作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
1.背景
在构建精准用户画像时,面临着这样一个问题:日志采集不能成功地收集用户的所有ID,且每条业务线有各自定义的UID用来标识用户,从而造成了用户ID的零碎化。因此,为了做用户标签的整合,用户ID之间的强打通(亦称为ID-Mapping)成了迫切的需求。大概三年前,在知乎上有这样一个与之相类似的问题:如何用MR实现并查集以对海量数据pair做聚合;目前为止还无人解答。本文将提供一个可能的基于MR计算框架的解决方案,以实现大数据下的ID强打通。
首先,简要地介绍下Android设备常见的ID:
IMEI(International Mobile Equipment Identity),即通常所说的手机序列号、手机“串号”,用于在移动电话网络中识别每一部独立的手机等行动通讯装置;序列号共有15位数字,前6位(TAC)是型号核准号码,代表手机类型。接着2位(FAC)是最后装配号,代表产地。后6位(SNR)是串号,代表生产顺序号。最后1位(SP)一般为0,是检验码,备用。
MAC(Media Access Control)一般代指MAC位址,为网卡的标识,用来定义网络设备的位置。
IMSI(International Mobile SubscriberIdentification Number),储存在SIM卡中,可用于区别移动用户的有效信息;其总长度不超过15位,同样使用0~9的数字。其中MCC是移动用户所属国家代号,占3位数字,中国的MCC规定为460;MNC是移动网号码,最多由两位数字组成,用于识别移动用户所归属的移动通信网;MSIN是移动用户识别码,用以识别某一移动通信网中的移动用户。
Android ID是系统随机生成的设备ID 为一串64位的编码(十六进制的字符串),通过它可以知道设备的寿命(在设备恢复出厂设置或刷机后,该值可能会改变)。
IDFA (Identifier for Advertisers) 是苹果推出来的用于广告标识的设备ID,同一设备上的不同APP所获取的IDFA是一致的;但是用户可以自主更改IDFA,所以IDFA并不是和设备一一绑定的。
2.设计
从图论的角度出发,ID强打通更像是将小连通图合并成一个大连通图;比如,在日志中出现如下三条记录,分别表示三个ID集合(小连通图):
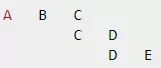
通过将三个小连通图合并,便可得到一个大连通图——完整的ID集合列表 。淘宝明风介绍了如何用Spark GraphX通过outerJoinVertices等运算符来做大数据下的多图合并;针对ID强打通的场景,也可采用类似的思路:日志数据构建大的稀疏图,然后采用自join的方式做打通。但是,我并没有选用GraphX,理由如下:
。淘宝明风介绍了如何用Spark GraphX通过outerJoinVertices等运算符来做大数据下的多图合并;针对ID强打通的场景,也可采用类似的思路:日志数据构建大的稀疏图,然后采用自join的方式做打通。但是,我并没有选用GraphX,理由如下:
因而,基于MR计算模型(Spark框架)我设计新的ID打通算法;算法流程如下:打通的map阶段将ID集合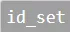 中每一个Id做key然后进行打散(
中每一个Id做key然后进行打散( ),Reduce阶段按key做
),Reduce阶段按key做 的合并。通过观察发现:仅需要两步MR便可完成上述打通的操作。以上面的例子做说明,第一步MR完成后,打通ID集合为:
的合并。通过观察发现:仅需要两步MR便可完成上述打通的操作。以上面的例子做说明,第一步MR完成后,打通ID集合为: 、
、 ,第二步MR完成后便得到完整的ID集合列表
,第二步MR完成后便得到完整的ID集合列表 。但是,在两步MR过程中,所有的key都会对应一个聚合结果,而其中一些聚合结果只是中间结果。故而引入了
。但是,在两步MR过程中,所有的key都会对应一个聚合结果,而其中一些聚合结果只是中间结果。故而引入了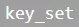 用于保存聚合时的key值,加入了第三步MR,通过比较
用于保存聚合时的key值,加入了第三步MR,通过比较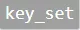 与
与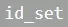 来对中间聚合结果进行过滤。算法的伪代码如下:
来对中间聚合结果进行过滤。算法的伪代码如下:
MR step1:
Map:
input: id_set
process: flatMap id_set;
output: id -> (id_set, 1)
Rduce:
process: reduceByKey
output: id -> (id_set, empty key_set, int_value)
MR step2:
Map:
input: id -> (id_set, empty key_set, int_value)
