
作者简介
作者:张磊 机器学习爱好者 ,人工智能爱好者社区专栏作家
个人网站:novasky.top
GitHub:https://github.com/zlxy9892
1 决策树的基本模型
在很多初学者开始学习机器学习或者数据挖掘时,大多数教程都会从决策树 (decision tree) 开始,决策树是一类常见的机器学习方法,可以帮助我们解决分类与回归两类问题。以决策树的作为学习的起点原因很简单,因为它非常符合人类处理问题的方式,所以决策方式显得极为自然,且模型的解释性很好,能够让使用者知道为什么这个决策结果是我所希望的那样 (树形结构简单易懂)。
分类决策数模型是一种描述对实例进行分类的树形结构。决策树由结点 (node) 和有向边 (directed edge) 组成。结点包含了一个根结点 (root node)、若干个内部结点 (internal node) 和若干个叶结点 (leaf node)。内部结点表示一个特征或属性,叶结点表示一个类别。
那么,最为关键的问题就是,如何根据已知的数据集,来进行决策树的学习,构造一颗泛化能力强,即处理未见示例能力强的决策树。为此,决策树学习通常包括 3 个步骤:特征选择、决策树的生成、决策树的修剪。现有的关于决策树学习的主要思想主要包含以下 3 个研究成果:
由 Quinlan 在 1986 年提出的 ID3 算法
由 Quinlan 在 1993 年提出的 C4.5 算法
由 Breiman 等人在 1984 年提出的 CART 算法
2 划分选择
决策树学习的过程中,最为关键的就是如何选择最优划分属性。一般而言,随着划分过程不断进行,我们希望决策树的分支结点所包含的样本尽可能属于同一类别,即结点的 “纯度” (purity)越来越高。
2.1 信息增益
“信息熵” (information entropy) 是度量样本集合纯度最常用的一种指标。假定当前样本集合 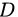 中第
中第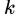 类样本所占的比例为
类样本所占的比例为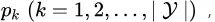 则
则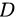 的信息熵定义为:
的信息熵定义为:

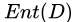 的值越小,则
的值越小,则 的纯度越高。信息熵表达一个数据所包含的信息量,或者说是信息的复杂程度、不确定性程度。例如当某一随机变量只取 0, 1 两个值时,当取 0 的概率 = 取 1 的概率 = 0.5 时,信息熵达到最大值,值为 1,可以看做此时系统的不确定性最高;当某一取值的概率为 0,另一取值概率为 1 时,此时可以认为系统是完全确定的,因为只能取到 0 或 1,相应的,信息熵取值为 0。
的纯度越高。信息熵表达一个数据所包含的信息量,或者说是信息的复杂程度、不确定性程度。例如当某一随机变量只取 0, 1 两个值时,当取 0 的概率 = 取 1 的概率 = 0.5 时,信息熵达到最大值,值为 1,可以看做此时系统的不确定性最高;当某一取值的概率为 0,另一取值概率为 1 时,此时可以认为系统是完全确定的,因为只能取到 0 或 1,相应的,信息熵取值为 0。
假设样本集 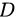 中某一离散属性
中某一离散属性  有
有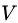 个可能的取值
个可能的取值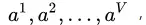 若使用
若使用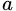 来对样本集
来对样本集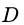 进行划分,则会产生
进行划分,则会产生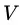 个分支结点 (注意:这里是默认把离散属性的每个可能的取值都进行划分),其中第
个分支结点 (注意:这里是默认把离散属性的每个可能的取值都进行划分),其中第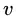 个分支结点包含了
个分支结点包含了 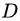 中所有在属性
中所有在属性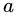 上取值为
上取值为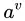 的样本,记为
的样本,记为 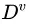 。我们可根据信息熵的定义计算出
。我们可根据信息熵的定义计算出 的信息熵。再考虑到不同分支结点所包含的样本数不同,给分支结点赋予权重
的信息熵。再考虑到不同分支结点所包含的样本数不同,给分支结点赋予权重 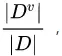 即样本数越多的分支结点的影响越大,于是可以计算出用属性
即样本数越多的分支结点的影响越大,于是可以计算出用属性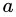 对样本集
