作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
机器学习综述
从零开始学人工智能(17)--数学 · 神经网络(一)· 前向传导
从零开始学人工智能(18)--数学 · 神经网络(二)· BP(反向传播)
从零开始学人工智能(19)--数学 · 神经网络(三)· 损失函数
从零开始学人工智能(20)--数学 · 神经网络(四)· Normalize
从零开始学人工智能(21)--数学 · CNN · 从 NN 到 CNN
GitHub 地址: https://github.com/carefree0910/MachineLearning/blob/master/b_NaiveBayes/Vectorized/Basic.py
(话说知乎居然没有朴素贝叶斯的话题……呜呼 (ノへ ̄、))
========== 写在前面的话 ==========
对于我个人而言、光看这么一个框架是非常容易摸不着头脑的
毕竟之前花了许多时间在数学部分讲的那些算法完全没有体现在这个框架中、取而代之的是一些我抽象出来的和算法无关的结构性部分……
虽然从逻辑上来说应该先说明如何搭建这个框架,但从容易理解的角度来说、个人建议先不看这章的内容而是先看后续的实现具体算法的章节(还在更新中☹)
然后如果那时有不懂的定义、再对照这一章的相关部分来看
不过如果是对朴素贝叶斯算法非常熟悉的观众老爷的话、直接看本章的抽象会引起一些共鸣也说不定 ( σ'ω')σ
========== 分割线的说 ==========
所谓的框架、自然是指三种朴素贝叶斯模型(离散、连续、混合)共性的抽象了。由于贝叶斯决策论就摆在那里、不难知道如下功能是通用的:
计算类别的先验概率
训练出一个能输出后验概率的决策函数
利用该决策函数进行预测和评估
虽说朴素贝叶斯大体上来说只是简单的计数、但是想以比较高的效率做好这件事却比想象中的要麻烦不少(说实话麻烦到我有些不想讲的程度了)
总之先来看看这个框架的初始化步骤吧(前方……高能?!)
class NaiveBayes(ClassifierBase, metaclass=ClassifierMeta):
"""
初始化结构
self._x, self._y:记录训练集的变量
self._data:核心数组,存储实际使用的条件概率的相关信息
self._func:模型核心——决策函数,能够根据输入的x、y输出对应的后验概率
self._n_possibilities:记录各个维度特征取值个数的数组
self._labelled_x:记录按类别分开后的输入数据的数组
self._label_zip:记录类别相关信息的数组,视具体算法、定义会有所不同
self._cat_counter:核心数组,记录第i类数据的个数(cat是category的缩写)
self._con_counter:核心数组,用于记录数据条件概率的原始极大似然估计
self.label_dic:核心字典,用于记录数值化类别时的转换关系
self._feat_dics:核心字典,用于记录数值化各维度特征(feat)时的转换关系
"""
def __init__(self):
self._x = self._y = None
self._data = self._func = None
self._n_possibilities = None
self._labelled_x = self._label_zip = None
self._cat_counter = self._con_counter = None
self.label_dic = self._feat_dics = None
其中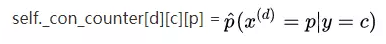
(con是conditional的缩写)

(注释比代码还多是想闹哪样???(╯‵□′)╯︵┻━┻)
总之和我一样懵逼了的观众老爷们可以先不太在意这一坨是什么玩意儿,毕竟这些东西是抽象程度比较高的属性……等结合具体算法时、这些属性的意义可能就会明确得多
下面进入正题……首先来看怎么计算先验概率(直接利用上面的 self._cat_counter属性即可)
def get_prior_probability(self, lb=1):
return [(_c_num + lb) / (len(self._y) + lb * len(self._cat_counter))
for _c_num in self._cat_counter]
其中参数 lb 即为平滑项,默认为 1 意味着默认使用拉普拉斯平滑
然后看看训练步骤能如何进行抽象
def fit(self, x=None, y=None, sample_weight=None, lb=1):
if x is not None and y is not None:
self.feed_data(x, y, sample_weight)
self._func = self._fit(lb)
(岂可修不就只是调用了一下 feed_data 方法而已嘛还说成抽象什么的行不行啊!)
其中用到的 feed_data 方法是留给各个子类定义的、进行数据预处理的方法;然后 self._fit 可说是核心训练函数、它会返回我们的决策函数 self._func
最后看看怎样利用 self._func 来预测未知数据
def predict(self, x, get_raw_result=False):
# 调用相应方法进行数据预处理(这在离散型朴素贝叶斯中尤为重要)
x = self._transfer_x(x)
# 只有将算法进行向量化之后才能做以下的步骤
m_arg, m_probability = np.zeros(len(x), dtype=np.int8), np.zeros(len(x))
# len(self._cat_counter) 其实就是类别个数
for i in range(len(self._cat_counter)):
# 注意这里的 x 其实是矩阵、p 是对应的“后验概率矩阵”:p = p(y=i|x)
# 这意味着决策函数 self._func 需要支持矩阵运算
p = self._func(x, i)
# 利用 Numpy 进行向量化操作
_mask = p > m_probability
m_arg[_mask], m_probability[_mask] = i, p[_mask]
# 利用转换字典 self.label_dic 输出决策
# 参数 get_raw_result 控制该函数是输出预测的类别还是输出相应的后验概率
if not get_raw_result:
return np.array([self.label_dic[arg] for arg in m_arg])
return m_probability
其中 self.label_dic 大概是这个德性的:比如训练集的类别空间为 {red, green, blue} 然后第一个样本的类别是 red 且第二个样本的类别是 blue、那么就有
self.label_dic = np.array(["red", "blue", "green"])
以上就是朴素贝叶斯模型框架的搭建,下一章会在该框架的基础上实现离散型朴素贝叶斯模型
希望观众老爷们能不讨厌ヽ(・ω・。)ノ
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

