作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
朴素贝叶斯(Naïve Bayes)属于监督学习的生成模型,实现简单,没有迭代,学习效率高,在大样本量下会有较好的表现。但因为假设太强——假设特征条件独立,在输入向量的特征条件有关联的场景下并不适用。
1.朴素贝叶斯算法
朴素贝叶斯分类器的主要思路:通过联合概率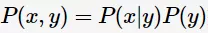 建模,运用贝叶斯定理求解后验概率
建模,运用贝叶斯定理求解后验概率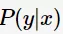 ;将后验概率最大者对应的的类别作为预测类别。
;将后验概率最大者对应的的类别作为预测类别。
分类方法
首先,我们定义训练集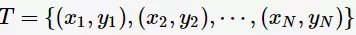 ,其类别
,其类别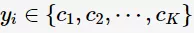 ,则训练集中样本点数为N,类别数为K。
,则训练集中样本点数为N,类别数为K。
输入待预测数据X,则预测类别

由贝叶斯定理可知:

对于类别 而言,
而言,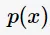 是恒等的,因此式子(1)等价于
是恒等的,因此式子(1)等价于

从上面式子可以看出:朴素贝叶斯将分类问题转化成了求条件概率与先验概率的最大乘积问题。先验概率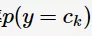 可通过计算类别的频率得到,但如何计算条件概率
可通过计算类别的频率得到,但如何计算条件概率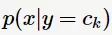 呢?
呢?
朴素贝叶斯对条件概率做了条件独立性的假设,即特征条件相互独立。设输入X为n维特征向量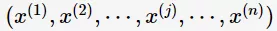 ,第 j 维特征
,第 j 维特征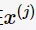 的取值有
的取值有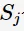 个。由概率论的知识可知:
个。由概率论的知识可知:
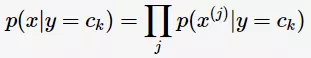
式子(2)等价于
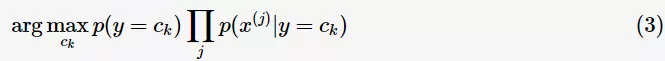
为什么要选择后验概率最大的类别作为预测类别呢?因为后验概率最大化,可以使得期望风险最小化,具体证明参看[1]。
极大似然估计
在朴素贝叶斯学习中,需要估计先验概率与条件概率,一般时采用极大似然估计。先验概率的极大似然估计:
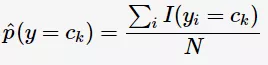
其中,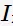 是指示函数,满足括号内条件时为1否则为0;可以看作为计数。
是指示函数,满足括号内条件时为1否则为0;可以看作为计数。
设第 j 维特征的取值空间为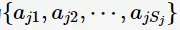 ,且输入变量的第 j 维
,且输入变量的第 j 维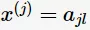 ,则条件概率的极大似然估计:
,则条件概率的极大似然估计:
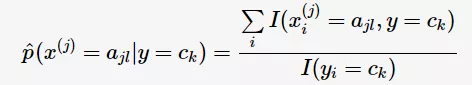
贝叶斯估计
在估计先验概率与条件概率时,有可能出现为0的情况,则计算得到的后验概率亦为0,从而影响分类的效果。因此,需要在估计时做平滑,这种方法被称为贝叶斯估计(Bayesian estimation)。先验概率的贝叶斯估计:
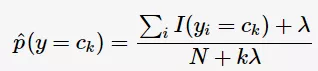
后验概率的贝叶斯估计:
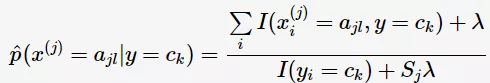
常取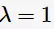 ,这时被称为Laplace平滑(Laplace smoothing)。下面提到的拼写检查则用到了Laplace平滑——初始时将所有单词的计数置为1。
,这时被称为Laplace平滑(Laplace smoothing)。下面提到的拼写检查则用到了Laplace平滑——初始时将所有单词的计数置为1。
2.拼写检查
当用户在输入拼写错误单词时,如何返回他想输入的拼写正确单词。比如,用户输入单词thew,用户有到底是想输入the,还是想输入thaw?这种拼写检查的问题等同于分类问题:在许多可能拼写正确单词中,到底哪一个时最有可能的呢?大神Peter Norvig [2]采用朴素贝叶斯解决这个拼写问题。
朴素贝叶斯分类
设用户输入的单词为w,要返回的拼写正确单词为c,拼写检查要找出最大可能的c,即:

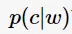 可以理解为在已发生w的情况下发生c的概率。根据贝叶斯定理:
可以理解为在已发生w的情况下发生c的概率。根据贝叶斯定理:

贝叶斯分类器可表示为:
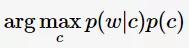
如何估计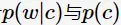 呢?估计p(c)的办法可以在文本库中统计单词c的频率。p(w|c)表示大多数用户在输入c时拼写错误输入成了w的概率,可以看作时错误模型。这需要对大量的错误输入进行统计,才能对p(w|c)估计得较为准确。Norvig对此做了简易化的处理:
呢?估计p(c)的办法可以在文本库中统计单词c的频率。p(w|c)表示大多数用户在输入c时拼写错误输入成了w的概率,可以看作时错误模型。这需要对大量的错误输入进行统计,才能对p(w|c)估计得较为准确。Norvig对此做了简易化的处理:
统计所有与w编辑距离为1的拼写正确单词,选出在文本库中频率最高者;
若未找到与w编辑距离为1的拼写正确单词,则统计所有与w编辑距离为2的拼写正确单词,选出在文本库中频率最高者
若与w编辑距离为2的拼写正确单词也未找到,则返回w(即分类失败)。
所谓编辑距离为1,指单词可以通过增加、删除、修改(一个字母)或交换(相邻两个字母)变成另外的单词。上述处理办法默认了:编辑距离为1的拼写正确单词永远比编辑距离为2的更有可能。
存在问题:
Norvig所介绍的拼写检查是非常简单的一种,他在博文[2]中指出不足。此外,还有一些需要优化的地方:
3.参考材料:
[1] 李航,《统计学习方法》.
[2] Peter Norvig, How to Write a Spelling Corrector.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】SVM
【十大经典数据挖掘算法】Apriori
【十大经典数据挖掘算法】EM
【十大经典数据挖掘算法】PageRank
【十大经典数据挖掘算法】AdaBoost
【从传统方法到深度学习】图像分类
【十大经典数据挖掘算法】kNN

公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