对样本集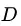 进行划分所获得的 “信息增益“ (information gain):
进行划分所获得的 “信息增益“ (information gain):
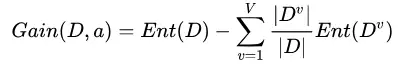
一般而言,信息增益越大,则意味着使用属性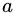 来进行划分所获得的 "纯度提升" 越大。因此,我们可以用信息增益来进行决策树的划分属性选择。
来进行划分所获得的 "纯度提升" 越大。因此,我们可以用信息增益来进行决策树的划分属性选择。
著名的 ID3 决策树学习算法就是以信息增益为准则来选择划分属性。
2.2 信息增益率
使用上述的信息增益来作为划分准则是否就一定是最优策略呢?我们试想这样的情况,若我们获取的样本集数据中包含了一条属性是每个样本的 ID 号,那么根据信息增益的计算公式可以得到,当使用 ID 号作为划分属性时,它的信息增益率极高,这很容易理解:“ID 号” 代表了对每个样本的唯一标识,通过它来划分样本集,那么每个分支结点仅包含一个样本,这些分支结点的纯度达到了最大。然而,这样的决策树显然并非我们所希望得到的,因为它不具备泛化能力,无法对新样本进行有效预测。
仔细分析来看,信息增益准则对可取值数目较多的属性有所偏好,为减少这种可能带来的不利影响,著名的 C4.5 决策树算法不直接使用信息增益,而是使用 “增益率” (gain ratio) 来选择最优划分属性。在信息增益计算公式的基础上,增益率定义为:
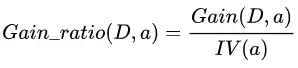
其中,
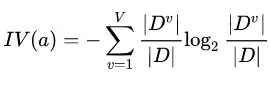
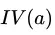 称为属性
称为属性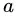 的 “固定值” (intrinsic value),对比信息熵公式可以发现,其实
的 “固定值” (intrinsic value),对比信息熵公式可以发现,其实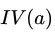 就是等同于特征
就是等同于特征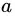 的信息熵 (有些书籍将其记为
的信息熵 (有些书籍将其记为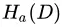 ),其中的
),其中的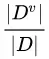 正是对属性
正是对属性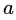 取值为
取值为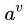 的概率的极大似然估计。那么,若属性
的概率的极大似然估计。那么,若属性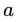 的可能取值数目越多 (即
的可能取值数目越多 (即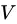 越大),则
越大),则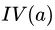 的值通常会越大。
的值通常会越大。
需要注意的是,增益率准则对可能取值数目较少的属性有所偏好,因此,C4.5 算法并不是直接选择增益率最大的候选划分属性,而是使用了一个启发式策略:先从候选划分属性中找出信息增益高于平均水平的属性,再从中选择增益率最高的。
2.3 基尼指数
分类与回归树 (classification and regression tree, CART) 模型,是应用很广泛的决策树学习方法,从其命名可以看出,它可以解决分类和回归两类问题。与 ID3 和 C4.5 不同之处在于,CART 使用 “基尼指数” (Gini index) 来选择划分属性。数据集 的纯度可用基尼值来度量:
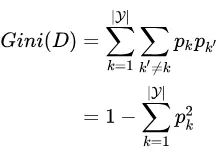
也可以写成:
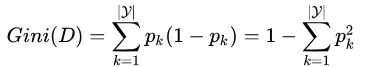
其中, 为数据集
为数据集 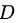 中输出值为
中输出值为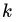 的概率,根据实际数据,可采用
的概率,根据实际数据,可采用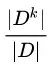 来进行估计。直观来说,
来进行估计。直观来说,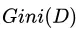 反映了从数据集
反映了从数据集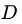 中随机抽取两个样本,其类别标记不一致的概率。因此,
中随机抽取两个样本,其类别标记不一致的概率。因此,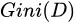 越小,则数据集
越小,则数据集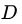 的纯度越高。
的纯度越高。
