聚类分析在各行各业应用十分常见,而顾客细分是其最常见的分析需求,顾客细分总是和聚类分析挂在一起。顾客细分,关键问题是找出顾客的特征,一般可从顾客自然特征和消费行为入手,在大型统计分析工具出现之前,主要是通过两种方式进行“分群别类”,第一种,用单一变量进行划段分组,比如,以消费频率变量细分,即将该变量划分为几个段,高频客户、中频客户、低频客户,这样的状况;第二种,用多个变量交叉分组,比如用性别和收入两个变量,进行交叉细分。事实是,我们总是希望考虑多方面特征进行聚类,这样基于多方面综合特征的客户细分比单个特征的细分更有意义,这正是 spss 聚类分析可以做到的。
数据:
《SPSS 统计分析高级教程》telco.sav,是反映移动电话用户使用手机情况的数据集。包含 7 个变量:用户编号、工作日上班时间电话时长、工作日下班时间电话时长、周末电话时长、国际电话时长、总通话时长、平均每次通话时长,现希望对移动用户细分,了解他们不同的手机消费习惯。根据研究调研及经验,认为移动用户应分为 5 个主要消费群体。数据分析工具:PS IMAGO PRO,参考教程:张文彤,《 SPSS12 统计分析高级教程》。

目标:对移动用户进行细分,了解不同用户群体的消费习惯。
分析方法:样本量较大,适合采用K均值聚类(快速聚类)
数据说明:此数据集各变量均为数值型,均为时间单位,但各变量取值跨度较大,因此在分析之前需要对数据标准化处理,而PS IMAGO的K均值过程未提供自动标准化,(二阶聚类和系统聚类都有提供标准化)因此,需要手动通过描述统计过程完成。
变量的描述统计分析:
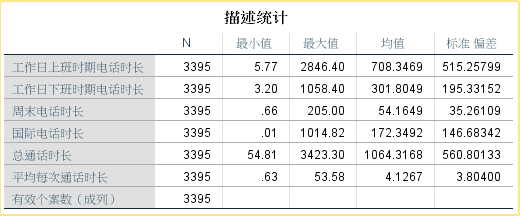
数据预处理:
对于数据集中变量的分布、缺失、描述统计指标进行一定程度的分析。(缺失值、离群值、异常值、极值)
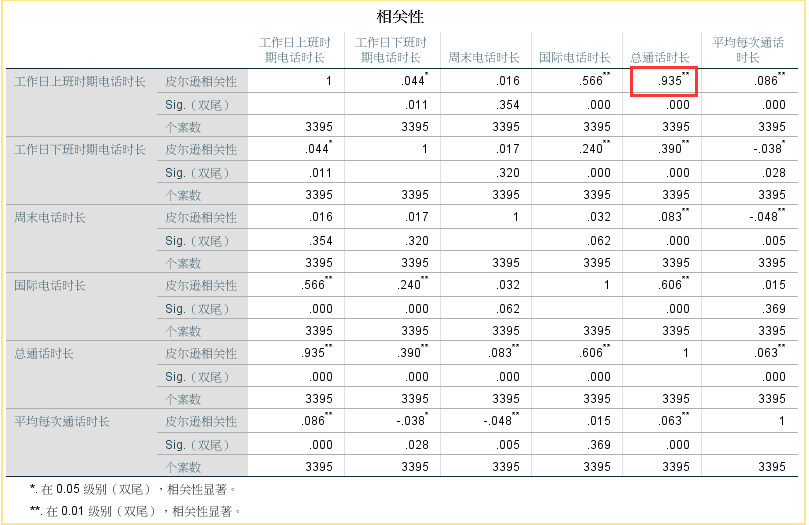
