得到因子得分并不是最终的结果,降维是为了使我们的思路更加集中,但降维结束后得到的却未必是我们所期望的。为了更好的加以分析,我们可以在降维因子分析的基础上对得到的潜在因子进行聚类或者计算出综合因子得分进行排序。
【数据】:美国洛杉矶 12 个地区的调查数据(人口、校龄、总雇员、房价、服务),该数据来自卢文岱老师的书里data12-01。
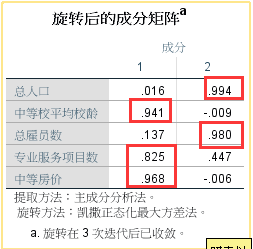
【案例说明】:12 个地区的 5 个调查指标数据经过因子分析处理后,找到两个潜在的因子:人口因子和福利因子。并且 PS 自动保存了 12 个地区的因子得分。这个案例的目的在于评价 12 个地区经济情况。我们现在走一条曲线救国的思路:利用人口因子和福利因子两个变量进行聚类,看看这 12 个地区有哪些是相似的(同一类),这些相似的地区有哪些特征,从而集中评价属于同一类的某几个或一个地区。
一、操作
(1)因子 1,因子 2 为参与聚类的变量,地区编号为标示。
(2)盲聚类,先给定范围 2-4 类,然后对 2、3、4 进行比较,最终确定聚为几类。
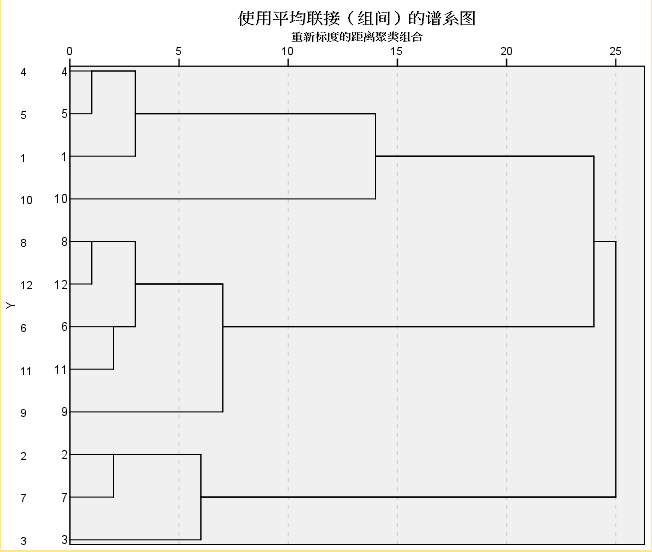
(3)个人较喜欢输出树状图,要求输出聚类的树状图。采用欧氏距离平方聚类。
(4)不需要进行标准化处理,因为两个因子本身就是无量纲变量。
二、重要结果对比
因子分析结果:
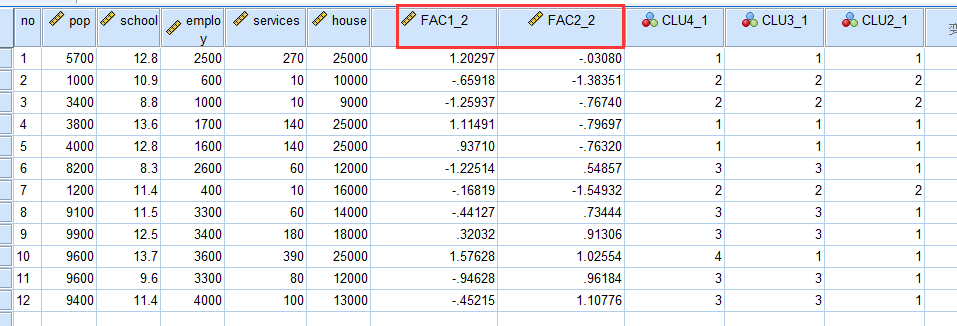
接下来用两个因子进行聚类分析:分析——分类——系统聚类
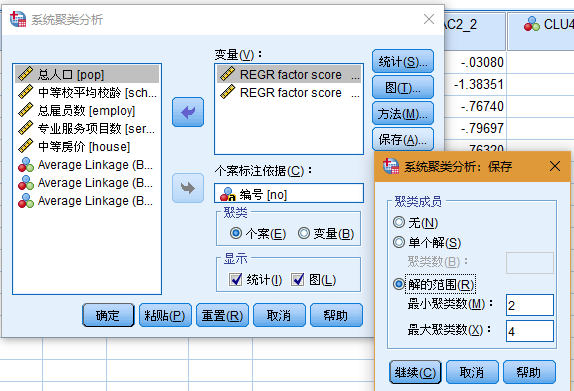
2.因子得分——类别散点图(可视化效果如下)
做法:因子得分 2 为纵轴、因子得分 1 为横轴,用地区编号标识地区,用聚类得到的各地区类别号分组。(依次做分为 2 类的、3 类的、4 类的散点图进行比较)。
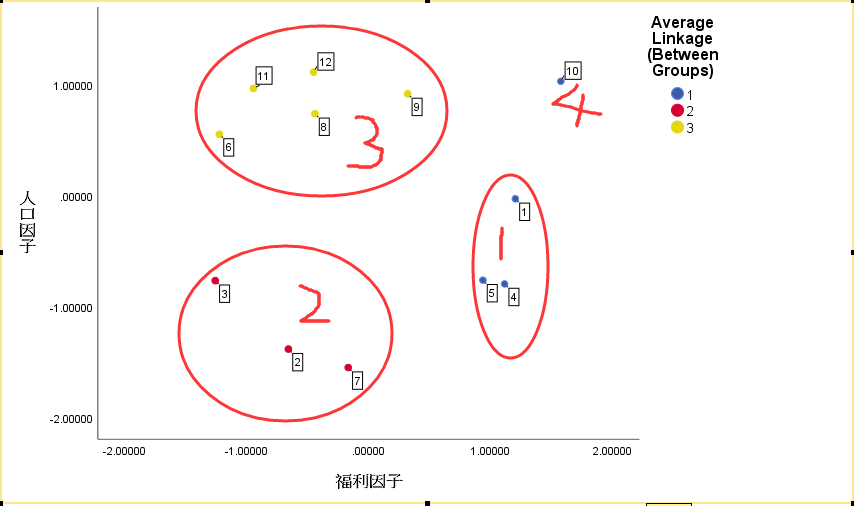
上图显示,2、3、7 为第二类,处在人口因子和福利因子都较低的左角,可以认为从 5 个经济指标来看均较差的地区;
1、4、5 为第一类,人口因子(人口数和就业人数)得分较低,福利因子较高,即人口和就业者较少,但福利条件去很不错的地区群(这可是梦寐以求的好地方啊!);6、8、9、11、12 为第三类人口因子较高,福利因子较低,人口多,就业者多,比如 hn,人口第一大省,但整体经济实力较东部地区差,福利跟不上。
分析讨论:
就此案例而言,最终聚为几类合适?思路:从上面的散点图可以看出,编号为 10 的这个地区,偏离 1、5、4 地区较远,聚类过程显示这四个地区为同一类。鉴于 1、5、4 更集中,10 地区较远,用异常值的思想来讲,10 地区为异常值,单独放一边讨论,视为特例对待。其他 11 个地区分为 3 类。即最终聚为 4 类(或 3 类+1 特例)。
从这个案例可以看出,我们很有必要在PS既得结果中提取其他可视化图形,比如上面这个因子得分散点图,使分析效果更加显著。
转自:www.datasoldier.net