process: flatMap id_set, if have id_aggregation, then add key to key_set
output: id -> (id_set, key_set, int_value)
Reduce:
process: reduceByKey
output: id -> (id_set, key_set, int_value)
MR step3:
Map:
input: id -> (id_set, empty key_set, int_value)
process: flatMap id_set, if have id_aggregation, then add key to key_set
output: id -> (id_set, key_set, int_value)
Reduce:
process: reduceByKey
output: id -> (id_set, key_set, int_value)
Filters:
process: if have id_aggregation, then add key to key_set
filter: if no id_aggregation or key_set == id_set
distinct
3.实现
针对上述ID强打通算法,Spark实现代码如下:
case class DvcId(id: String, value: String)
val log: RDD[mutable.Set[DvcId]]
// MR1
val rdd1: RDD[(DvcId, (mutable.Set[DvcId], mutable.Set[DvcId], Int))] = log
.flatMap { set =>
set.map(t => (t, (set, 1)))
}.reduceByKey { (t1, t2) =>
t1._1 ++= t2._1
val added = t1._2 + t2._2
(t1._1, added)
}.map { t =>
(t._1, (t._2._1, mutable.Set.empty[DvcId], t._2._2))
}
// MR2
val rdd2: RDD[(DvcId, (mutable.Set[DvcId], mutable.Set[DvcId], Int))] = rdd1
.flatMap(flatIdSet).reduceByKey(tuple3Add)
// MR3
val rdd3: RDD[(DvcId, (mutable.Set[DvcId], mutable.Set[DvcId], Int))] = rdd2
.flatMap(flatIdSet).reduceByKey(tuple3Add)
// filter
val rdd4 = rdd3.filter { t =>
t._2._2 += t._1
t._2._3 == 1 || (t._2._1 -- t._2._2).isEmpty
}.map(_._2._1).distinct()
// flat id_set
def flatIdSet(row: (DvcId, (mutable.Set[DvcId], mutable.Set[DvcId], Int))) = {
row._2._3 match {
case 1 =>
Array((row._1, (row._2._1, row._2._2, row._2._3)))
case _ =>
row._2._2 += row._1 // add key to keySet
row._2._1.map(d => (d, (row._2._1, row._2._2, row._2._3))).toArray
}
}
def tuple3Add(t1: (mutable.Set[DvcId], mutable.Set[DvcId], Int),
t2: (mutable.Set[DvcId], mutable.Set[DvcId], Int)) = {
t1._1 ++= t2._1
t1._2 ++= t2._2
val added = t1._3 + t2._3
(t1._1, t1._2, added)
}
其中,引入常量1是为了标记该条记录是否发生了ID聚合的情况。
ID强打通算法实现起来比较简单,但是在实际的应用时,日志数据往往是带噪声的:
另外,ID强打通后是HDFS的离线数据,为了提供线上服务、保证ID之间的一一对应关系,应选择何种分布式数据库、表应如何设计、如何做到数据更新时而不影响线上服务等等,则是另一个需要思考的问题。
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】SVM
【十大经典数据挖掘算法】Apriori
【十大经典数据挖掘算法】EM
【十大经典数据挖掘算法】PageRank
【十大经典数据挖掘算法】AdaBoost
【从传统方法到深度学习】图像分类
【十大经典数据挖掘算法】kNN
【十大经典数据挖掘算法】Naïve Bayes
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

