基础准备
前面我们介绍了logistic回归分析的原理以及如何运用SPSS软件实现二元逻辑回归分析的操作过程,以及哑变量(虚拟变量)的设置方法:
面对操作窗口中的条条框框、眼花缭乱的按钮和选项,我可以浮光掠影的介绍,但是我相信很多学习者会消化不良。因此,我们需要细嚼慢咽,一篇一篇的慢慢介绍。在上面的文章结果中,出现了很多模型和自变量的筛选检验方式,今天我们对这些自变量筛选和检验方法进行详细的介绍。
极大似然与最小二乘
在介绍检验方法之前,两种回归参数的估计方式是绕不过去的知识点。下面我举个生活中的例子来介绍它们的联系与区别。
张大胆和李含蓄是非常要好的邻居小伙伴,平时张大胆总是做一些用开水浇花的调皮事,而李含蓄因为内敛乖巧颇受周边邻居大人的好评。某天,两人在小区空地踢球,突然把陈阿姨家的玻璃砸碎了,陈大姨气势汹汹的冲出来,看见是张大胆和李含蓄在踢球,便问是谁打碎了玻璃,谁也不承认是自己打碎的,陈大姨此时认定是张大胆干的。陈阿姨的这种做法就是极大似然法:根据以往张大胆和李含蓄的行为表现,张大胆做这件事情的概率更大,在没有证据证明是谁干的前提下,张阿姨只能推断最有可能做这件事情的张大胆为“凶手”。可见极大似然法是与最小二乘法完全不同的回归方程拟合方法。
我们再回顾一下最小二乘法以及它的模型检验方法。因变量是连续变量的回归模型,我们拟合回归方程,通常采用的是最小二乘法。最小二乘法很好理解,如下面两幅图,它的原理就是让回归线尽量的沿着数据点的趋势走,标准就是实际值减去预测值的误差平方和最小。因此这些最小二乘回归方程的检验方式只需围绕误差平方和进行,使用F检验就能解决模型效果检验,自变量筛选等等需求。
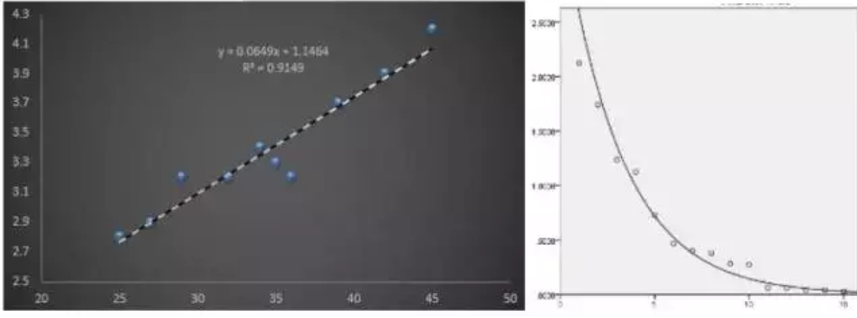
如果回归方程是通过极大似然法估计得到的,过往使用于最小二乘法回归方程检验的F检验和t检验就不在适用了,而应该用极大似然法的三种检验方法:沃尔德检验(Wald)、似然比检验(LR)和比分检验(Score)。
三种检验方法
与最小二乘法回归方程的检验方法t检验和F检验一样,极大似然的三种检验方法由于原理不同,它们的用处也会不同。在最小二乘的检验方法中,t检验是对回归系数进行检验的,判断回归系数与0是否有显著性差异,有显著性差异,说明该回归系数对应的自变量确实会影响因变量;而F检验是围绕真实值与预测值的残差平方和写文章的,如果回归方程能够解释因变量数值的大量变异,那么说明该回归方程是有效的,从而间接说明回归方程中的自变量至少有一个是会影响因变量的。与t检验和F检验相同的,wald检验、似然比检验和比分检验它们的特点也有很大的不同。
