
作者:李娟 擅长Tableau可视化/神经网络等机器学习
个人公众号:数据运营人
前言
随着第三次信息化浪潮的涌动, 云计算、大数据、物联网技术普及增加。云计算和大数据使人工智能的节节高升, 大数据技术兴起导致更多的结构化和非结够化数据被数据科学家们所关注。 文字词汇产生了文本数据, 由此文本挖掘成为了数据热门的新方向。文本挖掘现今已应用在信息检索/机器翻译/文档分类/问答系统/信息过滤/自动文摘/信息抽取/文本挖掘/舆情分析/机器写作/语音识别等诸多领域。 可见文本数据分析的领域涉及非常广泛, 大数据文本下的挖掘也让我们更好的能认识到源自中化上下五千年的汉字文化,下面让我们一起从文本分析的中文词语划分进行简单的探索研究。
音构成字,字组成词,词构成句,句构成段,段成文章。所谓的文本分析,最粗浅的是对文本进行分词处理,通过文章的逐级剥皮将一个句子切分成一个一个符合逻辑的词语对划分出的词语进行处理,衍生出词频统计等功能。
收获。
Jieba分词
中文分词是汉语自然语言处理的第一部分,如果不能正确的分词,后续的操作效果价值意义将降低。下面使用Python的jieba包进行分词,也叫“结巴”分词, 结巴分词目前也是中文分词中的主流办法之一。jieba主要支持三种分词模式 使用结巴分词也尽可能对词句中的分词进行有效化的处理。
结巴分词的模式为:
1. 全模式:将句子中所有的可以成词的词语都扫描出来,速度快,但不能解决歧义。效果如下所示:
1import jieba
2sent = "全面发力、 多点突破、 蹄疾步稳、 纵深推进——庆祝改革开放40
3周年大会上, 习近平总书记用16个字描绘了新时代全面深化改革的壮阔
4图景。 "
5# 结巴分词——全模式
6seg_list = jieba.cut(sent,cut_all=True)
7print('[全模式]: ',"/".join(seg_list))
2. 精确模式:将句子精确的分开,适合做文本分析。效果如下所示:
1import jieba
2sent = "全面发力、 多点突破、 蹄疾步稳、 纵深推进——庆祝改革开放40
3周年大会上, 习近平总书记用16个字描绘了新时代全面深化改革的壮阔
4图景。 "
5# 结巴分词——精确模式
6seg_list = jieba.cut(sent,cut_all=False) # 在不写cut_all的情况下, 默认为
7精确模式
8print('[精确模式]: ',"/".join(seg_list))
3.搜索引擎模式:在精确模式的基础上,对长词再次进行切分。效果如下所示:
1import jieba
2sent = "全面发力、 多点突破、 蹄疾步稳、 纵深推进——庆祝改革开放40
3周年大会上, 习近平总书记用16个字描绘了新时代全面深化改革的壮阔
4图景。 "
5# 结巴分词——精确模式
6seg_list = jieba.cut(sent,cut_all=False) # 在不写cut_all的情况下, 默认为
7精确模式
8# 结巴分词——搜索引擎模式
9seg_list = jieba.cut_for_search(sent) # 搜索引擎模式
10print("[搜索引擎模式]: ",'/'.join(seg_list))
返回结果如下图所示:

通过上图, 发现“深化改革”被分为一个词, 如果想将“深化改革”分为“深化”和“改革”, 或者想将“新”和“时代”修改为“新时代“, 就可以添加自定义的用户词典。
用法: jieba.load_userdict(filename) # filename为自定义词典的路径(自定义词典的形式是每一行分为三部分:词语/词频(可省略)/词性(可省略))调整词典:
1.使用 add_word(word, freq=None,tag=None) 和del_word(word) 可在程序中动态修改词典。
2.使用 suggest_freq(segment, tune=True)可调节单个词语的词频, 使其能(或不能) 被分出来。
操作如下所示:
1jieba.load_userdict('/Users/lili/python/lianxi/userdict.txt')
2seg_list = jieba.cut(sent,cut_all=False)
3print('[自定义词库后]: ',"/".join(seg_list))
返回结果:

词性标注
词性标注,指一个词在一个句子中所扮演的语法角色。 如名词/动词/形容词等。 在汉语中, 常用的词性都不是固定的, 换言之, 一个词可能有多种词性, 并且对于每个不同的词性, 汉语词汇都没有形态的变化。
如下操作:
1import jieba.posseg as pseg
2words = pseg.cut(sent)
3for word, flag in words:
4print(word, flag)
返回结果:

命名实体识别
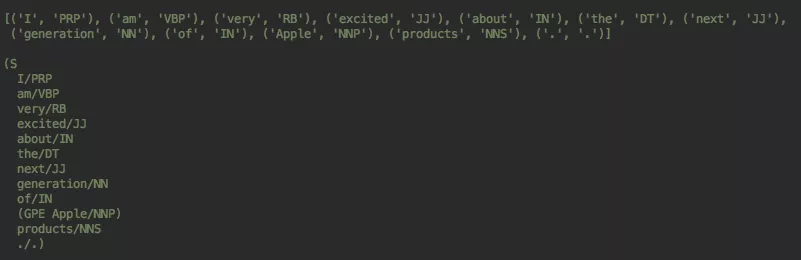
所谓命名实体识别就是识别文本中具有特定意义的实体, 常见的实体主要包含人名/地名/机构名以及其他的转有名词等。可通过NLTK中的函数进行命名实体识别 。 操作如下:
1import nltk
2tokens = nltk.word_tokenize('I am very excited about the next generation of
3Apple products.')
4tokens = nltk.pos_tag(tokens)
5print(tokens)
6tree = nltk.ne_chunk(tokens)
7print(tree)
返回结果为:
新词识别
新词识别指未登录词的识别, 新词指随着时代的发展新出现的词语, 如给力/尬聊/皮皮虾/老铁等, 导致部分的分词效果并不是非常好。以上操作全来自于Python语言的处理, 像Mapreduce/C语言/Java语言/R语言, 等诸多语言也能对文本进行挖掘分析, 在设定词库或者停词分词后大多能分出较好的效果。中华文化渊源流长, 汉字词语博大精深,相信随着文本挖掘技术的更新, 分词的精确度也将会越来越高。

推荐阅读:
原来,数据分析还可以这样干......
2018年终精心整理|人工智能爱好者社区历史文章合集(作者篇)
2018年终精心整理 | 人工智能爱好者社区历史文章合集(类型篇)
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