K-means聚类,纳入的聚类变量一般为数值型变量,聚类变量间不应有较强的线性相关关系,如果变量间存在较高的线性关系,能够相互替代,那么计算距离时这些变量将重复贡献,一定程度上影响到最终的聚类结果。如图所示,工作日上班时间电话时长和总通话时长可能存在线性关系,相关系数为: 0.935,对聚类结果有一-定的影响。可考虑将这两个变量衍生出另外一个新的变量。采用工作日上班时间电话时长/总通话时长替代。
数据分析:
方法选择: k ——means聚类
聚类变量:根据当前数据集实际情况,选择如下6个变量作为本次的聚类变量:
上班电话时长/总通话时长 、下班时间电话时长 、 周末电话通话时长 、 国际电话通话时长 、 总通话时长、 平均每次通话时长;
有效样本: 3395,各变量无缺失值
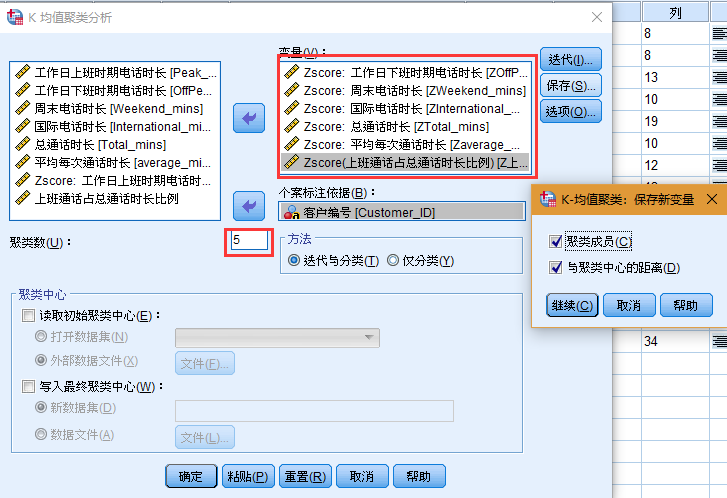
实现k-means聚类过程的具体操作如下:分析——分类——k均值聚类
变量框:以上6个标准化后的变量
个案标记依据:客户编号 聚类数: 5 迭代卡:最大迭代次数80
保存卡:聚类成员、与聚类中心的距离 选项卡:初始聚类中心、方差表
聚类结果:
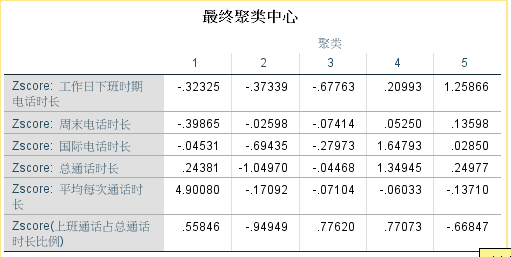
最终类中心,重要结果是各个类的均值,如果最终聚类可接受,则这个类中心可保留,用于以后聚类。
方差分析,按照类别分组进行单因素方差分析,可根据F值大小近似得到哪些变量对聚类有贡献,如下图所示,重要程度排序为:上班通话时长/总通话时长>总通话时长>国际通话时长>下班电话时长>平均每次通话时长>周末通话时长。同时,各变量对聚类均有显著地贡献。
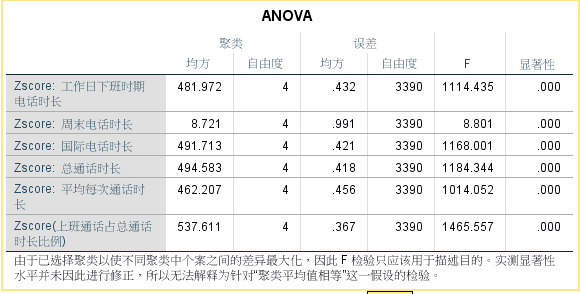
各类别记录数量:
各类别特征描述:分析——比较均值——平均值(因变量:6个变量加占比 自变量:类别)