比分检验(Score Test):比分检验以不完全模型为基础,不完全模型指回归模型中包含的自变量并非所有的自变量。当将模型外的自变量引入不完全模型时,比分检验会考察该自变量与原来的不完全模型的相关关系,如果检验概率值小于0.05,那么可以认为该自变量是适合进入不完全模型的。从上面的解释可以看出,比分检验主要用于自变量进入模型前的筛选。
似然比检验(LR Test):逻辑回归方程是通过极大似然法获得的,所以每个回归方程都会对应一个似然函数的极大似然值,极大似然值其实就是概率,它的取值范围在0~1之间,极大似然值与最小平方和一样,都能够代表回归模型的质量。似然比检验的原理就是通过极大似然值之间的比较,看两个模型的拟合质量是否有不同。
沃尔德检验(Wald检验):沃尔德检验是对已经在回归模型中的回归系数做是否等于0的假设检验,主要用于检查是否应该剔除已经在回归模型中的自变量。在回归模型的结果输出中,关于回归系数的所有检验都是进行沃尔德检验的。
上述三种假设检验中,比分检验和似然比检验都是基于整个模型的拟合情况进行的,结果比较可靠,两者的检验结果一般情况下都是一致的,而沃尔德检验是对每个自变量的回归系数做独立的检验,当因素间存在共线性时,结果就会不可靠。根据它们的特点,SPSS软件在使用它们时是分阶段的,比分检验用于自变量进入模型前的筛选;似然比检验用于不同回归模型效果的检验;沃尔德检验用于模型建立后,回归系数检验以及回归系数置信区间的建立。
自变量的筛选方法
SPSS在二元逻辑回归中提供了7种自变量的筛选方法,分别是输入、向前三种和向后三种。输入就是不考虑自变量筛选,统统纳入到模型。向前筛选也就是逐步回归,自变量是逐个进入模型的,同时,每选入一个自变量进入模型,还会对上一步进入模型的自变量进行再次检验。向后法的过程则正好相反,它先将所有的模型一次性纳入回归模型,然后再逐个剔除,剔除出模型的自变量不再考虑引入模型。因此,向前法比向后法更加严谨。
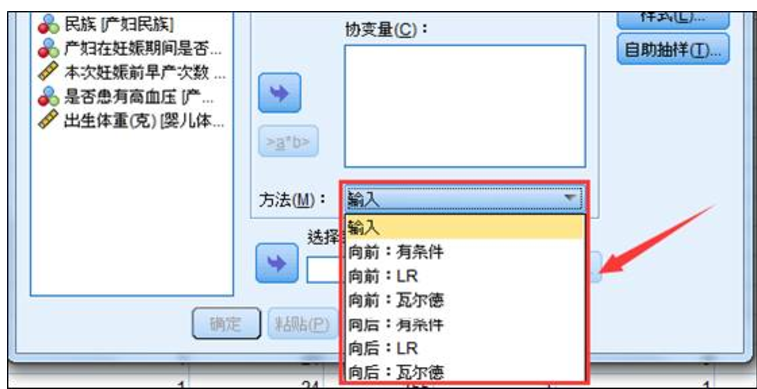
这六种自变量的筛选方式的具体含义:
向前:有条件。选入自变量时基于比分检验结果,移去自变量是基于在条件参数估计基础上的似然比统计的概率结果。这里的条件参数估计指的是回归方程的参数由贝叶斯参数估计得来,然后再求得不同回归方程的似然比。
向前:LR。选入自变量时基于比分检验结果,移去检验是基于在最大局部似然估计的似然比统计的概率结果。这里的回归方程参数是通过极大似然法估计得到的。
