在数据可视化中,如果数据是三维或者不多于六维的话,那么星图就是反映数据分布得最佳图像。R的基础包里面提供了绘制星图的函数——stars()函数。每一个星图都是由五个角构成,用线段离中心的长度来表示变量值的大小,用于展示多个变量的个体,每个变量的图形相互独立,即每个角都有一条轴线与中心点连接起来这五条轴线,它们分别对应了数据的维度,数值越大,轴线越长,画出来的星图也就越大,因此说如果数据维度不超过六维的适合用星图来分析。由于星图整幅图形看起来像星星一样,因此称之为星图。
首先我们来看看stars()函数的原型:
stars(x, full = TRUE, scale = TRUE, radius = TRUE,
labels = dimnames(x)[[1]], locations = NULL,
nrow = NULL, ncol = NULL, len = 1,
key.loc = NULL, key.labels = dimnames(x)[[2]],
key.xpd = TRUE,
xlim = NULL, ylim = NULL, flip.labels = NULL,
draw.segments = FALSE,
col.segments = 1:n.seg, col.stars = NA, col.lines = NA,
axes = FALSE, frame.plot = axes,
main = NULL, sub = NULL, xlab = "", ylab = "",
cex = 0.8, lwd = 0.25, lty = par("lty"), xpd = FALSE,
mar = pmin(par("mar"),
1.1+ c(2*axes+ (xlab != ""),
2*axes+ (ylab != ""), 1, 0)),
add = FALSE, plot = TRUE, ...)
下表则是对这些参数的大致说明:
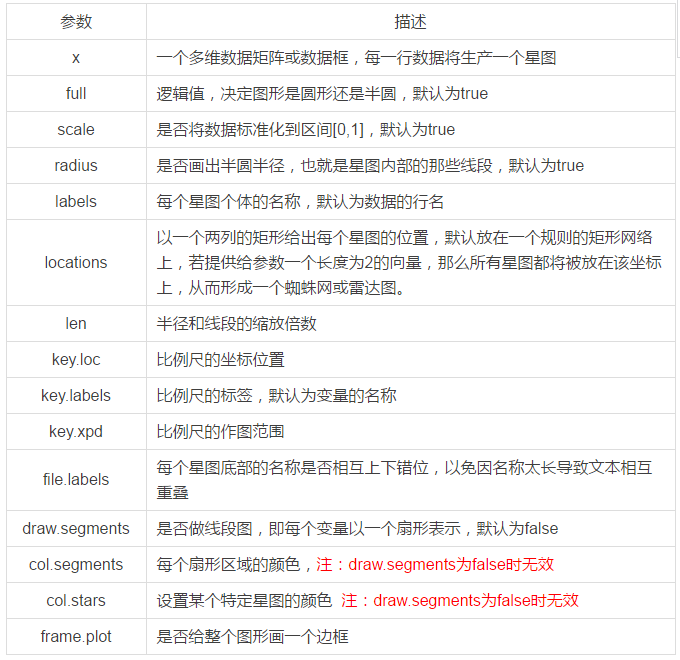
我们使用的数据集是iris数据集。现在开始我们的第一个星图吧。
stars(iris)

如果我们不需要星图内部的那些小线段的话,那就设置radius为FALSE.
stars(iris,radius=FALSE)

如果说我们只需要显示每个星图的一半,只需要将参数full设置为FALSE.
stars(iris,full=FALSE)

如果我们需要显示每一个变量的话就要提供labels参数,它默认为空。通过head(iris)查看到iris数据集每行变量名为第五列。
head(iris)
x<-iris[,5]#此时的x为factor,我们需要将它转为character类型
x<-as.character(x)
class(x)#检查数据类型是否转换成功
stars(iris,labels=x)#画图

但我们发现这个排版特别乱,变量名和星图之间相互重叠。这个时候我们就需要flip.labels参数设置为FALSE即可。
stars(iris,labels=x,flip.labels=FALSE)

这张图的话就是底下几行的变量名字太长重合了,我们可以win.graph()函数,它可以设置图像面板的大小,也可以设置字体大小。
win.graph(width=10.5, height=9.5,pointsize=9)
stars(iris,labels=x,flip.labels=FALSE)

这下是不是整齐多了。
颜色:
接下来,我们谈谈颜色,这里主要有一下几种对颜色设置的方法:
1.给每个块加颜色
使用draw.segments参数
stars(iris,draw.segments = TRUE)

使用col.segments 参数,只有当draw.segments 为 TRUE时,col.segments 参数才有效。
stars(iris,draw.segments = TRUE,col.segments = rainbow(8))

2.线条加色
在对线条加色是,我们仅需对col.lines参数进行设置,仅当draw.segments 为FALSE时才有效。
stars(iris,draw.segments = FALSE,col.lines=c(1:150))

好了,这就是对星图的一个总结,现在,我们就来一个大综合,将前面这些综合在一块来绘制一副图。
win.graph(width=10.5, height=9.5,pointsize=9)
stars(iris,draw.segments = TRUE,col.segments = rainbow(7),
main="iris数据分析", frame.plot = TRUE,labels=x,flip.labels=FALSE)
#frame.plot是给图片四周加了一个黑框

