
作者:kbsc13
个人公众号:机器学习与计算机视觉
计划通过几篇文章来介绍下,一个完整的机器学习项目的实现步骤,最后会结合《hands-on-ml-with-sklearn-and-tf》的例子来介绍下相应代码的实现。
这是如何构建一个完整的机器学习项目第一篇!
这里先给出一个完整的机器学习项目过程的主要步骤,如下所示:
项目概述。
获取数据。
发现并可视化数据,发现规律
为机器学习算法准备数据。
选择模型,进行训练。
微调模型。
给出解决方案。
部署、监控、维护系统
第一篇文章会介绍下第一节内容,开始一个项目的时候,需要确定什么问题,包括选择合适的损失函数。
1. 项目概览
1.1 划定问题
当我们开始一个机器学习项目的时候,需要先了解两个问题:
商业目标是什么?公司希望利用算法或者模型收获什么,这决定需要采用什么算法和评估的性能指标?
当前的解决方案效果如何?
通过上述两个问题,我们就可以开始设计系统,也就是解决方案。
但首先,有些问题也需要了解清楚:
监督还是无监督,或者是强化学习?
是分类,回归,还是其他类型问题?
采用批量学习还是需要线上学习。
1.2 选择性能指标
选择性能指标,通常对于模型,首先就是指模型的准确率,而在机器学习中,算法的准确率是需要通过减少损失来提高的,这就需要选择一个合适的损失函数来训练模型。
一般,从学习任务类型可以将损失函数划分为两大类--回归损失和分类损失,分别对应回归问题和分类问题。
回归损失均方误差 / 平方误差 / L2 误差
均方误差(MSE)度量的是预测值和真实值之间差的平方的均值,它只考虑误差的平均大小,不考虑其方向。但经过平方后,对于偏离真实值较多的预测值会受到更严重的惩罚,并且 MSE 的数学特性很好,也就是特别易于求导,所以计算梯度也会变得更加容易。
MSE 的数学公式如下:
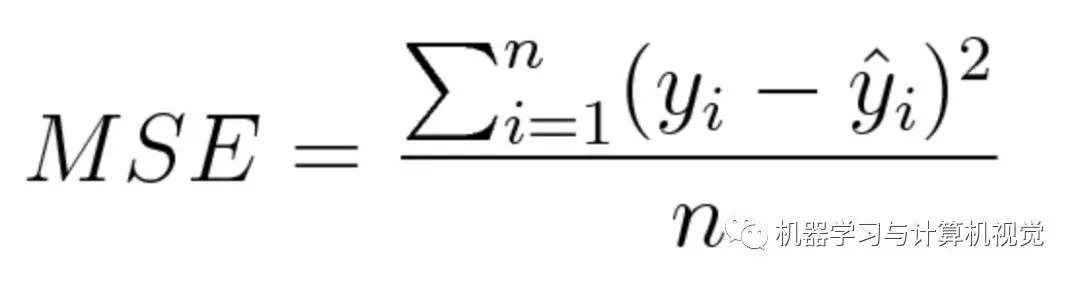
代码实现如下:
def rmse(predictions, targets):
# 真实值和预测值的误差
differences = predictions - targets
differences_squared = differences ** 2
mean_of_differences_squared = differences_squared.mean()
# 取平方根
rmse_val = np.sqrt(mean_of_differences_squared)
return rmse_val
当然上述代码实现的是均方根误差(RMSE),一个简单的测试例子如下:
y_hat = np.array([0.000, 0.166, 0.333])
y_true = np.array([0.000, 0.254, 0.998])
print("d is: " + str(["%.8f" % elem for elem in y_hat]))
print("p is: " + str(["%.8f" % elem for elem in y_true]))
rmse_val = rmse(y_hat, y_true)
print("rms error is: " + str(rmse_val))
输出结果为:
d is: ['0.00000000', '0.16600000', '0.33300000']
p is: ['0.00000000', '0.25400000', '0.99800000']
rms error is: 0.387284994115
平方绝对误差 / L1 误差
