1、现有推荐算法
商品推荐系统根据算法分为基于内容,协同过滤和混合的推荐系统,这些算法目前都具有些局限性
1.1基于内容的推荐算法
算法的核心思想和关键步骤
基于内容的推荐算法起源于信息检索,通常用来推荐包括文本信息的文档信息的文档,网页和新闻等,即向用户推荐与他们过去喜爱的商品相似的商品,这个有两个关键步骤
第一,表示商品和用户喜好,一件商品定义为一个商品档案,包括商品的特征属性:一个 用户定义为一个用户档案,包括用户喜好,即该用户过去给予较高评分的商品的共同特征、商品用户档案都是由关键词组成,分别使用带权重的关键词向量来表是商品和用户,形式如(Key,value)通常;
第二,评估商品是否符合用户喜好,使用相似度量方法例如余弦相似度,计算商品,用户向量,W1,W2之间的相似度sim(p,u)
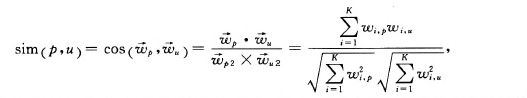
其中K表示商品和用户档案中所有关键词的数量,商品,用户向量相似度越大商品越符合用户喜好。
除了使用上述信息检索算法,基于内容的推荐系统还会使用机器学习算法,例如利用聚类,决策树,和贝叶斯分类器等进行推荐,其原理是根据商品的特征属性和用户评分,其原理是根据商品的特征属性和用户评分,训练出一个用户喜好模型使用模型计算该商品的条件概率,来预测用户是否会喜爱某件未知商品;
算法的局限性
基于内容的推荐算法的局限性有两点
(1)商品特征属性的提取,该算法需要提取足够多的商品特征属性来总结用户喜好,然而对于多媒体数据,如图片和视频等,提取特征属性比较困难;
(2)推荐商品过分拟合,推荐商品的特征属性仅限于用户过去喜爱的商品特征属性,导致推荐列表缺乏多样性,尤其是对新型商品而言,这种推荐算法完全失效;
1.2协同过滤算法
目前亚马逊等电子商务网站都使用这个推荐,都采用协同过滤算法:找到与用户有相似喜好的用户,向用户推荐相似用户过去喜爱的商品,该算法有两个关键步骤
第一,生成相似用户,对一个用户,找到与该用户有相似喜好的一组用户,并且把这组用户评过分的商品作为候选的推荐商品,一个用户包含一组购买历史,即用户评过分的商品和相应评分;使用用户的商品评分向量来表示用户,通常使用person关联度量公式,计算两两用户向量R1,R2之间相似度SIM(X,Y)
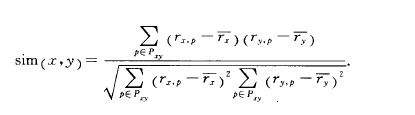
对一个用户,选择与其相似度由高到低排名前N个用户作为相似用户;
第二,预测商品评分,对一个用户,根据相似用户给候选商品的评分,预测该用户给候选商品的评分,推荐系统中的协同过滤算法根据预测商品评分的不同方法分为两类,基于记忆和基于模型的算法,前者计算一组相似用户U给候选商品
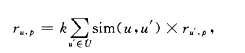
其中K表是规归一化因子子:后者使用概率模型建模,计算用户喜爱某件候选商品的概率
因为该算法计算了用户之间的相似度,所以又称为基于用户的协同过滤算法
算法局限性
协同过滤算法的局限性有两点:
(1)用户评分稀疏性,该算法需要用户给足够多的商品评分来计算用户的相似度,然而,一方面,新用户,新商品的评分较少:另一方面,一些用户较未独特,他们评过分的商品可能没有其他用户的评分,导致这些用户很难找到相似的用户,影响了推荐的准确性;
(2)算法的可扩展性,随着网上商品和选择网上购物的用户数量呈现爆炸式增长,生成相似用户的算法可扩展性成为急需要解决的问题;
1.3混合的推荐算法
混合算法是融合了基于内容推荐和协同过滤这两种算法的推荐算法,使用混合的推荐算法能够在一定程度上避免两种算法各自的局限性。现有混合推荐算法主要分为三类,第一类,合并单独实现的两种推荐算法,第二类,在协同过滤算法中使用基于内容的推荐算法的特性,即额外使用用户档案,计算用户之间的相似度,这一定程度上解决了协同过滤算法中存在用户评分稀疏性问题;第三类,构建一个同时实现两种算法的模型;


