作者:射命丸咲 Python 与 机器学习 爱好者
知乎专栏:https://zhuanlan.zhihu.com/carefree0910-pyml
个人网站:http://www.carefree0910.com
往期阅读:
机器学习综述
从零开始学人工智能(17)--数学 · 神经网络(一)· 前向传导
从零开始学人工智能(18)--数学 · 神经网络(二)· BP(反向传播)
从零开始学人工智能(19)--数学 · 神经网络(三)· 损失函数
我们在Python · 神经网络(三*)· 网络这里曾经介绍过附加层(特殊层)SubLayer的概念,这一章我们则会较为详细地介绍一下十分常用的 SubLayer 之一——Normalize(当然直接看原 paper 是最好的,因为我虽然一直在用这玩意儿但真的很难说有深刻的理解…… ( σ'ω')σ)
Normalize 这个特殊层结构的学名叫 Batch Normalization、常简称为 BN,顾名思义,它用于对每个 Batch对应的数据进行规范化处理。这样做的意义是直观的:对于 NN、CNN 乃至任何机器学习分类器来说,其目的可以说都是从训练样本集中学出样本在样本空间中的分布、从而可以用这个分布来预测未知数据所属的类别。如果不对每个 Batch 的数据进行任何操作的话,不难想象它们彼此对应的“极大似然分布(极大似然估计意义下的分布)”是各不相同的(因为训练集只是样本空间中的一个小抽样、而 Batch 又只是训练集的一个小抽样);这样的话,分类器在接受每个 Batch 时都要学习一个新的分布、然后最后还要尝试从这些分布中总结出样本空间的总分布,这无疑是相当困难的。如果存在一种规范化处理方法能够使每个 Batch 的分布都贴近真实分布的话、对分类器的训练来说无疑是至关重要的
传统的做法是对输入X进行第归一化处理、亦即:
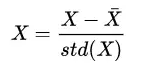
其中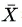 表示X的均值、std(X)表示X的标准差(Standard Deviation)。这种做法虽然能保证输入数据的质量、但是却无法保证 NN 里面中间层输出数据的质量。试想 NN 中的第一个隐藏层L2,它接收的输入
表示X的均值、std(X)表示X的标准差(Standard Deviation)。这种做法虽然能保证输入数据的质量、但是却无法保证 NN 里面中间层输出数据的质量。试想 NN 中的第一个隐藏层L2,它接收的输入 是输入层L1的输出
是输入层L1的输出 和权值矩阵
和权值矩阵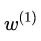 相乘后、加上偏置量
相乘后、加上偏置量 后的结果;在训练过程中,虽然的质量有保证,但由于和在训练过程中会不断地被更新、所以
后的结果;在训练过程中,虽然的质量有保证,但由于和在训练过程中会不断地被更新、所以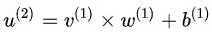 的分布其实仍然不断在变。换句话说的质量其实就已经没有保证了。
的分布其实仍然不断在变。换句话说的质量其实就已经没有保证了。
BN 打算解决的正是随着前向传导算法的推进、得到的数据的质量会不断变差的问题,它能通过对中间层数据进行某种规范化处理以达到类似对输入归一化处理的效果。换句话说,Normalize 的核心思想正在于如何把父层的输出进行某种“归一化”处理,下面我们就简单看看它具体是怎么做到这一点的。
首先需要指出的是,简单地将每层得到的数据进行上述归一化操作显然是不可行的、因为这样会破坏掉每层自身学到的数据特征。设想如果某一层 学到了“数据基本都分布在样本空间的边缘”这一特征,这时如果强行做归一化处理并把数据都中心化的话、无疑就摈弃了
学到了“数据基本都分布在样本空间的边缘”这一特征,这时如果强行做归一化处理并把数据都中心化的话、无疑就摈弃了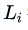 所学到的、可能是非常有价值的知识
所学到的、可能是非常有价值的知识
为了使得中心化之后不破坏 Layer 本身学到的特征、BN 采取了一个简单却十分有效的方法:引入两个可以学习的“重构参数”以期望能够从中心化的数据重构出 Layer 本身学到的特征。具体而言:
BN 的核心即在于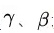 这两个参数的应用上。关于如何利用反向传播算法来更新这两个参数的数学推导会稍显繁复、我们就不展开叙述了,取而代之、我们会直接利用 Tensorflow 来进行相关的实现
这两个参数的应用上。关于如何利用反向传播算法来更新这两个参数的数学推导会稍显繁复、我们就不展开叙述了,取而代之、我们会直接利用 Tensorflow 来进行相关的实现
需要指出的是、对于算法中均值和方差的计算其实还有一个被广泛使用的小技巧,该小技巧某种意义上可以说是用到了“动量”的思想:我们会分别维护两个储存“运行均值(Running Mean)”和“运行方差(Running Variance)”的变量。具体而言:

最后提三点使用 Normalize 时需要注意的事项:
无论是哪种算法、BN 的训练过程和预测过程的表现都是不同的。具体而言,训练过程和算法中所叙述的一致、均值和方差都是根据当前 Batch 来计算的;但测试过程中的均值和方差不能根据当前 Batch 来计算、而应该根据训练样本集的某些特征来进行计算。对于上面第二种算法来说,天然就是很好的、可以用来当测试过程中的均值和方差的变量,对于第一种算法而言就需要额外的计算(别问我怎么进行额外的计算,我不会……)
对于 Normalize 这个特殊层结构来说、偏置量是一个冗余的变量;这是因为规范化操作(去均值)本身会将偏置量的影响抹去、同时 BN 本身的参数可以说正是破坏对称性的参数,它能比较好地完成原本偏置量所做的工作
Normalize 这个层结构是可以加在许多不同地方的(如下图所示的 A、B 和 C 处),原论文将它加在了 A 处、但其实现在很多主流的深层 CNN 结构都将它加在了 C 处;相对而言、加在 B 处的做法则会少一些:
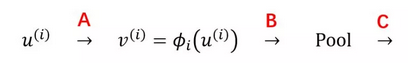
Normalize 的相关实现会在 CNN 系列的文章里面进行说明,敬请期待 ( σ'ω')σ
希望观众老爷们能够喜欢~
公众号后台回复关键词学习
回复 人工智能 揭开人工智能的神秘面纱
回复 贝叶斯算法 贝叶斯算法与新闻分类
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 Python Python机器学习案例实战
回复 Spark 征服Spark第一季
回复 kaggle 机器学习kaggle案例
回复 大数据 大数据系列视频
回复 数据分析 数据分析人员的转型
回复 数据挖掘 数据挖掘与人工智能
回复 机器学习 R&Python机器学习
回复 阿里数据 阿里数据系列课程
回复 R R&Python机器学习入门