基于此,对于属性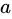 的基尼指数定义为:
的基尼指数定义为:
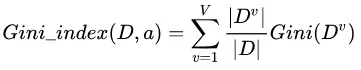
于是,我们在候选属性集合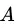 中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即:
中,选择那个使得划分后基尼指数最小的属性作为最优划分属性,即:
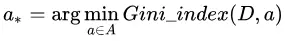
2.4 连续值处理
到目前为止,我们仅讨论了基于离散属性来生成决策树。现实学习任务中常会遇到连续属性,因此,有必要讨论如何在决策树学习中使用连续属性。
借助连续属性离散化技术,最简单的策略是采用二分法 (bi-partition) 对连续属性进行处理,这正是 C4.5 决策树算法中采用的机制,CART 也采用该策略。
给定样本集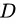 和连续属性
和连续属性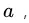 假定
假定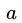 在
在 上出现了
上出现了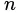 个不同的取值,将这些取值从小到大进行排序,记为
个不同的取值,将这些取值从小到大进行排序,记为 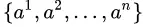 。基于划分点
。基于划分点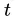 可将
可将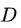 分为两个子集,记为
分为两个子集,记为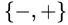 。显然,对于属性取值
。显然,对于属性取值 与
与 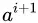 来说, 在区间
来说, 在区间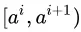 中取任意值所产生的划分结果相同。因此,对连续属性
中取任意值所产生的划分结果相同。因此,对连续属性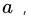 我们可考察包含
我们可考察包含 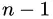 个元素的候选划分点集合:
个元素的候选划分点集合:

即把每个区间的中位点作为候选划分点。然后,我们就可像离散属性值一样来考察这些划分点,选取最优的划分点进行样本集合的划分。
在 CART 应用于回归问题时,同样也是采用了二分法,将划分的两个子集分别求得输出量 的均值,以此作为输出值的估计,记为
的均值,以此作为输出值的估计,记为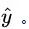 在寻找最优切分点时,通过计算两个子区域的估计值与每个输出的真值之间的平方误差,选取使得平方误差总和最小的作为最优切分点。具体的,求解:
在寻找最优切分点时,通过计算两个子区域的估计值与每个输出的真值之间的平方误差,选取使得平方误差总和最小的作为最优切分点。具体的,求解:
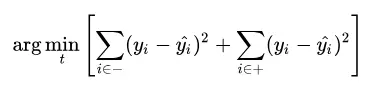
使用该方法构建的回归树也称为最小二乘回归树。
3 关于剪枝处理
剪枝 (pruning) 是决策树学习算法对付 “过拟合” 的主要手段。在决策树学习中,为了尽可能正确分类训练样本,结点划分过程将不断重复,有时会造成决策树分支过多,这时就可能因针对训练样本学得 “太好” 了,以至于把训练集自身的一些特点当作所有数据都具有的一般性质而导致过拟合。因此,可通过主动去掉一些分支来降低过拟合的风险。
决策树剪枝的基本策略有 “预剪枝” (prepruning) 和 “后剪枝” (postpruning)。
4 参考文献与相关资料
Quinlan, J. R. (1986). Induction of decision trees. Machine Learning, 1 (1), 81-106.
Quinlan, J. R. (1992). C4.5: programs for machine learning. ,1.
Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and regression trees.
往期回顾:
机器学习中的特征选择
SVD-矩阵奇异值分解 —— 原理与几何意义
对数几率回归 —— Logistic Regression
BP 神经网络 —— 逆向传播的艺术
极大似然估计 —— Maximum Likelihood Estimation
公众号后台回复关键词学习
回复 免费 获取免费课程
回复 直播 获取系列直播课
回复 Python 1小时破冰入门Python
回复 人工智能 从零入门人工智能
回复 深度学习 手把手教你用Python深度学习
回复 机器学习 小白学数据挖掘与机器学习
回复 贝叶斯算法 贝叶斯与新闻分类实战
回复 数据分析师 数据分析师八大能力培养
回复 自然语言处理 自然语言处理之AI深度学习