平均绝对误差(MAE)度量的是预测值和实际观测值之间绝对差之和的平均值。和 MSE 一样,这种度量方法也是在不考虑方向的情况下衡量误差大小。但和 MSE 的不同之处在于,MAE 需要像线性规划这样更复杂的工具来计算梯度。此外,MAE 对异常值更加稳健,因为它不使用平方。
数学公式如下:
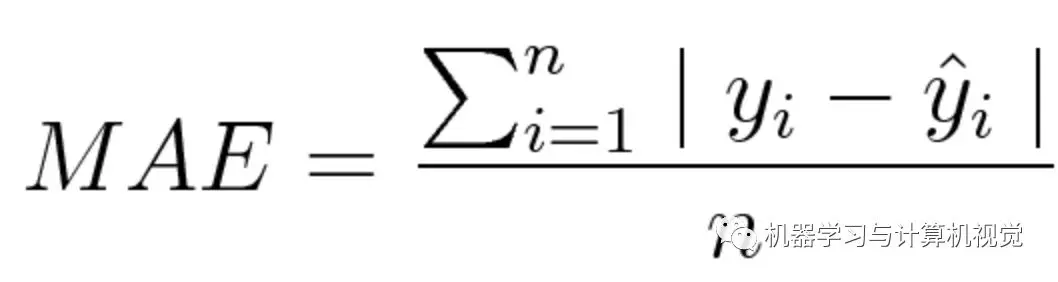
MAE 的代码实现也不难,如下所示:
def mae(predictions, targets):
differences = predictions - targets
absolute_differences = np.absolute(differences)
mean_absolute_differences = absolute_differences.mean()
return mean_absolute_differences
测试样例可以直接用刚才的 MSE 的测试代码,输出结果如下:
d is: ['0.00000000', '0.16600000', '0.33300000']
p is: ['0.00000000', '0.25400000', '0.99800000']
mae error is: 0.251
平均偏差误差(mean bias error)
这个损失函数应用得比较少,在机器学习领域太不常见了,我也是第一次看到这个损失函数。它和 MAE 很相似,唯一区别就是它没有用绝对值。因此,需要注意的是,正负误差可以互相抵消。尽管在实际应用中没那么准确,但它可以确定模型是存在正偏差还是负偏差。
数学公式如下:
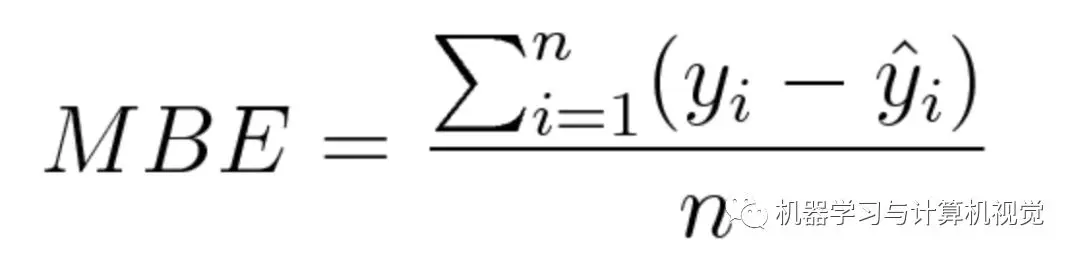
代码的实现,其实只需要在 MAE 的基础上删除加入绝对值的代码,如下所示:
def mbe(predictions, targets):
differences = predictions - targets
mean_absolute_differences = differences.mean()
return mean_absolute_differences
还是利用刚刚的测试样例,结果如下:
d is: ['0.00000000', '0.16600000', '0.33300000']
p is: ['0.00000000', '0.25400000', '0.99800000']
mbe error is: -0.251
可以看到我们给的简单测试样例,存在一个负偏差。
分类误差Hinge Loss / 多分类 SVM 误差
hinge loss 常用于最大间隔分类(maximum-margin classification),它是在一定的安全间隔内(通常是 1),正确类别的分数应高于所有错误类别的分数之和。最常用的就是支持向量机(SVM)。尽管不可微,但它是一个凸函数,可以采用机器学习领域中常用的凸优化器。
其数学公式如下:
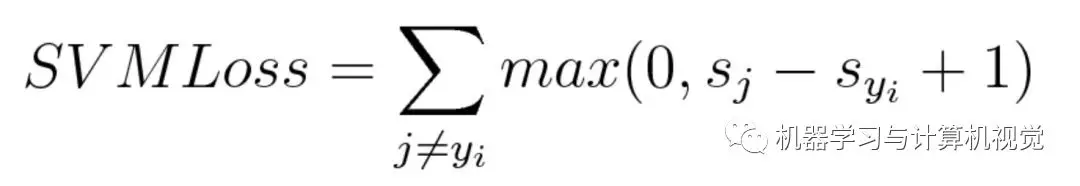
公式中 sj 表示的是预测值,而 s_yi 是真实值,也可以说是正确预测的数值,而 1 表示的就是间隔 margin,这里我们希望通过真实值和预测值之间的差来表示两种预测结果之间的相似关系,而 margin 是人为设置的一个安全系数,我们是希望正确分类的得分要高于错误预测的得分,并且是高于一个 margin 的数值,也就是s_yi越高越好,s_j越低越好。这样计算得到的 Loss 会趋向于 0.
用一个简单的例子说明,假设现在有如下三个训练样本,我们需要预测三个类别,下面表格中的数值就是经过算法得到的每个类别的数值:

每一列就每张图片每个类别的数值,我们也可以知道每一列的真实值分别是狗、猫、马。简单的代码实现如下:
def hinge_loss(predictions, label):
'''
hinge_loss = max(0, s_j - s_yi +1)
:param predictions:
:param label:
:return:
'''
result = 0.0
pred_value = predictions[label]
for i, val in enumerate(predictions):
if i == label:
continue
tmp = val - pred_value + 1
result += max(0, tmp)
return result
测试例子如下:
image1 = np.array([-0.39, 1.49, 4.21])
image2 = np.array([-4.61, 3.28, 1.46])
image3 = np.array([1.03, -2.37, -2.27])
result1 = hinge_loss(image1, 0)
result2 = hinge_loss(image2, 1)
result3 = hinge_loss(image3, 2)
print('image1,hinge loss={}'.format(result1))
print('image2,hinge loss={}'.format(result2))
print('image3,hinge loss={}'.format(result3))
# 输出结果
# image1,hinge loss=8.48
# image2,hinge loss=0.0
# image3,hinge loss=5.199999999999999
这个计算过程更加形象的说明:
## 1st training example
max(0, (1.49) - (-0.39) + 1) + max(0, (4.21) - (-0.39) + 1)
max(0, 2.88) + max(0, 5.6)
2.88 + 5.6
8.48 (High loss as very wrong prediction)
## 2nd training example
max(0, (-4.61) - (3.28)+ 1) + max(0, (1.46) - (3.28)+ 1)
max(0, -6.89) + max(0, -0.82)
0 + 0
0 (Zero loss as correct prediction)
## 3rd training example
max(0, (1.03) - (-2.27)+ 1) + max(0, (-2.37) - (-2.27)+ 1)
max(0, 4.3) + max(0, 0.9)
4.3 + 0.9
5.2 (High loss as very wrong prediction)
通过计算,hinge loss 数值越高,就代表预测越不准确。
交叉熵损失 / 负对数似然
交叉熵损失(cross entroy loss)是分类算法最常用的损失函数。
数学公式:
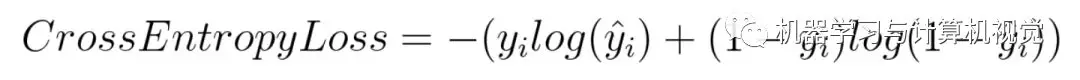
根据公式,如果实际标签y_i是 1, 那么公式只有前半部分;如果是 0, 则只有后半部分。简单说,交叉熵是将对真实类别预测的概率的对数相乘,并且,它会重重惩罚那些置信度很高但预测错误的数值。
代码实现如下:
def cross_entropy(predictions, targets, epsilon=1e-10):
predictions = np.clip(predictions, epsilon, 1. - epsilon)
N = predictions.shape[0]
ce_loss = -np.sum(np.sum(targets * np.log(predictions + 1e-5))) / N
return ce_loss
测试样例如下:
predictions = np.array([[0.25, 0.25, 0.25, 0.25],
[0.01, 0.01, 0.01, 0.96]])
targets = np.array([[0, 0, 0, 1],
[0, 0, 0, 1]])
cross_entropy_loss = cross_entropy(predictions, targets)
print("Cross entropy loss is: " + str(cross_entropy_loss))
# 输出结果
# Cross entropy loss is: 0.713532969914
上述代码例子,源代码地址:
https://github.com/ccc013/CodesNotes/blob/master/hands_on_ml_with_tf_and_sklearn/Loss_functions_practise.py
1.3 核实假设
核实假设其实也可以说是确定你设计的系统的输入输出,我们的机器学习项目是需要商用的话,肯定就不只是一个算法模型,通常还会有前端展示页面效果,后端的服务等等,你需要和前后端的负责人进行沟通,核实接口的问题。
比如,《hands-on-ml-with-sklearn-and-tf》书中给出的例子是设计一个预测房价的系统,其输出是房价的数值,但是如果前端需要展示的是类别,即房价是便宜、中等还是昂贵,那么我们的系统输出的房价就没有意义了,这时候我们要解决的就是分类问题,而不是回归问题。
因此,当你在做一个机器学习项目的时候,你需要和有工作交接的同事保持良好的沟通,随时进行交流,确认接口的问题。
小结
第一篇简单介绍了开始一个机器学习项目,首先需要明确商业目标,已有的解决方案,设计的机器学习系统属于什么类型任务,并以此为基础,选择合适的性能指标,即损失函数。
参考:

往期精选
应聘高端职位,如何准备?
K近邻算法(KNN)原理小结
如何写一份受面试官青睐的简历
总结 | 基于代码的数学符号释义(一)
2018年终精心整理|人工智能爱好者社区历史文章合集(作者篇)
2018年终精心整理 | 人工智能爱好者社区历史文章合集(类型篇)
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

