作者简介:
Treant 人工智能爱好者社区专栏作者
博客专栏:https://www.cnblogs.com/en-heng
1.关联分析
关联分析是一类非常有用的数据挖掘方法,能从数据中挖掘出潜在的关联关系。比如,在著名的购物篮事务(market basket transactions)问题中,

关联分析则被用来找出此类规则:顾客在买了某种商品时也会买另一种商品。在上述例子中,大部分都知道关联规则:{Diapers} → {Beer};即顾客在买完尿布之后通常会买啤酒。后来通过调查分析,原来妻子嘱咐丈夫给孩子买尿布时,丈夫在买完尿布后通常会买自己喜欢的啤酒。但是,如何衡量这种关联规则是否靠谱呢?下面给出了度量标准。
关联规则可以描述成:项集 → 项集。项集 出现的事务次数(亦称为support count)定义为:
出现的事务次数(亦称为support count)定义为:
其中,表示某个事务(TID),表示事务的集合。关联规则的支持度(support):
支持度刻画了项集的出现频次。置信度(confidence)定义如下:
对概率论稍有了解的人,应该看出来:置信度可理解为条件概率度量在已知事务中包含了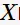 时包含
时包含 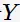 的概率。
的概率。
对于靠谱的关联规则,其支持度与置信度均应大于设定的阈值。那么,关联分析问题即等价于:对给定的支持度阈值min_sup、置信度阈值min_conf,找出所有的满足下列条件的关联规则:
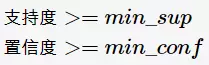
把支持度大于阈值的项集称为频繁项集(frequent itemset)。因此,关联规则分析可分为下列两个步骤:
生成频繁项集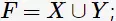
在频繁项集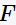 中,找出所有置信度大于最小置信度的关联规则
中,找出所有置信度大于最小置信度的关联规则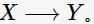
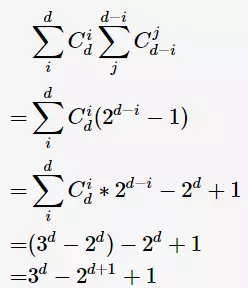
如果采用暴力方法,穷举所有的关联规则,找出符合要求的规则,其时间复杂度将达到指数级。因此,我们需要找出复杂度更低的算法用于关联分析。
2. Apriori算法
Agrawal与Srikant提出Apriori算法,用于做快速的关联规则分析。
根据支持度的定义,得到如下的先验定理:
定理1:如果一个项集是频繁的,那么其所有的子集(subsets)也一定是频繁的。
这个比较容易证明,因为某项集的子集的支持度一定不小于该项集。
定理2:如果一个项集是非频繁的,那么其所有的超集(supersets)也一定是非频繁的。
定理2是上一条定理的逆反定理。根据定理2,可以对项集树进行如下剪枝:
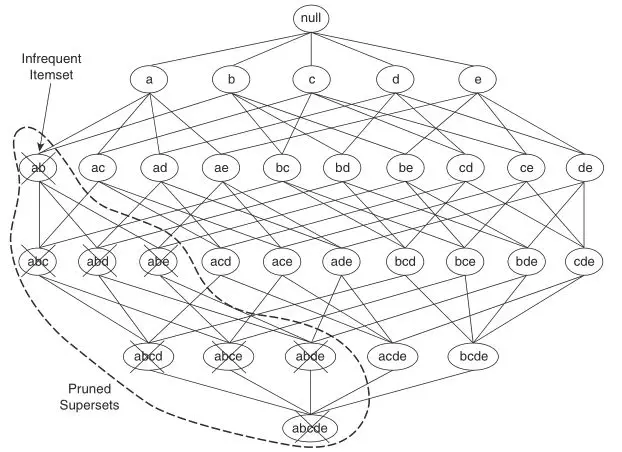
项集树共有项集数: 显然,用穷举的办法会导致计算复杂度太高。对于大小为
显然,用穷举的办法会导致计算复杂度太高。对于大小为 的频繁项集
的频繁项集 如何计算大小为
如何计算大小为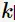 的频繁项集
的频繁项集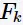 呢?Apriori算法给出了两种策略:
呢?Apriori算法给出了两种策略:
 方法。之所以没有选择
方法。之所以没有选择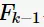 与(所有)1项集生成
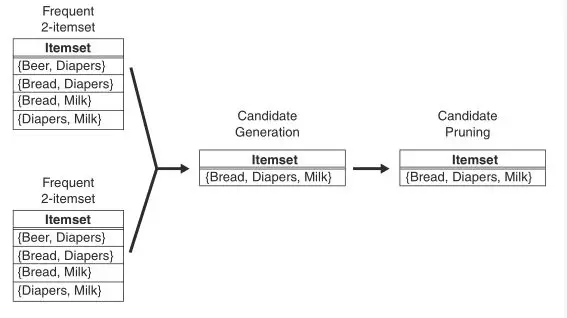
与(所有)1项集生成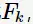 是因为为了满足定理2。下图给出由频繁项集
是因为为了满足定理2。下图给出由频繁项集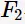 与
与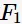
生成候选项集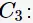

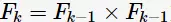 方法。选择前
方法。选择前 项均相同的
项均相同的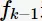
进行合并,生成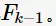 当然,
当然,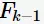 的所有
的所有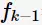 都是有序排列的。之所以要求前
都是有序排列的。之所以要求前 项均相同,是因为为了确保
项均相同,是因为为了确保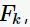 的
的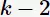 项都是频繁的。下图给出由两个频繁项集
项都是频繁的。下图给出由两个频繁项集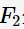 生成候选项集
生成候选项集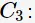
生成频繁项集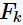 的算法如下:
的算法如下:

关联规则生成
关联规则是由频繁项集生成的,即对于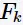 找出项集
找出项集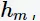 使得规则
使得规则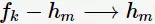
的置信度大于置信度阈值。同样地,根据置信度定义得到如下定理:
定理3:如果规则 不满足置信度阈值,则对于
不满足置信度阈值,则对于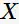 的子集
的子集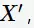 规则
规则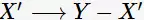 也不满足置信度阈值。
也不满足置信度阈值。
根据定理3,可对规则树进行如下剪枝:
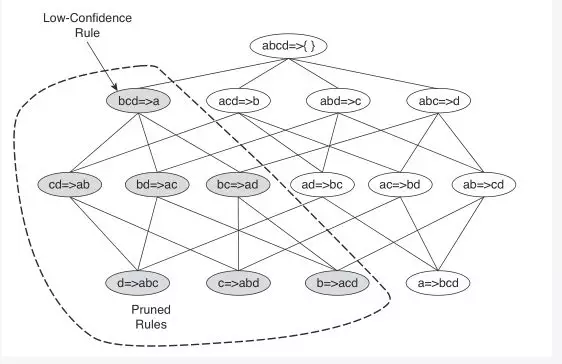
关联规则的生成算法如下:

3. 参考资料
[1] Pang-Ning Tan, Michael Steinbach, Vipin Kumar, Introduction to Data Mining.
往期回顾:
【十大经典数据挖掘算法】C4.5
【十大经典数据挖掘算法】k-means
【十大经典数据挖掘算法】SVM
【从传统方法到深度学习】图像分类

公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

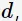 则所有关联规则的数量:
则所有关联规则的数量: