前文传送门:
从零开始学自然语言处理(26)—— 强大的Attention机制
回想起朋友之前找工作的悲惨经历,本来面试回答的挺好,面试官最后问了个NLP的问题,直接让他和50w年薪的工作擦肩而过..
当时面试的是数据挖掘工程师,朋友对数据挖掘算法早就很熟练了,在问了一些机器学习算法之后,也问了一些深度学习算法,幸好他早有准备,对于CNN、RNN、LSTM这些也算熟悉,直到面试官问了个近年来NLP领域十分流行的Transformer,他直接傻了...

其实这个Transformer作为最近几年NLP中流行的宠儿,经常被面试官问到,即使你知道这个,也会因为理解的不够深刻而被问懵掉,例如我朋友被问到的这些问题,我整理了一下:
Transformer 和 加入Attention的 RNN Encoder-Decoder相比,有什么优势?
Transformer中的多头注意力机制是什么?具体细节是?
Transformer中的位置编码是如何实现的,采用的编码有什么优点?
Transformer中的残差连接作用是什么?
我们还是系统学习一下Transformer吧,毕竟经常被问到 ...
在之前,我们通过上次的面试问题,详细讲解了Encoder-Decoder框架,并且加入了Attention机制解决了Seq2Seq中长文本(长句子)信息被表示为中间变量后的稀释问题。
Transformer是Google于2017年《Attention is all you need》这篇论文中被提出的,论文地址:https://arxiv.org/pdf/1706.03762.pdf
论文中模型的主要结构如下图所示:

这个结构看起来很复杂,我们一步步来看懂它!
Transformer也包含Encoder和Decoder两个部分。

上面论文图中的Nx代表有N个同样结构,如下图所示,是6个同样的结构堆叠而成:
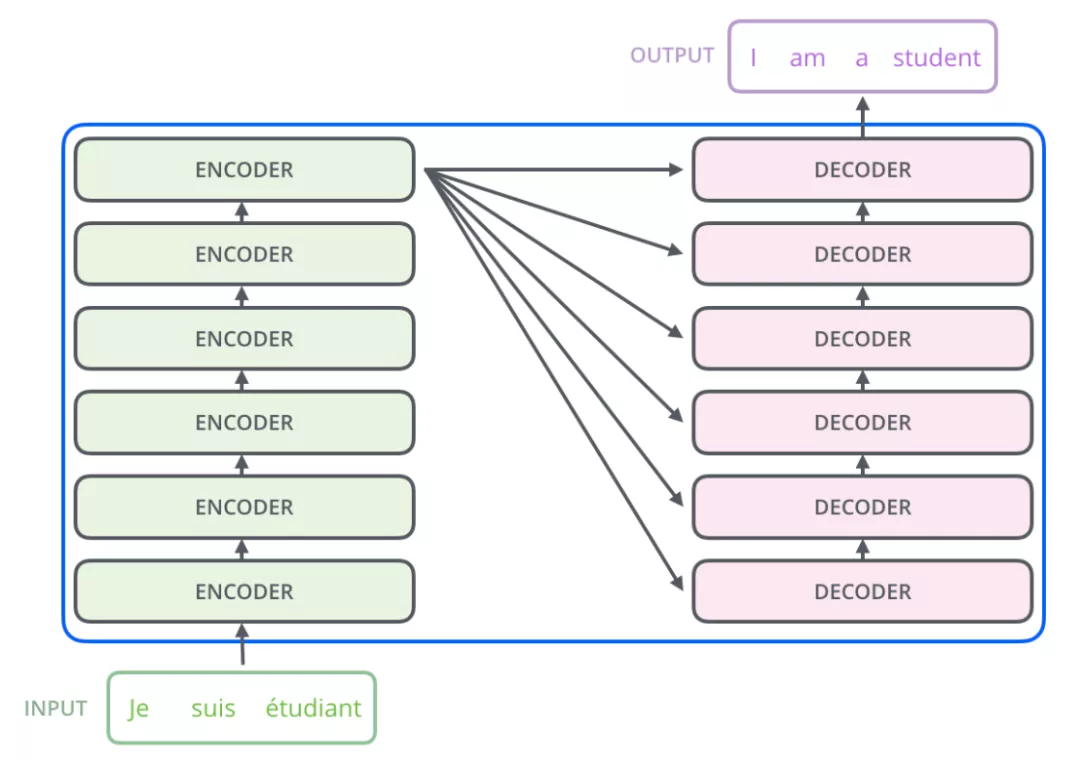
每个编码器子结构可进一步拆分:
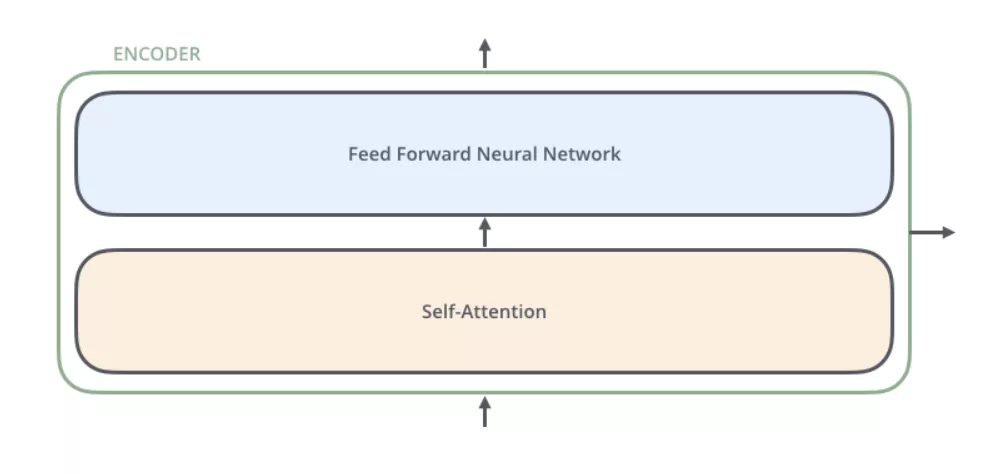
输入内容首先经过一层self-Attention(自注意力)层,这部分之后细讲,然后经过一层前馈神经网络。
下图是Encoder和Decoder,右边的Decoder中间的层可以关注输入部分来完成解码操作。

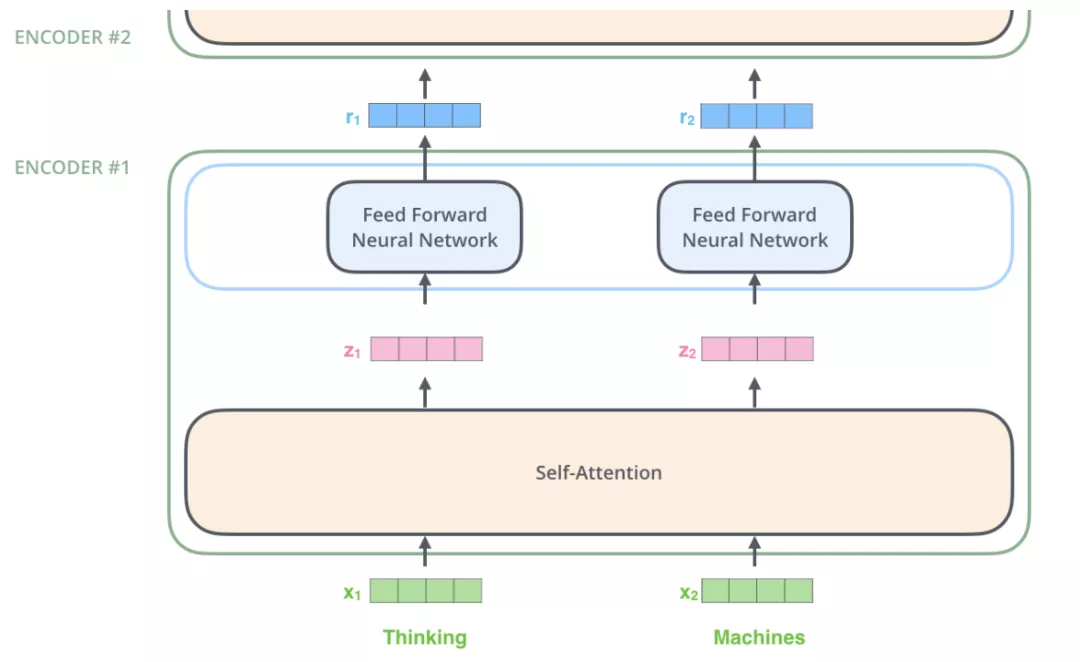
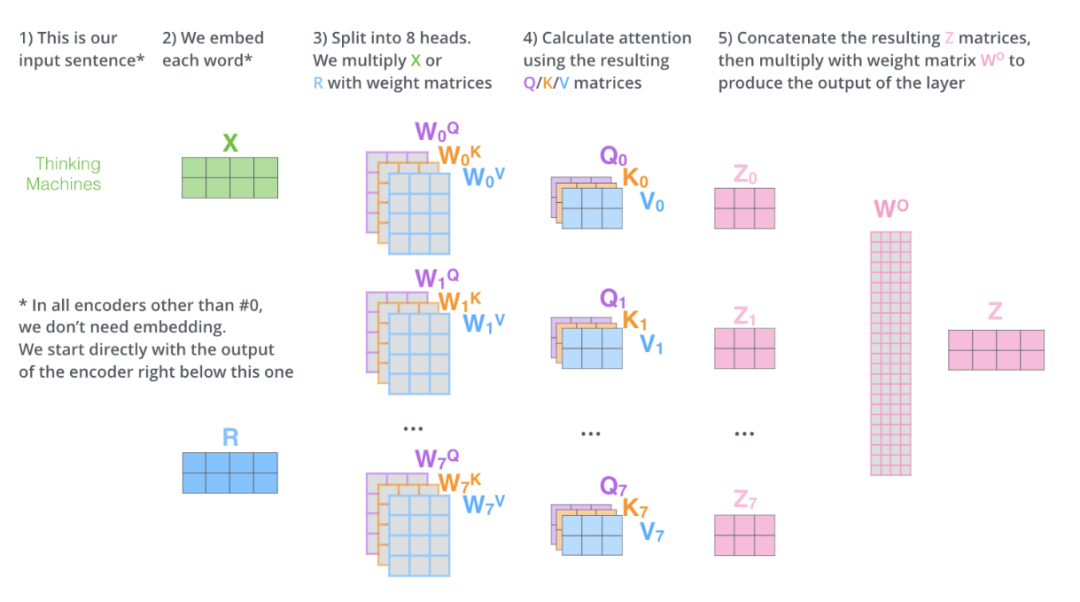
我们将以上的内容细化,首先Encoder接受的输入是Embedding之后的词语,这里每个词语的词嵌入绘制的是4维,其实是512维:
接下来详细讲讲self-Attention具体是什么意思,看下面这句话:
”The animal didn't cross the street because it was too tired”
我们在翻译“it”的时候,知道它指代的是animal,但是这句话在it之前出现了animal和street两个名词,如何让算法知道这一点呢?让算法知道it代表的是animal而不是street呢?
所谓的self-Attention(自注意力)就是解决了这个问题,自注意力指的是当模型处理每个单词(输入序列中的每个位置)时,自我注意力会让它观察当前输入序列中的其他位置,以寻找线索,从而帮助引导出这个单词的更好编码。
这就是自注意力机制,能通过当前序列的信息辅助当前正在编码的单词。
例如刚才那句话在对it进行编码时,self-Attention会关注序列所有词,下图中左边每个词的方块背景色和(深浅)it的连接线(粗细)可以代表词语和it的语义关联程度,例如“The animal”颜色最深,代表他们和it这个词的语义相关性较高,这样我们就让算法学会了it所指代的内容,self-Attention是不是犹如妙蛙种子进了米奇妙妙屋——妙到家了!

接下来,我们看看在算法细节上,如何实现self-attention的。
对于每个词的Embedding向量,我们创建一个Query向量、一个Key向量和一个Value向量。这些向量是通过将词嵌入乘以我们在训练过程中训练的三个矩阵来创建的。
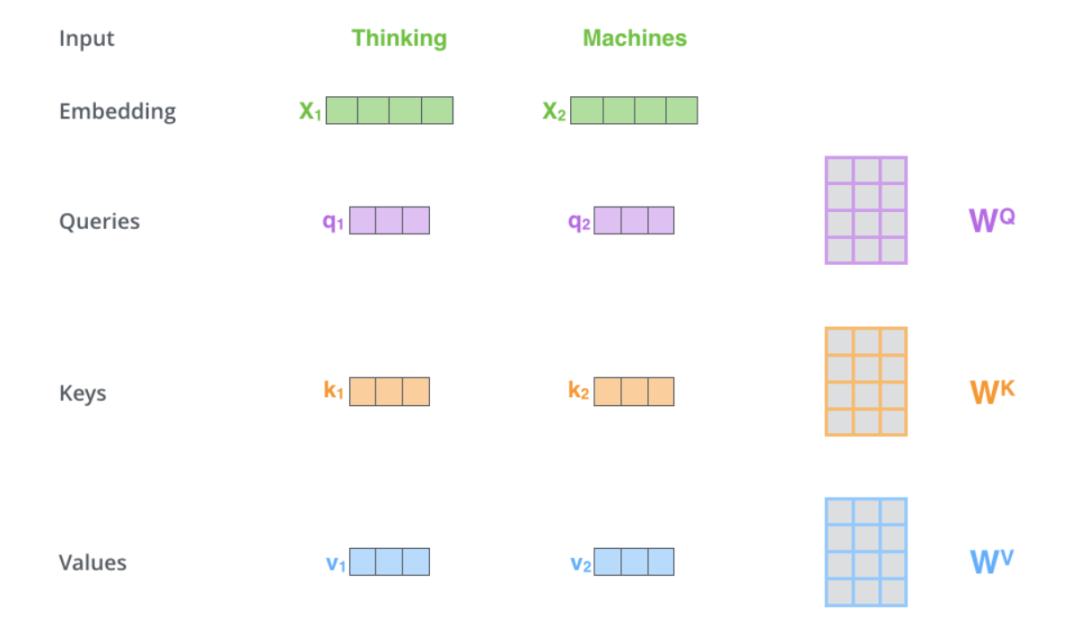
这三个向量的维度是64维。
接下来我们从第一个位置开始计算"Thinking"这个词的self-Attention,我们需要计算所有词对这个词的打分,这里的打分高低决定了在对某个位置的单词进行编码时,对输入句子中其他部分的关注度,例如之前"it"在编码时,对"The","animal"关注度较高。这里的得分计算的是两个向量的点积,例如下图计算的q1·k1和q1·k2。
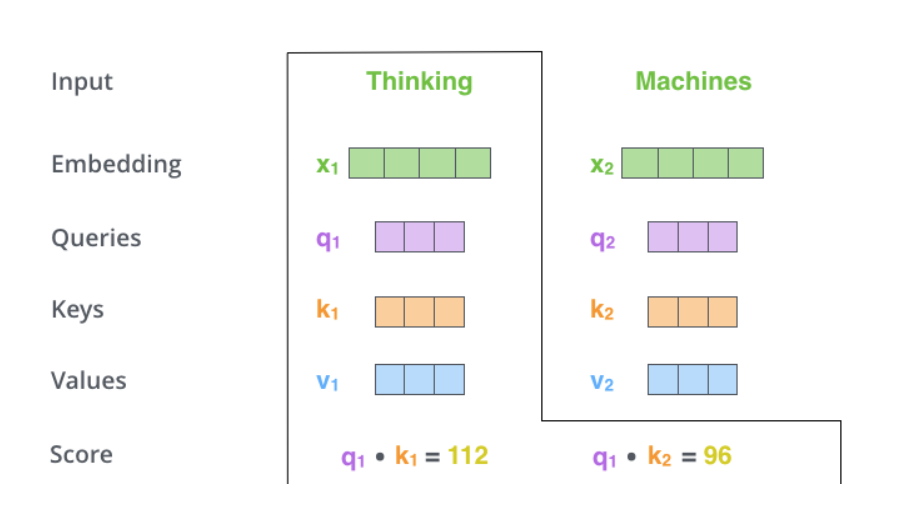
之后将点积计算结果除8,因为论文中使用的k的维度为64(8是64的平方根),然后将所有除8之后的分数通过一个softmax层,也就是归一化了,现在所有分数之和为1了。如下图所示:
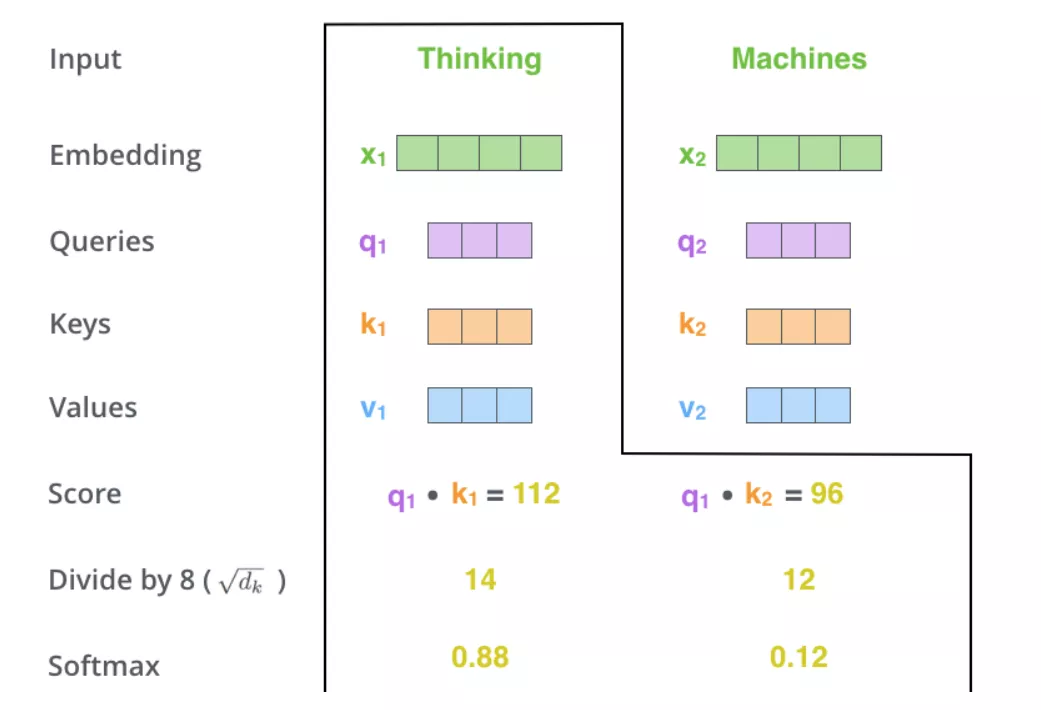
当然,肯定是当前词和当前词之间计算的分数最高,当然,我们更关注的是和当前位置词其次相关的几个词。
之后将value的向量和softmax之后的分数分别相乘,这一步是为了让和当前位置词不相关的词的value值变小(因为乘以了一个很低的分数)。

之后将这些新的value求和(向量的对应位置相加),得到了z1,也就是第一个词通过self-Attention之后的输出,对于第二个词,以此类推,输出为z2。
这就完成了self-Attention,实际上,为了加速运算,刚才所说的运算是通过矩阵运算进行的,具体如下:
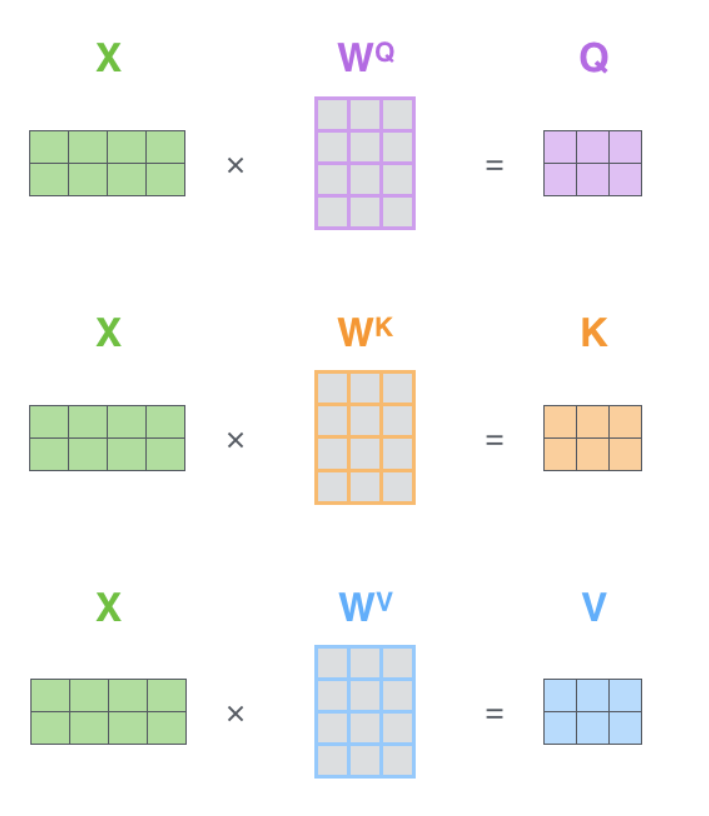
句子中的每个词对应的输入Embedding为X矩阵的一行,其他的很好理解。
我们可以把之后的很多步骤总结成下图表示:
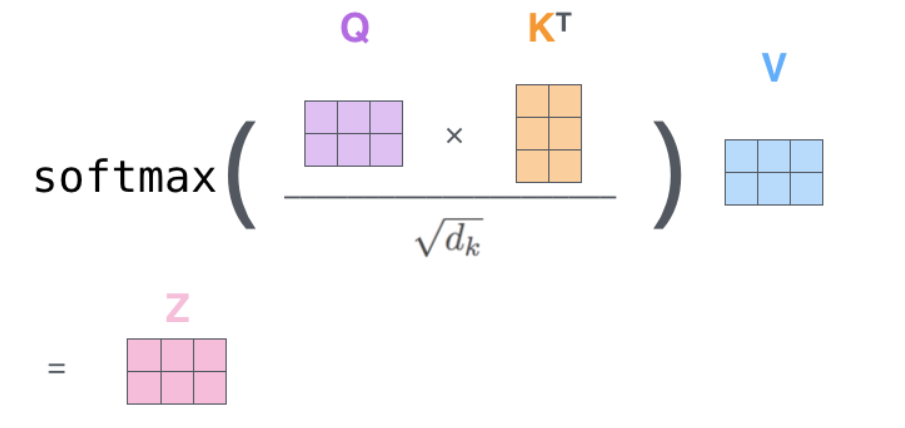
在这篇论文中,提出了一种叫做“multi-headed”的Attention,我们可以翻译为多头注意力机制。
多头注意力机制可以扩展模型对不同位置的关注度,每个头关注点不同,这个在之后举例说明。
使用多头注意力机制,每个头使用的QKV矩阵相互独立,例如下图代表2个头的情况。

所以多头和之前的只是相同的方式多计算几次,例如下图中,一共计算了8次:
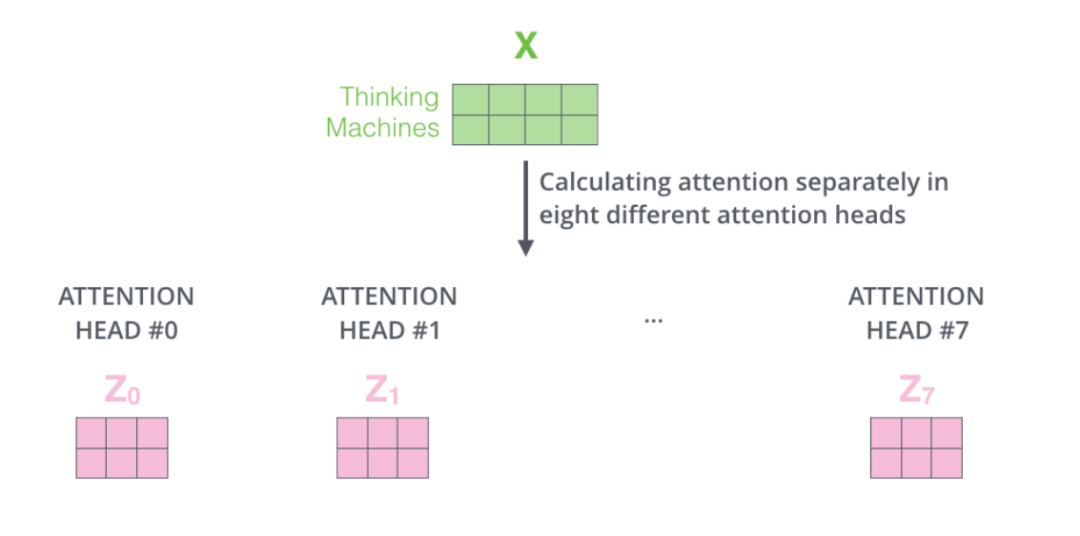
