作者:大树2个人博客:http://www.cnblogs.com/csj007523/
往期回顾:
电力AI大赛|机器学习处理流程、特征工程,模型设计实例
机器学习,深度学习相关介绍
机器学习 — 推荐系统
Kaggle上有很多有意思的项目,大家得空可以试着做一做,其中有个关于香港赛马预测的项目,若大家做的效果好,预测的结果准确度高的话,可以轻松的 get money 了,记得香港报纸有报道说有个大学教授通过统计学建模进行赛马赢了5000万港币,相信通过机器学习,深度学习,一定可以提高投注的准确度,恭喜大家发财阿,加油学吧~~
Kaggle自行车租赁预测比赛,这是一个连续值预测的问题,也就是我们说的机器学习中的回归问题,咱们一起来看看这个问题。这是一个城市自行车租赁系统,提供的数据为2年内华盛顿按小时记录的自行车租赁数据,其中训练集由每个月的前19天组成,测试集由20号之后的时间组成(需要我们自己去预测)。Kaggle自行车租赁预测比赛:https://www.kaggle.com/c/bike-sharing-demand
加载数据
数据分析
特征数据提取
准备训练集数据,测试集数据
模型选择,先用自己合适算法跑一个baseline的model出来,再进行后续的分析步骤,一步步提高。
参数调优,用Grid Search找最好的参数
用模型预测打分
#load data, review the fild and data type
import pandas as pd
df_train = pd.read_csv('kaggle_bike_competition_train.csv',header=0)
df_train.head(5)
df_train.dtypes

#来处理时间,因为它包含的信息总是非常多的,毕竟变化都是随着时间发生的嘛
df_train.head()
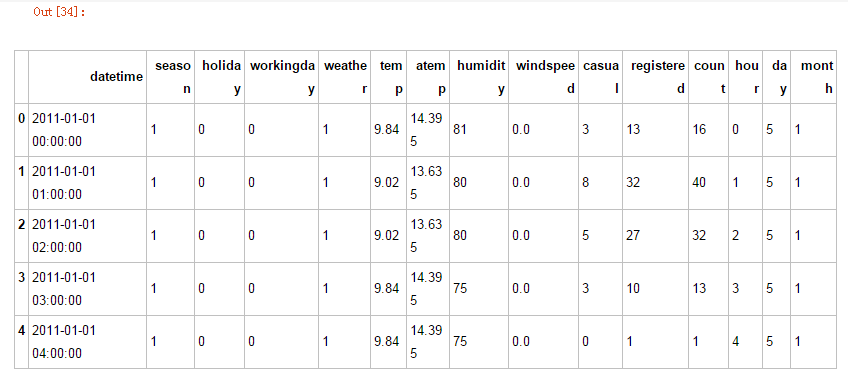
df_train['hour']=pd.DatetimeIndex(df_train.datetime).hour
df_train['day']=pd.DatetimeIndex(df_train.datetime).dayofweek
df_train['month']=pd.DatetimeIndex(df_train.datetime).month
#other method
# df_train['dt']=pd.to_datetime(df_train['datetime'])# df_train['day_of_week']=df_train['dt'].apply(lambda x:x.dayofweek)
# df_train['day_of_month']=df_train['dt'].apply(lambda x:x.day)
df_train.head()

#提取相关特征字段# df = df_train.drop(['datetime','casual','registered'],axis=1,inplace=True)df_train = df_train[['season','holiday','workingday','weather','temp','atemp', 'humidity','windspeed','count','month','day','hour']]#df=df_train['datetime']df_train.head(5)
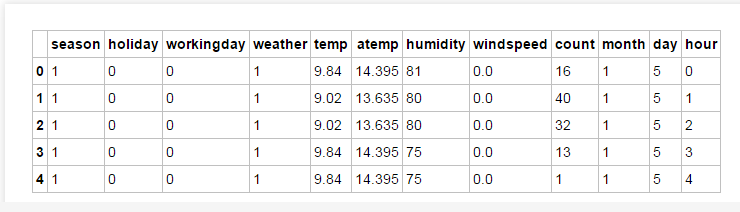
准备训练集数据,测试集数据:
1. df_train_target:目标,也就是count字段。
2. df_train_data:用于产出特征的数据
df_train_target = df_train['count'].values
print(df_train_target.shape)
df_train_data = df_train.drop(['count'],axis =1).values
print(df_train_data.shape)
算法
咱们依旧会使用交叉验证的方式(交叉验证集约占全部数据的20%)来看看模型的效果,我们会试 支持向量回归/Suport Vector Regression, 岭回归/Ridge Regression 和随机森林回归/Random Forest Regressor。每个模型会跑3趟看平均的结果。
from sklearn import linear_model
from sklearn import cross_validation
from sklearn import svm
from sklearn.ensemble import RandomForestRegressor
from sklearn.learning_curve import learning_curve
from sklearn.grid_search import GridSearchCV
from sklearn.metrics import explained_variance_score
# 切分一下数据(训练集和测试集)
cv = cross_validation.ShuffleSplit(len(df_train_data), n_iter=3, test_size=0.2,
random_state=0)
# 各种模型来一圈
print("岭回归")
for train, test in cv:
svc = linear_model.Ridge().fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]),
svc.score(df_train_data[test], df_train_target[test])))
print("支持向量回归/SVR(kernel='rbf',C=10,gamma=.001)")
for train, test in cv:
svc = svm.SVR(kernel ='rbf', C = 10, gamma = .001).fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]),
svc.score(df_train_data[test], df_train_target[test])))
print("随机森林回归/Random Forest(n_estimators = 100)")
for train, test in cv:
svc = RandomForestRegressor(n_estimators = 100).fit(df_train_data[train], df_train_target[train])
print("train score: {0:.3f}, test score: {1:.3f}\n".format( svc.score(df_train_data[train], df_train_target[train]), svc.score(df_train_data[test], df_train_target[test])))

随机森林回归获得了最佳结果不过,参数设置得是不是最好的,这个我们可以用GridSearch来帮助测试,找最好的参数
X = df_train_data
y = df_train_target
X_train, X_test, y_train, y_test = cross_validation.train_test_split(
X, y, test_size=0.2, random_state=0)
tuned_parameters = [{'n_estimators':[10,100,500,550]}]
scores = ['r2']
for score in scores:
print(score)
clf = GridSearchCV(RandomForestRegressor(), tuned_parameters, cv=5, scoring=score)
clf.fit(X_train, y_train)
print("最佳参数找到了:")
print("")
#best_estimator_ returns the best estimator chosen by the search
print(clf.best_estimator_)
print("")
print("得分分别是:")
print("")
#grid_scores_的返回值:
# * a dict of parameter settings
# * the mean score over the cross-validation folds
# * the list of scores for each fold
for params, mean_score, scores in clf.grid_scores_:
print("%0.3f (+/-%0.03f) for %r"
% (mean_score, scores.std() / 2, params))
print("")

Grid Search帮挑参数还是蛮方便的, 而且要看看模型状态是不是,过拟合or欠拟合我们发现n_estimators=500,550时,拟合得最好。