向前:Wald。选入自变量是基于得分统计的显著性,移去自变量的检验是基于 Wald 统计的概率结果。
向后:有条件。首先将所有自变量纳入模型,然后在对自变量进行逐个剔除。剔除自变量的标准是基于条件参数估计的似然比统计的概率结果。
向后:似然比。首先将所有自变量纳入模型,然后在对自变量进行逐个剔除。剔除自变量的标准是基于在最大偏似然估计基础上的似然比统计的概率结果。
向后: Wald。 首先将所有自变量纳入模型,然后在对自变量进行逐个剔除。剔除自变量的标准是基于 Wald 统计的概率结果。
向前和向后的三种自变量筛选方法,在样本量很大的情况下,它们拟合的回归方程结果基本上是相同的。不过相对来说有条件和LR的拟合结果更为灵敏,因为它们是针对整个回归模型进行的假设检验,而Wald是针对每个回归参数进行的检验,所以在有些情况下容易犯错例如共线性的情况下。
向前和向后的拟合结果经常会出现完全不同的情况,这是由于它们筛选自变量的过程不同造成的。向前法属于谨小慎微型,需要先挑选自变量,然后再纳入模型;而向后法则不同,它先一咕噜脑儿的将自变量纳入模型,然后再往外剔除。相对来说向后法损失的信息会比向前法来得少,所以探索性研究多用向后。不过拟合结果的好坏还是可以用最终的拟合结果来判断的,大家可以将所有筛选方法都进行尝试,用拟合结果来选择最优的方法。
案例分析
沿用上面的例子,某医学研究机构研究孕妇分娩低体重婴儿的原因,根据经验,研究机构初步筛选以下变量纳入分析,包括产妇生产前体重;产妇年龄;产妇是否吸烟;产妇之前早产次数;产妇是否患有高血压;产妇民族;部分数据如下:
分析思路
因为这篇文章介绍的是自变量的六种筛选方法。下面我们分别对上面的数据进行六种方法的对比,来看看它们之间最终的拟合结果如何,并初步判断那种方法拟合效果较好。该案例中,以低出生体重儿作为因变量,以产妇年龄、产妇体重、早产次数、产妇是否吸烟、产妇是否高血压、产妇民族作为自变量。其中产妇民族是三分类数据,需要设置哑变量,做到测量尺度同一。
分析步骤
1、选择菜单【分析】-【回归】-【二元Logistic】,是否生产低体重婴儿选为因变量,产妇年龄、产妇体重、早产次数、产妇是否吸烟、产妇是否高血压、产妇民族作为自变量。
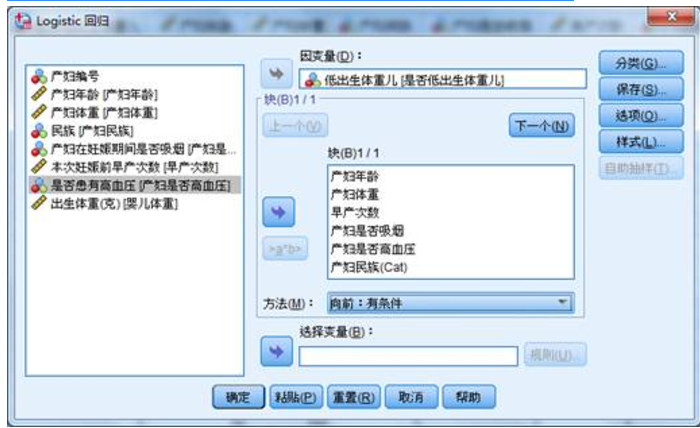
2、然后点击分类按钮,将产妇民族选入分类协变量。在下方的更改对比中,我们保持指示符。哑变量的设置内容可以回顾:SPSS分析技术:二元Logistic回归中哑变量的设置;哑变量的“哑”就是哑巴吃黄连的“哑”!
