table_name;
4)、使用TOP查询表中的前几行数据
SELECT TOP(2) column_name1 AS ‘别名1’,column_name2 AS ‘别名2’,…….
FROM table_name;
5)、在查询时使用DISTINCT去除重复的结果
SELECT DISTINCT column_name FROM table_name;
6)、使用ORDER BY给查询结果排序
SELECT column_name1, column_name2, column_name3……
FROM table_name
WHERE conditions
ORDER BY column_name1 DESC|ASC, column_name1 DESC|ASC……..
ORDERBY子句后面可以放置1列或多列,在每一列后面还要指定该列的排序方式,DESC代表的降序排列,ASC代表的是升序排列。
7)、用LIKE进行模糊查询
SELECT column_name FROM table_name WHERE column_name LIKE ‘%’;

8)、用IN查询某一范围内的值
SELECT column_name1, column_name2,……
FROM table_name WHERE column_name IN(value1,value2,…..);
9)、根据多个条件查询数据
WHERE语句与逻辑运算符联合使用。
3、聚合函数
求最大值函数(MAX)、最小值函数(MIN)、平均值函数(AVG)、求和函数(SUM)、求记录行数函数(COUNT)
SELECT 函数(column_name)FROM table_name;
查询语句提高
简单查询是针对一张表进行的,而查询语句提高是针对多表进行的。
1、子查询
所谓子查询就是在一个查询语句中可以使用另一个查询语句中得到的结果作为条件进行查询,常用于两个表之间的查询引用。常用的子查询关键字有:IN、ANY、SOME、以及EXISTS。
(1)、IN关键字后面的查询就是一个子查询,是用来判断某个列是否在某个范围内。先执行in后面的语句,然后执行in前面的语句,并且IN后面的查询语句只能返回一列值。

中查找是节目信息表,prograntype是节目类型,typeinfo是节目类型表。
(2)、ANY通常被比较运算符连接ANY得到的结果,它可以用来比较某一列的值是否全部都大于(小于、等于、不等于等运算符)ANY后面的子查询中得到的结果。

ANY前面的“>”代表了对于ANY后面语句执行的任意结果都大于。
(3)、SOME关键字,与ANY关键字的用法比较相似,但是意义却不同,SOME通常用来比较满足查询中的任意一个值,而ANY要满足所有值。

上面语句中的“=some”与“in”功能相同。
(4)、EXISTS关键字代表存在的意思,当查询返回的结果为空,那么返回true,否则为false,当查询语句能够查询出数据时,则查询出所有符合条件的数据,负责不输出任何数据。

上面语句表示在节目信息表中选出与节目类型表中一致的信息。
2、分组查询
在学习分组之前,我们先弄清楚什么是分组。在现实生活中,经常会遇到分组,比如:扫雪时经常会把一个班级分成几个组,分别完成不同的扫雪任务。在数据库中的分组也是同一个意思,将数据按照一定条件进行分组,然后统计每组中的数据。
(1)、分组查询介绍

上面语句中:GROUPBY是分组查询的关键字,在其后面写的是按其分组的列名,可以按照多列进行分组。
HAVING是在分组查询中使用条件的关键字。该关键字只能在GROUPBY后面。它的作用与WHERE类似,都表示查询条件。
(2)、聚合函数在分组查询的应用

(3)、在分组查询中使用条件

上面两个语句使用了where和having两个不同的条件关键词,但是执行结果是一样,两者的区别是:where子句要放在groupBY 子句之前,也就是说他能够先按条件筛选数据后,再对数据进行分组。HAVING子句要放在GROUPBY 子句之后,也就是要对数据进行分组,然后再对其按条件进行数据筛选。还有一点使用HAVING语句作为条件时,条件后面的列只能是在GROUPBY子句后面出现过的列。
(4)、分组查询的结果排序

对查询结果进行排序,但是排序只能只能针对groupby 子句中出现过的列。
3、多表查询
在前面的查询时针对两张表之间的查询,而多表查询时针对的是更多表之间的查询。
(1)、同一个表的连接——自连接
查询语句不仅可以查询多张表的内容,还可以同时连接多次同一张数据表,把这种同一张表的连接称为自连接。但是在查询时要分别为同一张表设置不同的别名。

(2)、查询出额外数据的连接——外连接
在前面的查询语句中,查询结果全部都是需要符合条件才能够被查出,如果执行语句中没有符合条件的结果,那么在结果中就不会有任何记录。但是通过外连接查询,可以查询出符合条件的结果后还能显示出某张表中不符合条件的数据。外连接包括左外连接、右外连接以及全连接。

LIFTOUTER JOIN:左外连接。使用左外连接得到的查询结果中,除了符合条件的查询结果部分,还要加上左表中余下的数据。
RIGHTOUTER JOIN:右外连接。使用右外连接得到的查询结果中,除了符合条件的查询结果部分,还要加上右表中余下的数据。
FULLOUTER JOIN:全连接。使用全连接得到的查询结果中,除了符合条件的查询结果部分,还要加上左表和右表中余下的数据。
ON:设置外连接中的条件。与WHERE子句后面的写法一样。
(3)、只查询出符合条件的数据——内连接
内连接可以理解为是等值连接,也就是说查询的结果全部是符合条件的数据。但是内连接与外连接的语法相似。

4、结果集的运算
(1)、使用UNION关键字合并查询结果
所谓合并查询结果是将两个或更多的查询结果放到一个结果集中显示,但是合并结果是有条件的,那就是必须保证每一个结果集中的字段和数据类型一致。UNION关键字就是用来合并多个结果集的。

(2)、对合并的查询结果进行排序。

直接用orderby 对要排序的列名排序即可。
(3)、对结果集进行差运算。
结果集不仅可以进行合并运算,还可以进行差运算。差运算不是简单滴对结果集内容进行减法运算,而是从一个结果集中去除另一个结果集中的内容,使用关键词EXCEPT,其用法与UNION类似。进行差运算时要保证except前后的两个结果集列的个数和数据类型一致。

(4)、对结果集进行交运算。
交运算就是对两个结果集取交集,使用关键字INTERSECT,其语法形式与合并、差运算一致