但是self-Attention层之后接的前馈神经网络层需要的不是8个矩阵输入,而是一个矩阵(每个词对应其中一个向量),这就需要我们对多头处理的结果做相应变换。
通过将8个多头输出的结果矩阵拼接起来,然后和一个和模型同时训练的矩阵Wo相乘,我们得到一个矩阵,这个矩阵包含了8个多头输出的结果,然后将这个结果矩阵作为下一层前馈神经网络的输入。
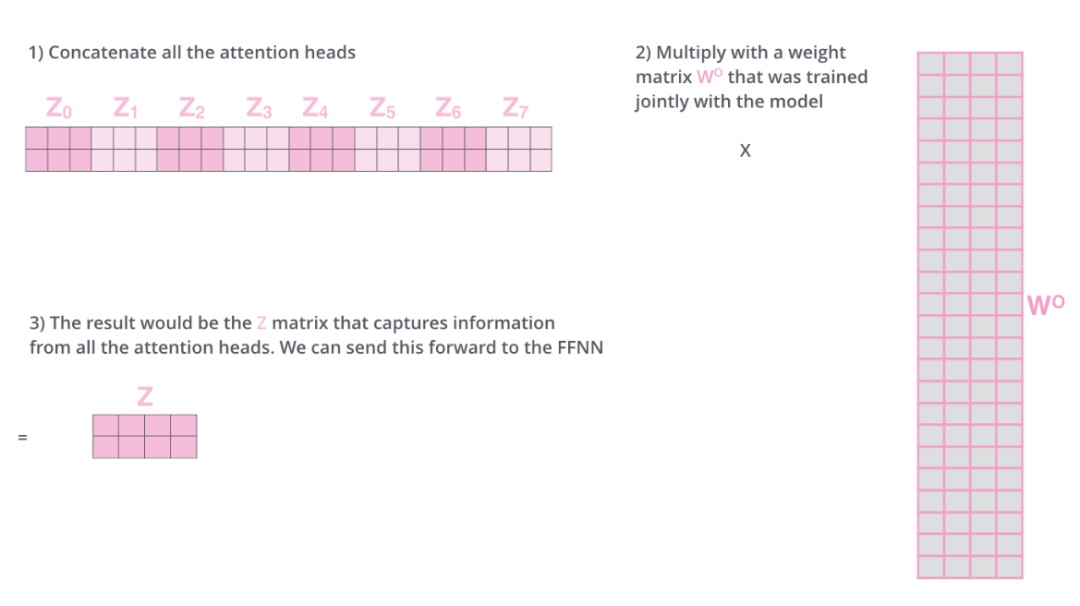
我们讲完了多头注意力机制的内容了,我们将其放在一张图上总结如下:
我们之前说到多头的好处是,每个头关注点可能不太一样,例如之前那句话,我们例举几个头关注的结果如下:
例如当对"it"进行self-Attention编码时,这个头关注的是"tire"(它累了)。
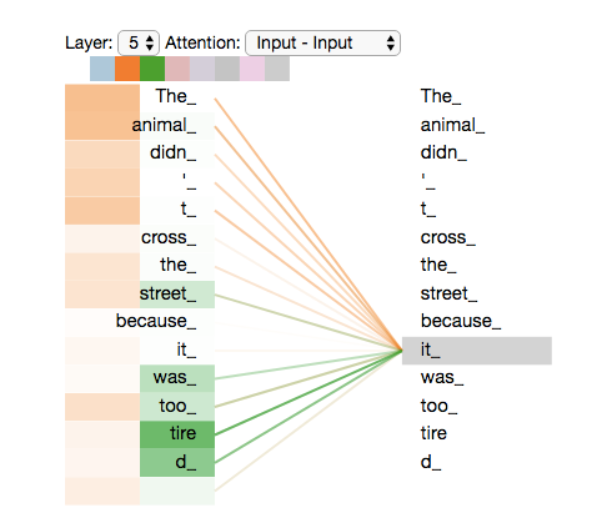
而下图表示不同的头关注点是不一样的(词的左边方块颜色深浅不一):

说完了多头注意力机制,其实还有个很重要的就是输入序列中词的顺序如何表示?
在RNN结构中,会考虑词的前后序列顺序,而在刚才提到的多头自我注意力机制中,好像这个词的顺序没体现出呢!
其实,在将词最初进行Embedding时,就加入了表示位置的相关信息,那就是词的位置向量!
