作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
SVM(Support Vector Machines)是分类算法中应用广泛、效果不错的一类。《统计学习方法》对SVM的数学原理做了详细推导与论述,本文仅做整理。由简至繁SVM可分类为三类:线性可分(linear SVM in linearly separable case)的线性SVM、线性不可分的线性SVM、非线性(nonlinear)SVM。
1.线性可分
对于二类分类问题,训练集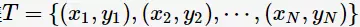 ,其类别
,其类别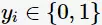 ,线性SVM通过学习得到分离超平面(hyperplane):
,线性SVM通过学习得到分离超平面(hyperplane):
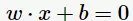
以及相应的分类决策函数:
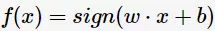
有如下图所示的分离超平面,哪一个超平面的分类效果更好呢?
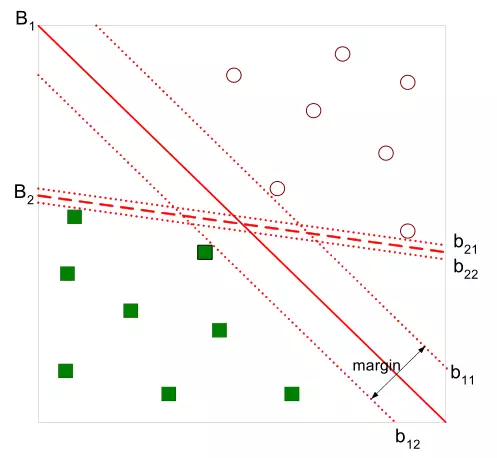
直观上,超平面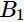 的分类效果更好一些。将距离分离超平面最近的两个不同类别的样本点称为支持向量(support vector)的,构成了两条平行于分离超平面的长带,二者之间的距离称之为margin。显然,margin更大,则分类正确的确信度更高(与超平面的距离表示分类的确信度,距离越远则分类正确的确信度越高)。通过计算容易得到:
的分类效果更好一些。将距离分离超平面最近的两个不同类别的样本点称为支持向量(support vector)的,构成了两条平行于分离超平面的长带,二者之间的距离称之为margin。显然,margin更大,则分类正确的确信度更高(与超平面的距离表示分类的确信度,距离越远则分类正确的确信度越高)。通过计算容易得到:
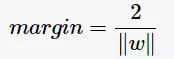
从上图中可观察到:margin以外的样本点对于确定分离超平面没有贡献,换句话说,SVM是有很重要的训练样本(支持向量)所确定的。至此,SVM分类问题可描述为在全部分类正确的情况下,最大化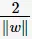 (等价于最小化
(等价于最小化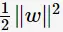 );线性分类的约束最优化问题
);线性分类的约束最优化问题

对每一个不等式约束引进拉格朗日乘子(Lagrange multiplier)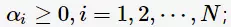 构造拉格朗日函数(Lagrange function):
构造拉格朗日函数(Lagrange function):
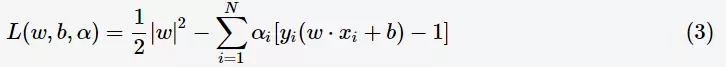
根据拉格朗日对偶性,原始的约束最优化问题可等价于极大极小的对偶问题:
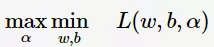
将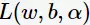 对
对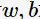 求偏导并令其等于0,则
求偏导并令其等于0,则
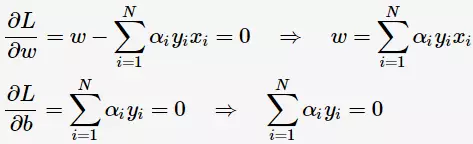
将上述式子代入拉格朗日函数(3)中,对偶问题转为
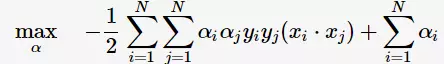
等价于最优化问
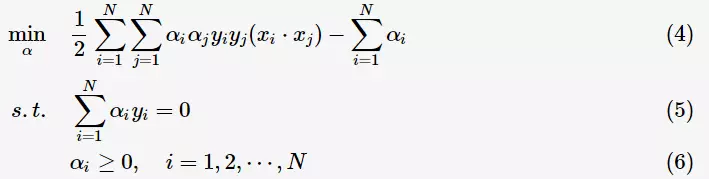
线性可分是理想情形,大多数情况下,由于噪声或特异点等各种原因,训练样本是线性不可分的。因此,需要更一般化的学习算法。
2.线性不可分
线性不可分意味着有样本点不满足约束条件(2),为了解决这个问题,对每个样本引入一个松弛变量 这样约束条件变为:
这样约束条件变为:
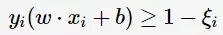
目标函数则变为

其中,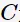 为惩罚函数,目标函数有两层含义:
为惩罚函数,目标函数有两层含义:
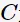 为调节二者的参数。通过构造拉格朗日函数并求解偏导(具体推导略去),可得到等价的对偶问题:
为调节二者的参数。通过构造拉格朗日函数并求解偏导(具体推导略去),可得到等价的对偶问题:
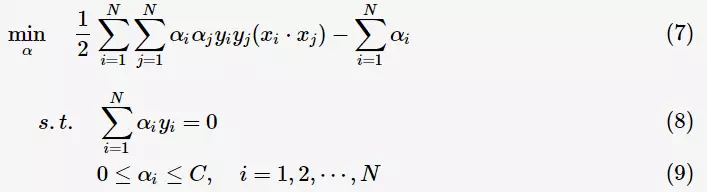
与上一节中线性可分的对偶问题相比,只是约束条件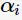 发生变化,问题求解思路与之类似。
发生变化,问题求解思路与之类似。
3.非线性
对于非线性问题,线性SVM不再适用了,需要非线性SVM来解决了。解决非线性分类问题的思路,通过空间变换ϕ(一般是低维空间映射到高维空间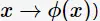 后实现线性可分,在下图所示的例子中,通过空间变换,将左图中的椭圆分离面变换成了右图中直线。
后实现线性可分,在下图所示的例子中,通过空间变换,将左图中的椭圆分离面变换成了右图中直线。

在SVM的等价对偶问题中的目标函数中有样本点的内积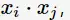 在空间变换后则是
在空间变换后则是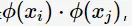 由于维数增加导致内积计算成本增加,这时核函数(kernel function)便派上用场了,将映射后的高维空间内积转换成低维空间的函数:
由于维数增加导致内积计算成本增加,这时核函数(kernel function)便派上用场了,将映射后的高维空间内积转换成低维空间的函数:
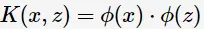
将其代入一般化的SVM学习算法的目标函数(7)中,可得非线性SVM的最优化问题:
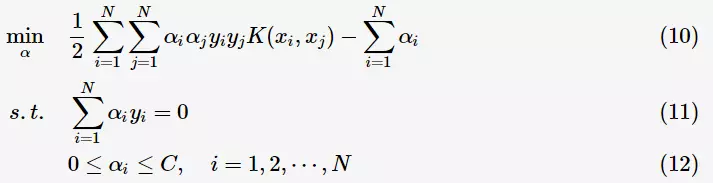
4.参考资料
[1] 李航,《统计学习方法》.
[2] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

