
原作 | Dima Shulga
来源 | https://towardsdatascience.com/5-reasons-logistic-regression-should-be-the-first-thing-you-learn-when-become-a-data-scientist-fcaae46605c4
翻译 | xiaoyu
在几年之前,我踏进了数据科学的大门。之前还是软件工程师的时候,我是最先开始在网上自学的(在开始我的硕士学位之前)。我记得当我搜集网上资源的时候,我看见的只有玲琅满目的算法名称—线性回归,支持向量机(SVM),决策树(DT),随即森林(RF),神经网络等。对于刚刚开始学习的我来说,这些算法都是非常有难度的。但是,后来我才发现:要成为一名数据科学家,最重要的事情就是了解和学习整个的流程,比如,如何获取和处理数据,如何理解数据,如何搭建模型,如何评估结果(模型和数据处理阶段)和优化。为了达到这个目的,我认为从逻辑回归开始入门是非常不错的选择,这样不但可以让我们很快熟悉这个流程,而且不被那些高大上的算法所吓倒。
因此,下面将要列出5条原因来说明为什么最开始学习逻辑回归是入门最好的选择。当然,这只是我个人的看法,对于其他人可能有更快捷的学习方式。
1. 因为模型算法只是整个流程的一部分
像我之前提到的一样,数据科学工作不仅仅是建模,它还包括以下的步骤:
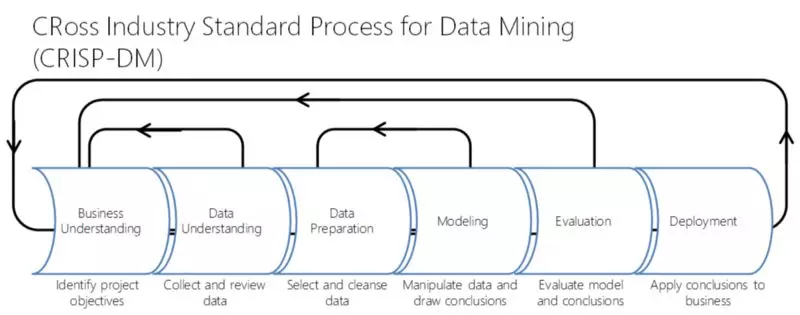
可以看到,“建模” 只是这个重复过程的一部分而已。当开展一个数据产品的时候,一个非常好的实践就是首先建立你的整个流程,让它越简单越好,清楚地明白你想要获得什么,如何进行评估测试,以及你的baseline是什么。随后在这基础上,你就可以加入一些比较炫酷的机器学习算法,并知道你的效果是否变得更好。
顺便说下,逻辑回归(或者任何ML算法)可能不只是在建模部分所使用,它们也可能在数据理解和数据准备的阶段使用,填补缺失值就是一个例子。
2. 因为你将要更好地理解机器学习
我想当大家看到本篇的时候,第一个想要问的问题就是:为什么是逻辑回归,而不是线性回归。真相其实是都无所谓,理解了机器学习才是最终目的。说到这个问题,就要引出监督学习的两个类型了,分类(逻辑回归)和回归(线性回归)。当你使用逻辑回归或者线性回归建立你整个流程的时候(越简单越好),你会慢慢地熟悉机器学习里的一些概念,例如监督学习v.s非监督学习,分类v.s回归,线性v.s非线性等,以及更多问题。你也会知道如何准备你的数据,以及这过程中有什么挑战(比如填补缺失值和特征选择),如何度量评估模型,是该使用准确率,还是精准率和召回率,RUC AUC?又或者可能是 “均方差”和“皮尔逊相关”?所有的概念都都是数据科学学习过程中非常重要的知识点。等慢慢熟悉了这些概念以后,你就可以用更复杂的模型或者技巧(一旦你掌握了之后)来替代你之前的简单模型了。
3. 因为逻辑回归有的时候,已经足够用了
逻辑回归是一个非常强大的算法,甚至对于一些非常复杂的问题,它都可以做到游刃有余。拿MNIST举例,你可以使用逻辑回归获得95%的准确率,这个数字可能并不是一个非常出色的结果,但是它对于保证你的整个流程工作来说已经足够好了。实际上,如果说能够选择正确且有代表性的特征,逻辑回归完全可以做的非常好。
