什么是聚类呢?聚类就是一个把数据对象划分成多个组或簇的过程,每一个自己都是一个簇,使得簇内的对象具有很高的相似性,但与其他的簇中的的对象很不相似;那怎么去度量这些属性的相异性和相似性呢?通常都是根据描述对象的属性值去评估,并且通常涉及距离度量;基于技术上对分类划分的话,分成这几种:划分方法、层次方法、基于密度的方法和基于网格的方法。
划分方法:给定一个N个对象的集合,划分方法构建数据的K个分区,其中每个分区表示一个簇,并且K<=N,也就是它把数据划分为K个组,使得每个分组至少包含一个对象,大部分的划分方法都是基于距离的,K近邻也一样。
层次方法:层次方法创建给定数据对象的层次分解。根据层次分解如何形成,层次方法可以分为凝聚的或者分类的方法。
基于密度的方法:大部分划分方法基于对象之间的距离进行聚类,这样的方法只能返现球状簇,而在发现任意形状的簇时遇到了困难。其主要思想是,只要领域中的密度超过某个阈值,就继续增长给定的簇,也就是说,对给定的每个数据点,子啊给定半径的领域中必须至少包含最少数目的点;
基于网格的方法:基于网格的方法把对象空间量化为有限个单元,形成一个网格结构,所有的聚类操作都在这个玩个结构上进行;
下面各个聚类方法的特点

那么如何去度量一个结果的好坏的呢?主要评估如下:
估计聚类趋势:这项评估中,对于给定的数据集,我们评估该数据集是否存在非随机结构;即检验数据集是否具有类分性,而不是进行聚类;因为拒了要求数据的分布是非均匀的,而不是随机的,没有任何意义的;
确定数据集中的簇数:一般像K-means算法需要簇的作为参数。
测定聚类质量:在数据集上使用聚类方法后,我们想要评估结果簇的质量,又分外在方法和内在方法
A.外在方法:
A-1簇的同质性:这要求聚类中的簇越纯越好
A-2簇的完全性:如果两个对象属于相同的类别,则它们应该被分配到相同的簇
A-3碎步袋:包含一些不能与其他对象合并的对象,通常这些类别称为‘杂项’。
A-4小簇保持性:把小类划分成小片比将大类别划分成更有害。
B。内在方法:
B-1轮廓系数:就是一个在1和-1之间的系数,当轮廓系数越接近1时候,簇越是紧凑,并且簇之间原理其他簇。
我觉得K近邻分类算法应该是我个人认为最为简单的机器算法之一,它是作为分类为目的的算法之一;
线性模型对分类效果并不是很好,这时候有个较为简单的算法。
计算步骤如下:
1)算距离:给定测试对象,计算它与训练集中的每个对象的距离
2)找邻居:圈定距离最近的k个训练对象,作为测试对象的近邻
3)做分类:根据这k个近邻归属的主要类别,来对测试对象分类
分析步骤:
首先使用R语言自带的iris数据集,也就是莺尾花数据集,然后对数据集惊醒探索性的分析;
这时候我载入ggplot2包,这个包的用法和一般的画图用法不太一样,不过画图质量相当高,要是学习这个包的话我推荐本书《ggplot2数据分析与图形艺术》,跟着书上面的代码敲会有很大的进步;
绘制散点图,使用ggplot函数
install.packages("ggvis")
library(ggplot2)
ggplot(aes(x=iris$Sepal.Length,y=iris$Sepal.Width),data=iris)+geom_point(aes(color=iris$Species))
结果如下

ggplot(aes(x=iris$Petal.Length,y=iris$Petal.Width),data=iris)+geom_point(aes(color=iris$Species))

使用包class中的knn函数对数据集进行建模,这时候载入包class
install.packages('class')
library(class)
第一步先将数据集分为训练数据集和测试数据集
set.seed(1234)
ind <- sample(2,nrow(iris), replace=TRUE, prob=c(0.67, 0.33))
iris_train <-iris[ind==1, 1:4]
iris_test <-iris[ind==2, 1:4]
train_label <-iris[ind==1, 5]
test_label <-iris[ind==2, 5]
构建KNN模型,确定K为3,因为莺尾花数据集里确实为3类,不过实际中我们并不知道是为几类,所以要多试验几次
iris_pred <-knn(train=iris_train, test=iris_test, cl=train_label, k=3)
模型评价
table(test_label,iris_pred)
结果如下
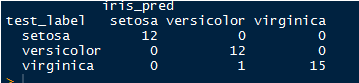
有一个被分错了,总体情况上看准确较高;
参考文献:《R语言核心技术手册》
《数据挖掘:概念与技术》