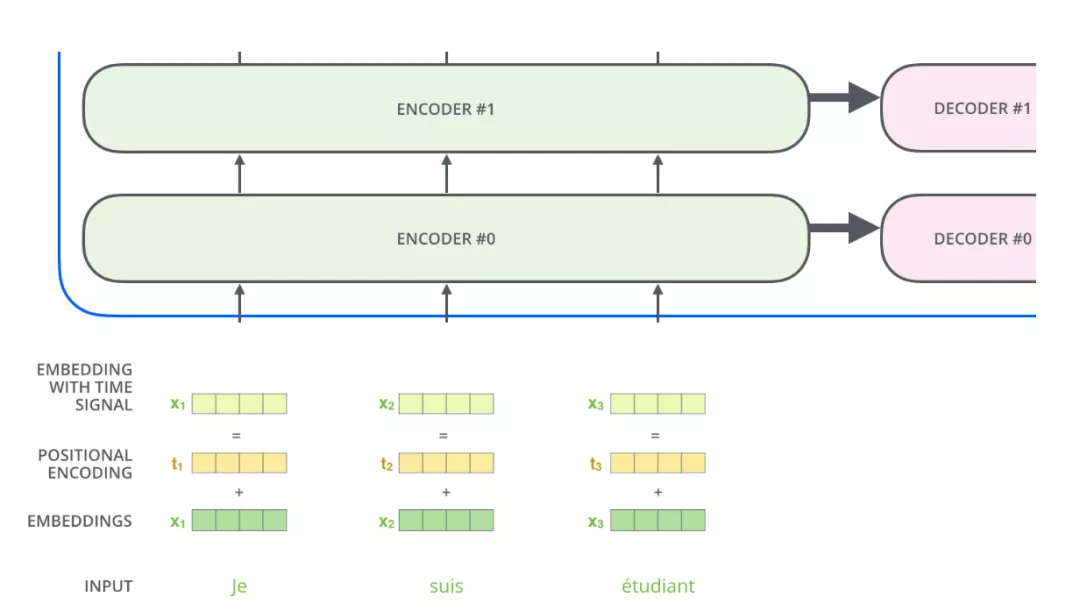
上图表示了输入词的Embedding和相应位置向量对应位置相加后得到最终的输入x1,以此类推x2,x3。
我们来看看Transformer的位置编码,Transformer没有采用RNN和CNN结构,由于Attention的出现使得Transformer中难以凸显出位置相关信息,所以引入了位置编码,公式如下:
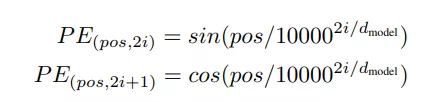
其中,PE为二维矩阵,维度和序列的Embedding一致,这样才能将两者对应相加,矩阵的行表示不同词语,列表示词向量或者位置向量,pos表示词语在句子中的位置(假设句子长度为L,则pos取值为0~L-1),dmodel表示词向量的维度,i表示词向量的某一维度,例如dmodel为512,则i的取值为0~255(因为上面公式中使用2i和2i+1分别计算奇数和偶数位置的值,在偶数词向量位置加的是sin公式求出的位置向量,在奇数词向量位置加的是cos公式求出的位置向量),所以维度为512了。
为什么要选择这样的公式作为位置编码计算使用呢?
因为三角函数满足以下公式:
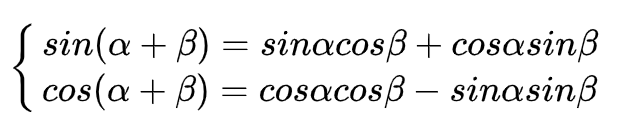
所以结合我们的具体公式,可以得到:
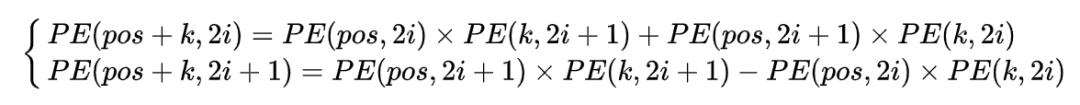
这意味着,在计算PE(pos+k, 2i),可以使用PE(pos,2i)和PE(pos,2i+1)线性表示,当在计算某个 k 和 i 给定时(就是确定了要计算某个位置的词pos+k的位置向量的某个维度上的数字i),也就是此时k,i都是确定的数。则PE(pos+k, 2i),则上面公式的右边的PE(pos,2i)和PE(pos,2i+1)的线性组合可以表示PE(pos+k,2i)和PE(pos+k,2i+1)。
