让大家都会用bert。
几行keras代码就可以做基于bert的文本分类。
并且薅一波kaggle的算力羊毛和数据羊毛,体验一下bert的加载和微调。
之前也介绍过如何使用kaggle的GPU。
戳:自己的小霸王跑不起来?带你薅一波kaggle的算力羊毛,使用kaggle的好处除了可以白嫖它的计算资源,而且kaggle可以直接加载一些有用的数据或模型,比如预训练好的词向量或者预训练好的模型。
此外,kaggle还很良心的加入了TPU,让运算速度更进一步。
此外,引领NLP语义发展进入新阶段的bert,新手NLPer是不是也早就想上手玩一玩了呢?
今天我们就用keras写几行代码,加载bert预训练模型,实现文本分类。使用的数据集是kaggle很久之前的一个文本分类比赛。
训练数据是3个作家的文章,任务就是预测这些文章到底出自于哪个作家,是一个多分类问题。
比赛地址https://www.kaggle.com/c/spooky-author-identification。进入比赛链接之后,选择左侧的Notebooks,新建一个jupyter。
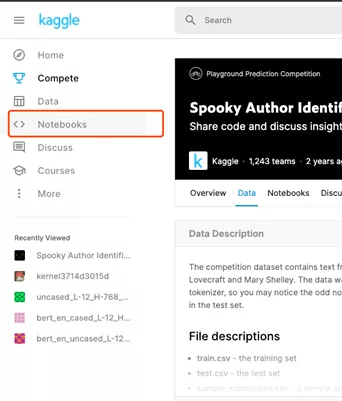
设置完基本参数之后,就进入到了jupyter notebook界面。
从kaggle中查找bert预训练模型。
搜索uncased_L-12_H-768_A-12, 我们选择作者是张鉴鸾的数据集。
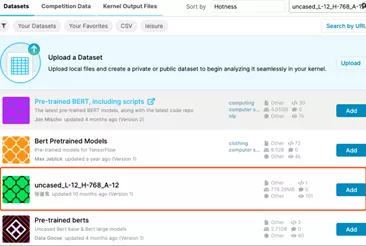
点击add按钮,bert预训练模型的参数就加入到了我们的notebook中。
在右侧的Accelerator中,选择GPU(还有TPU!但是我尝试了一下,没能加速,后续钻研)

模型代码就几行
x1_in = Input(shape=(max_x_len,), dtype='int32')
x2_in = Input(shape=(max_x_len,), dtype='int32')
x = bert_model([x1_in, x2_in])
x4cls = Lambda(lambda x: x[:, 0])(x) #取出每个样本的第一个向量。因为bert输入的第一个向量是<cls>,这个向量可以用来文本分类。
out = Dense(num_class, activation='softmax')(x4cls)
model = Model([x1_in, x2_in], out)
model.compile(optimizer = 'adam', loss = 'sparse_categorical_crossentropy', metrics=['accuracy'])model.summary()
小编为大家写好了baseline(尽量写了充足的注释),在没有数据预处理、没有调参的情况下,目前得分1.08160。
玩会了这个代码,基本可以用bert做大部分NLP任务了。
关注公众号,回复“bert”,即可获得ipynb源码。
欢迎关注我的公众号“数据科学杂谈”,原创技术文章第一时间推送。