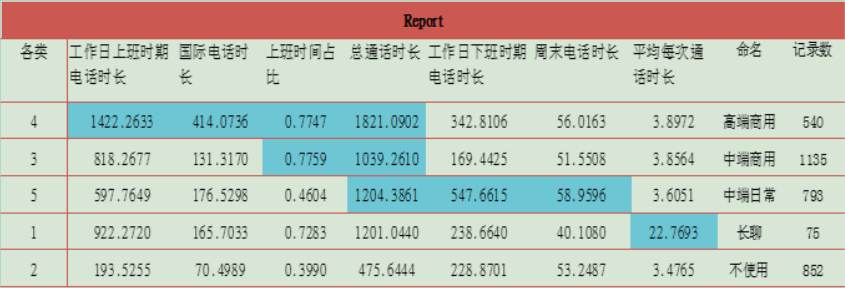
类命名,对均值比较表格适当调整,如上表所示:
4类:总通话时间长,上班通话占比高,国际通话最长等特征,命名为高端商用客户。
3类:总通话居中,上榜通话占比最高,命名中端商用客户。
5类:总通话居中,下班通话最长,周末通话最长,命名中端日常客户。
1类:最大特征,平均每次通话时长最长,命名长聊客户。
2类:在各项中均较低,命名不常使用客户。
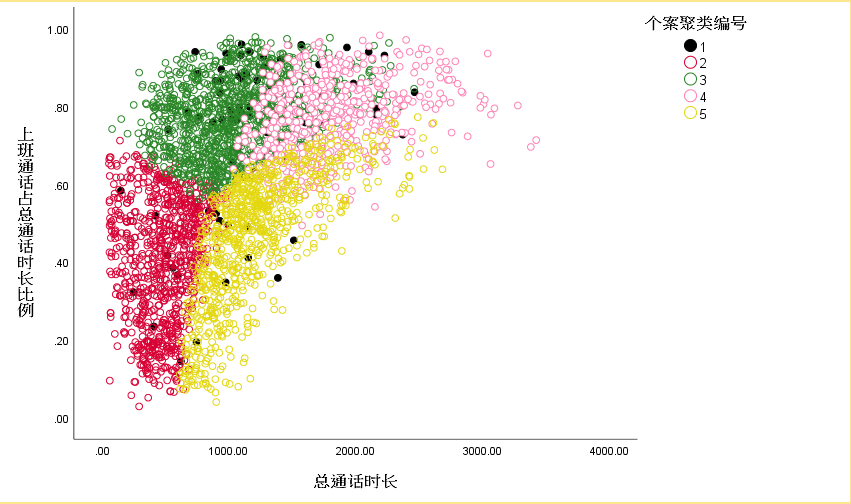
进一步:通过绘制散点图展示
4类:总通话时间长,上班通话占比高,国 际通话最长等特征,命名为高端商用客户。
3类,总通话居中,上班通话占比最高,命名中端商用客户。
5类,总通话居中,下班通话最长,周末通话最长,命名中端日常客户。
1类,最大特征,平均每次通话时长最长,命名长聊客户。
2类,在各项中均较低,命名不常使用客户。
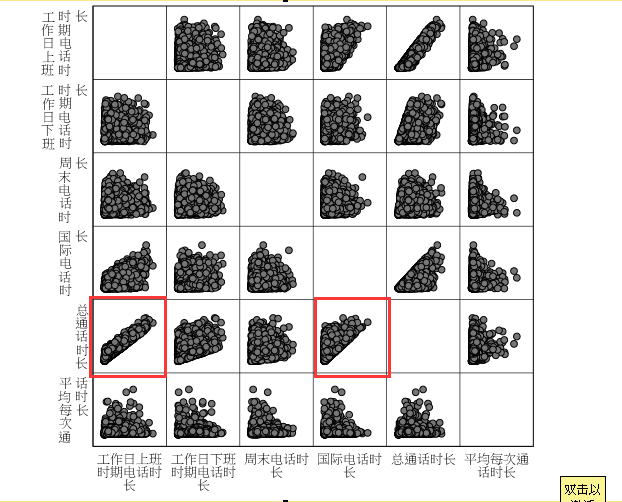
选择对聚类贡献较大的前两个聚类变量做散点图,我们通过可视化的图形可以发现聚类的效果较为明显,而且非常符合真实情况,分类效果较好。
数据分析——结论

经过预处理分析,k-means聚类分析,最终基本实现了分析的目的,较为成功的对某移动电话客户进行了细分,初步了解了各类型用户的手机话费消费习惯,对日后经营有一定的指导意义。
该移动营运商,可参考不同类型用户群体的手机话费消费习惯提出有针对性的话费服务,使经营目标达到最优。
4类: 总通话时间长,上班通话占比高, 国际通话最长等特征,命名为高端商用客户。
3类:总通话居中,上榜通话占比最高,命名中端商用客户。
5类:总通话居中,下班通话最长,周末通话最长,命名中端日常客户。
1类:最大特征,平均每次通话时长最长,命名长聊客户。
2类:在各项中均较低,命名不常使用客户。
转自:www.datasoldier.net