当处理非线性的问题时,我们有时候会用可解释的线性方式来处理原始数据。可以用一个简单的例子来说明这种思想:现在我们想要基于这种思想来做一个简单的分类任务。
X1 x2 | Y
==================
-2 0 1
2 0 1
-1 0 0
1 0 0
如果我们将数据可视化,我们可以看到没有一条直线可以将它们分开。
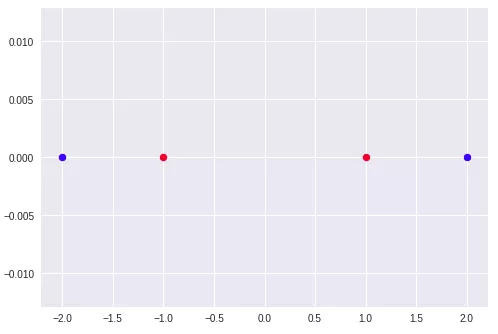
在这种情况下,如果不对数据做一些处理的话,逻辑回归是无法帮到我们的,但是如果我们不用x2 特征,而使用x1²来代替,那么数据将会变成这样:
X1 x1^2 | Y
==================
-2 4 1
2 4 1
-1 1 0
1 1 0

现在,就存在一条直线可以将它们分开了。当然,这个简单的例子只是为了说明这种思想,对于现实世界来讲,很难发现或找到如何改变数据的方法以可以使用线性分类器来帮助你。但是,如果你可以在特征工程和特征选择上多花些时间,那么很可能你的逻辑回归是可以很好的胜任的。
4. 因为逻辑回归是统计中的一个重要工具
线性回归不仅仅可以用来预测。如果你有了一个训练好的线性模型,你可以通过它学习到因变量和自变量之间的关系,或者用更多的ML语言来说,你可以学习到特征变量和目标变量的关系。一个简单的例子,房价预测,我们有很多房屋特征,还有实际的房价。我们基于这些数据训练一个线性回归模型,然后得到了很好的结果。通过训练,我们可以发现模型训练后会给每个特征分配相应的权重。如果某个特征权重很高,我们就可以说这个特征比其它的特征更重要。比如房屋大小特征,对于房价的变化会有50%的权重,因为房屋大小每增加一平米房价就会增加10k。线性回归是一个了解数据以及统计规律的非常强的工具,同理,逻辑回归也可以给每个特征分配各自的权重,通过这个权重,我们就可以了解特征的重要性。
5. 因为逻辑回归是学习神经元网络很好的开始
当学习神经元网络的时候,最开始学习的逻辑回归对我帮助很大。你可以将网络中的每个神经元当作一个逻辑回归:它有输入,有权重,和阈值,并可以通过点乘,然后再应用某个非线性的函数得到输出。更多的是,一个神经元网络的最后一层大多数情况下是一个简单的线性模型,看一下最基本的神经元网络:

如果我们更深入地观察一下output层,可以看到这是一个简单的线性(或者逻辑)回归,有hidden layer 2作为输入,有相应的权重,我们可以做一个点乘然后加上一个非线性函数(根据任务而定)。可以说,对于神经元网络,一个非常好的思考方式是:将NN划分为两部分,一个是代表部分,一个是分类/回归部分。
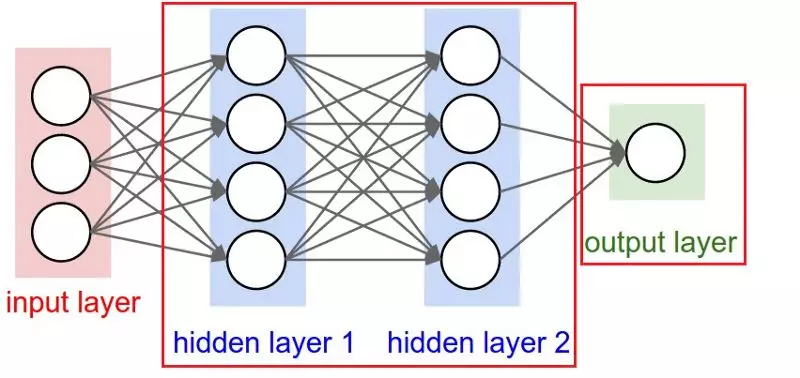
第一部分(左侧)尝试从数据中学习并具有很好的代表性,然后它会帮助第二个部分(右侧)来完成一个线性的分类或者回归任务。
总结
成为一个数据科学家你可能需要掌握很多知识,第一眼看上去,好像学习算法才是最重要的部分。实际的情况是:学习算法确实是所有情况中最复杂的部分,需要花费大量的时间和努力来理解,但它也只是数据科学中的一个部分,把握整体更为关键。
- END -
往期精彩:
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