以上就是位置编码的内容了,之后我们来看一下Encoder中,除了多头自注意力层和前馈神经网络层,还有个残差连接和归一化层。
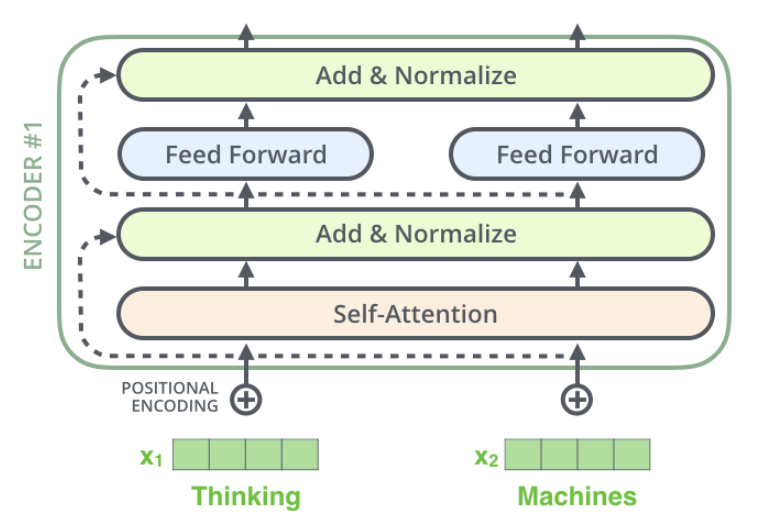
我们可以将内容细节展现出来:
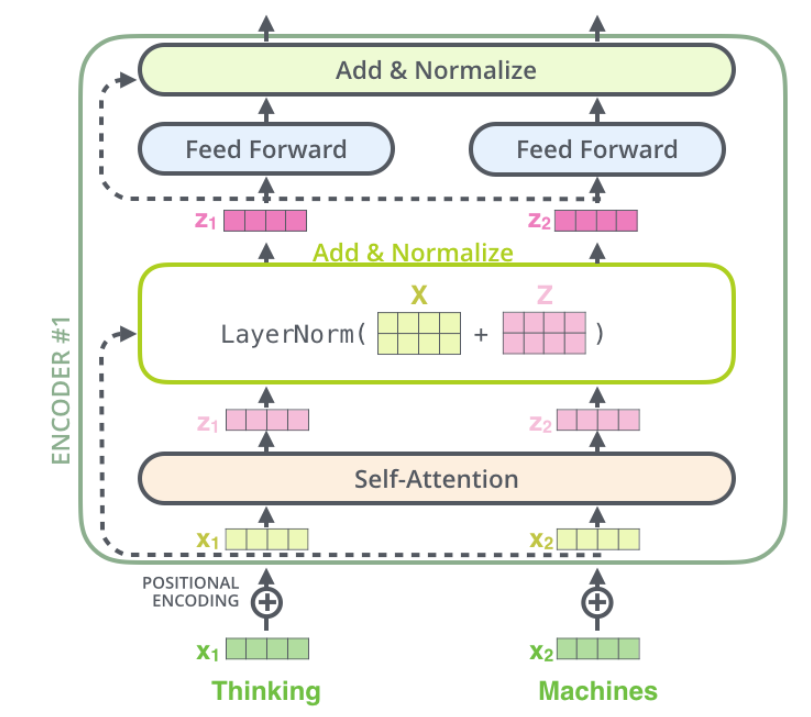
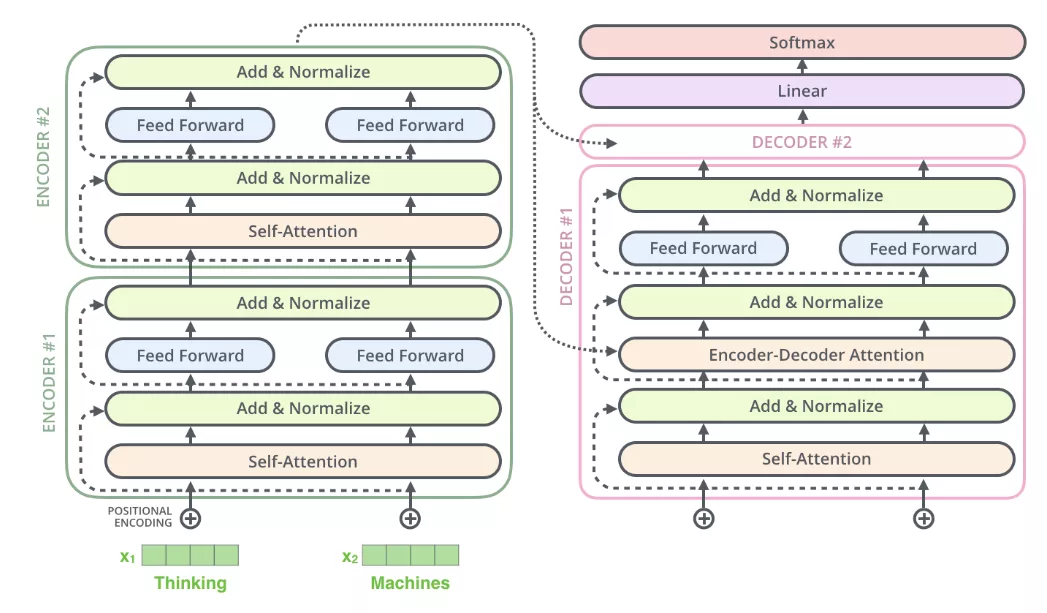
Decoder和Encoder的结构中的层基本一致,我们将Encoder和Decoder同时表示出来,如下图:
残差连接其实就是输入内容 x 和输出内容 F(x)相加得到H(x),如下如所示:
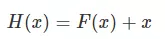

残差连接通常用于解决多层网络训练的问题,可以让网络只关注当前差异的部分。
Normalization指的是Layer Normalization,会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
接下来我们看看Decoder和Encoder如何配合工作的,
Encoder从处理输入序列开始。每个Decoder在其 "编码器-解码器注意力"层中都要使用向量K和V,帮助Decoder将注意力集中在输入序列中的适当位置。
完成编码阶段后,我们开始解码阶段。解码阶段的每一步都会从输出序列中输出一个元素(例如图中的英文翻译句子)。
接下来的步骤重复这个过程,直到达到一个特殊符号,表示解码器完成了输出。具体的过程可以以下面的图帮助理解:
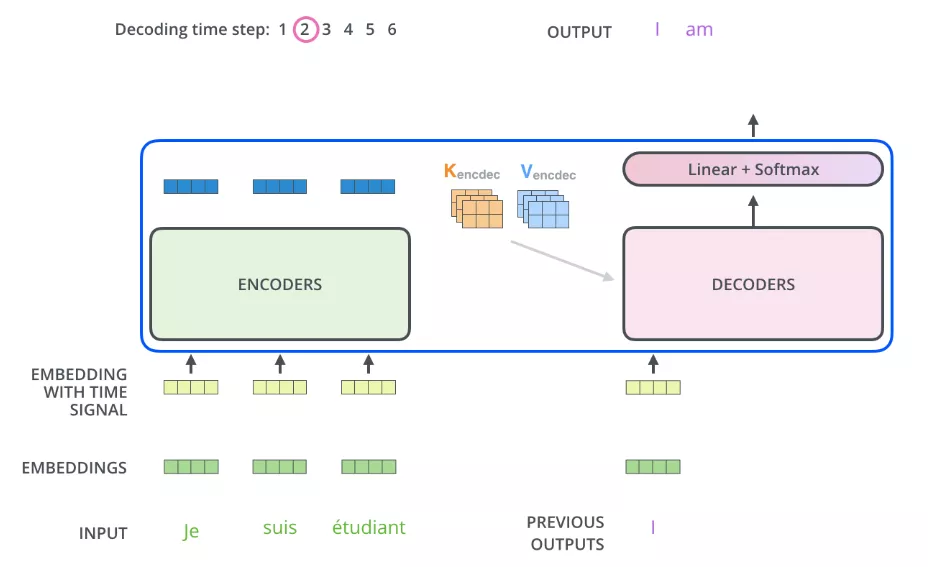
