前文传送门:
从零开始学自然语言处理(28)—— Bi-LSTM+CRF完成命名实体识别任务
我的朋友,去面试NLP算法工程师,面试官问了一些问题,最后的几个问题,他没回答出。

当时的问题如下:
ELMo是什么?
ELMo和经典的word2vec有什么区别?
ELMo的使用过程是怎样的?
ELMo的几大优势是什么?劣势是什么?
为了回答这些面试问题,我们需要从头开始详细讲讲ELMo。
ELMo是在论文《Deep contextualized word representations》中提出的,时间为2018年,论文链接为:https://arxiv.org/pdf/1802.05365.pdf
ELMo是Embeddings from Language Models的简写,意思是通过语言模型做词嵌入。相信大家都已经熟悉word2vec和GloVe了,如果不熟悉,可以看看之前的文章:
从零开始学自然语言处理(二)——手把手带你用代码实现word2vec
从零开始学自然语言处理(三)——手把手带你实现word2vec(skip-gram)
从零开始学自然语言处理(十三)——CBOW原理详解
我们知道,在NLP任务中,很多任务开始时会先对词做词嵌入,我们以前常使用的方法是使用word2vec或者GloVe,那么,我们就能将词语Embedding成数学向量,例如‘apple’可以表示为[0.345,0.129,...,0.832],但是在不同的上下文中,一个单词的含义可能不太相同,例如‘apple’可以表示为苹果,也可以表示为苹果公司,这两个含义是相差很大的,而原始的word2vec和GloVe都只能用一个向量表示‘apple’这个词,这显然是不太ok的,于是ELMo出现了!
ELMo可以根据词出现的上下文,给词语赋予独一无二的Embedding!这样做之后明显的好处之一就是,对于多义词,可以结合前后语境对词进行理解。ELMo是一种预训练模型,我们可以通过自己的数据进行微调后使用,ELMo模型中包括了2层Bi-LSTM,如下图所示:

我们仔细看看这个模型的结构:
下面这个公式是前向LSTM语言模型的公式:
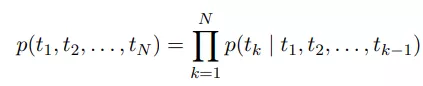
这里的tk为token,可以理解为词语,所以等式左边计算的是一句话出现的概率,右边的公式是典型的语言模型公式,在我们之前讲N-gram时,提到过:
从零开始学自然语言处理(十六)—— 统计语言模型(上)
而后向LSTM语言模型的公式:
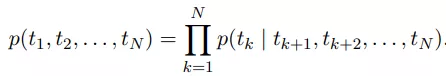
为了同时考虑前后文,所以ELMo使用的是Bi-LSTM,在论文中称为biLM。关于LSTM和Bi-LSTM,我们在之前已经写过:
从零开始学自然语言处理(二十)—— 强大的长短期记忆网络(LSTM)(上)
从零开始学自然语言处理(21)—— 强大的长短期记忆网络(LSTM)(下)
从零开始学自然语言处理(22)—— 效果震撼的Bi-LSTM太强了!
10行模型代码带你完成Bi-LSTM+CRF的NLP任务!
而ELMo要做的是最大化前向和后向的似然概率,公式如下:

其中,θx为词的向量表示,θLSTM为LSTM网络结构中的参数,θs为softmax层的参数。
因为在每一个位置上,每一层Bi-LSTM都会输出相应的h(k,j),其中k为token在序列中的位置索引,j为所在的LSTM层索引,所以对于每个token,一共有2L+1个表征,因为2代表双向,L代表一共L层,+1是因为token输入进LSTM前本身的向量表示。
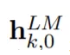 是token那层,也就是第0层,
是token那层,也就是第0层,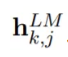 代表了正向和反向LSTM层中的第j层的第k个位置的输出,是正向和反向向量拼接而成。
代表了正向和反向LSTM层中的第j层的第k个位置的输出,是正向和反向向量拼接而成。
在下游任务中,一般会把Rk压缩成一个向量,ELMo使用通用的词向量表征法来表示,也就是用每层状态的线性组合来表示,如下: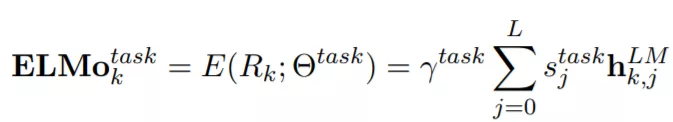
其中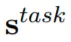 是每层的softmax-normalized向量,也就是加和为1的一组权重向量,每层的
是每层的softmax-normalized向量,也就是加和为1的一组权重向量,每层的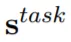 含有下标 j,然后是一个对所有层向量求和,
含有下标 j,然后是一个对所有层向量求和,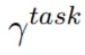 允许具体的任务模型去放缩 ELMo 的大小,所以上标有个task(任务)。
允许具体的任务模型去放缩 ELMo 的大小,所以上标有个task(任务)。
ELMo的使用流程主要如下:
(1)首先,在较大的语料库中预训练biLM模型,使用两层Bi-LSTM,并使用残差连接,作者提出,低层(第一层)的Bi-LSTM能获取语料中的句法信息,而高层(第二层)能获取语料中的语义信息。
(2)其次,在我们任务的语料中(忽略标签的)fine tuning 微调预训练好的biLM模型,称为domain transfer。
(3)最后,在具体的任务中,我们使用ELMo输出的词嵌入作为下游任务的输入,也可以作为下游任务的输出层。
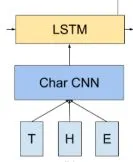
其实ELMo除了包含biLM,还有下层的CNN-BIG-LSTM,这部分是用来获得biLM输入的词向量,它是通过字符卷积的方法,如下图:
ELMO 在当时的六项任务上取得了the state of the art (当时的最好成绩)。
说了这么多ELMo的优点和巧妙之处!那ELMo没有缺点么?
现在回看,ELMo的缺点肯定你能猜到了,它使用的还是LSTM这种RNN结构,而不是Transformer。
ELMo的特征提取最后采用的是双向向量拼接方式,这和之后提出的Bert采用Transformer并使用一体化的特征提取和融合方式可能差了一些。
扫码下图关注我们不会让你失望!