3、自变量的筛选方法。为了对六种方法的拟合结果做出对比,我们分别对每一种方法进行一次拟合计算,然后对比它们的拟合结果。
结果解释
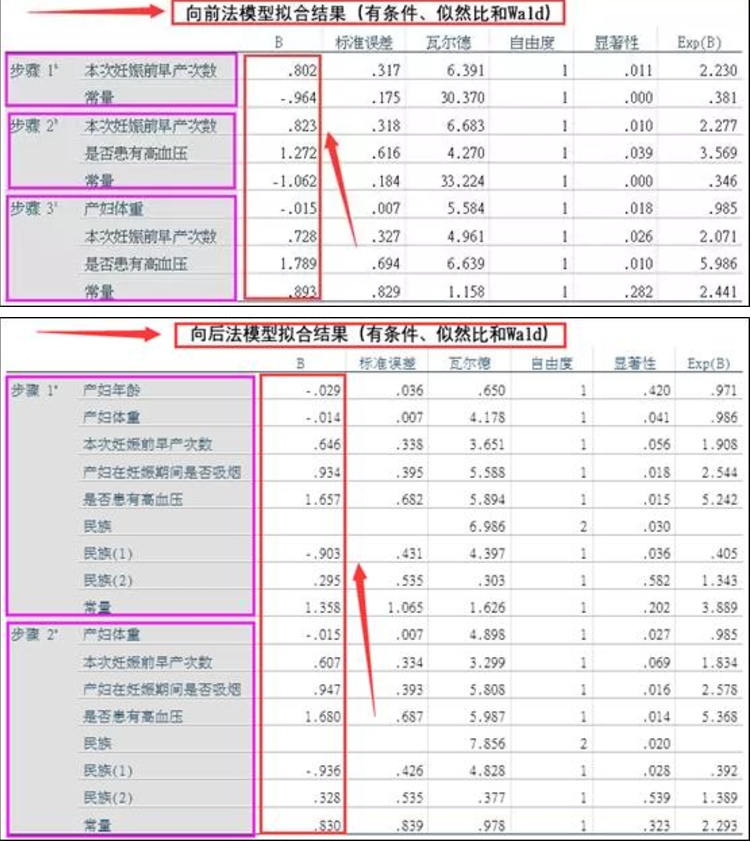
1、最终的结果可以发现,三种向前的自变量筛选方法,它们最终的模型拟合结果都是一致的;同样的,三种向后的自变量筛选方法,它们的模型拟合结果也是一致的。但是,向前和向后的模型拟合结果却完全不同,向前法最终的拟合模型包含3个自变量:产妇体重、早产次数以及是否高血压,而向后法最终的拟合模型包含除体重以外的所有自变量。
2、最终模型的拟合效果
逻辑回归模型的效果评价方法有很多,每种方法的介绍会在下面一片文章中具体介绍,今天我们先用最直观的模型评价方法来对向前和向后两种方法的模型效果进行比较。比较方法我们采用模型结果分类表。
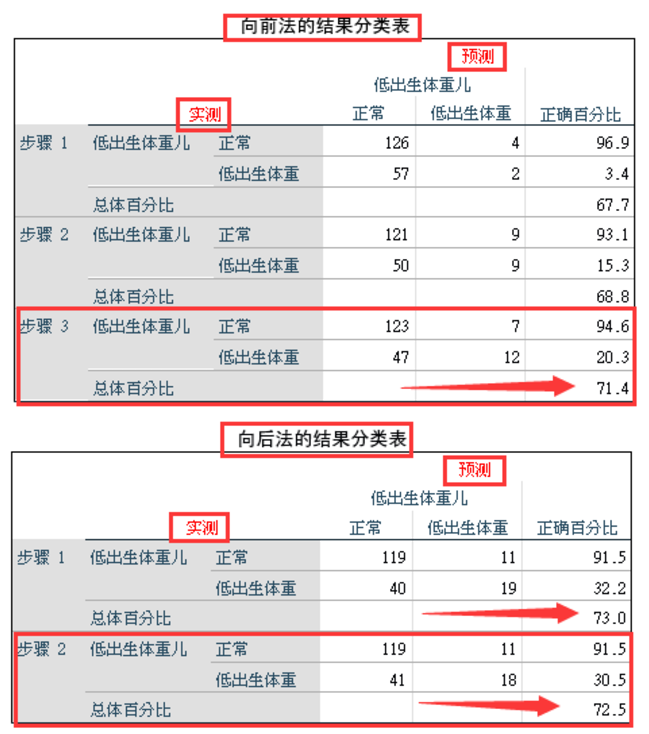
从向前法和向后法模型拟合结果的预测准确率来看,向后法的综合准确率会更高一些。更为有意思的是,向后法的模型1(包括产妇年龄)比模型2(剔除产妇年龄)的准确率还高0.5%。但是从整体来看,无论向前还是向后,模型效果都不是非常的理想,下一步可以考虑加大样本量,纳入其它自变量,提高模型的预测效果。