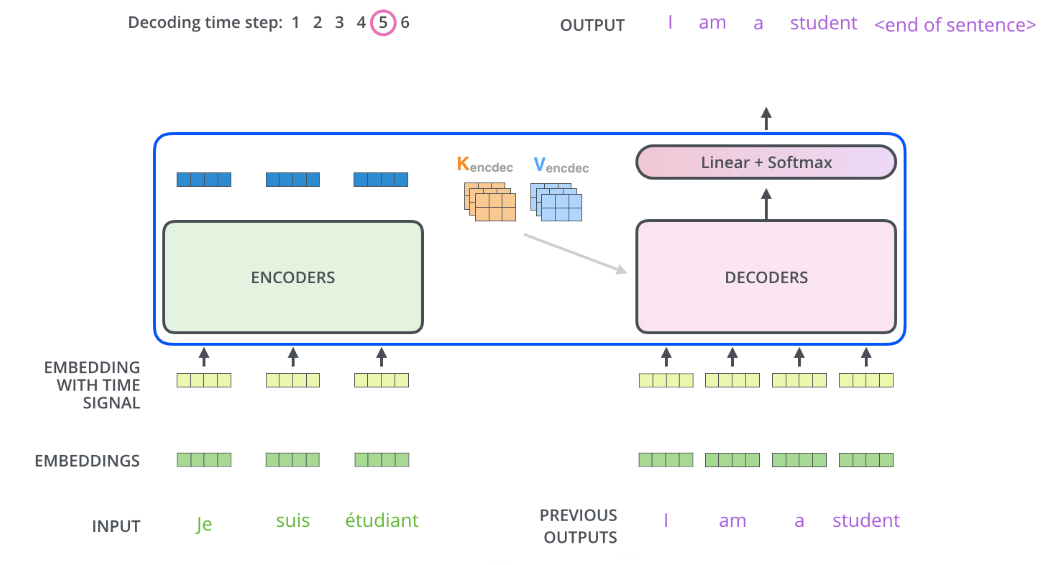
需要注意的是,解码器中的self-Attention的工作方式与编码器中的self-Attention层略有不同。
在解码器中,self-Attention只允许关注输出序列中的已输出部分内容。
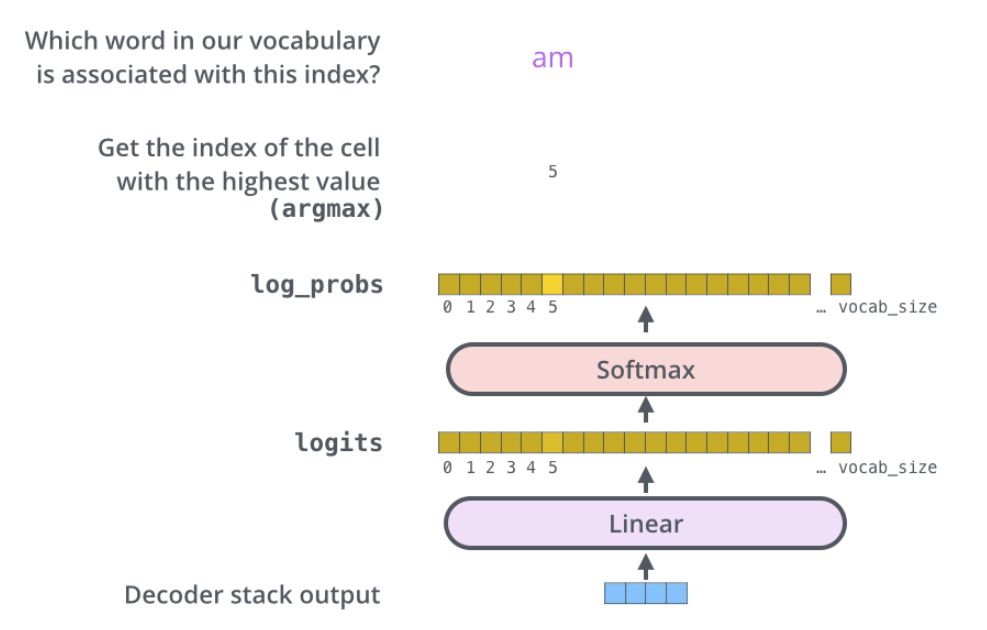
在最终输出位置输出的是一个个字符(这里是翻译的单词),那如何将向量转为输出的字符呢?我们再次看一下论文中的Transformer的结构,发现最终接的是Linear和Softmax层。

其中,Linear层是一个全连接的神经网络,输出也是一个向量,假设我们有100000种单词,那么Linear层的输出就是长度为100000的向量,然后通过softmax输出该次输出的每个单词得分,然后选出分数最高的词作为输出,如下图所示:
Transformer 模型使用了 Self-Attention 机制,不采用 RNN 的顺序结构,使得模型可以并行化训练,而且能够拥有全局信息。
面试被问到的这些问题,相信大家看完本文心里都有答案了!
Transformer 和 加入Attention的 RNN Encoder-Decoder相比,有什么优势?
Transformer中的多头注意力机制是什么?具体细节是?
Transformer中的位置编码是如何实现的,采用的编码有什么优点?
Transformer中的残差连接作用是什么?
参考文献:
1. https://arxiv.org/pdf/1706.03762.pdf
2. http://jalammar.github.io/illustrated-transformer/
扫码下图关注我们不会让你失望!
