
这里来看一下,pandas中数据转换与合并的使用方法,刚刚学习了一下,很好用,就跟SQL里面一样。
1. 合并数据集
就是说,我们有2个数据集,想要将他们合并一下,就是SQL里面的关联查询,pandas里面用一个函数就行了
DataFrame.merge(right, how='inner', on=None, left_on=None, right_on=None, left_index=False, right_index=False, sort=False, suffixes=('_x', '_y'), copy=True, indicator=False)
Merge DataFrame objects by performing a database-style join operation by columns or indexes.
If joining columns on columns, the DataFrame indexes will be ignored. Otherwise if joining indexes on indexes or indexes on a column or columns, the index will be passed on.
熟练掌握几个参数就足够了,下面会依次介绍下
小例子
import pandas as pd
import numpy as np
a = pd.DataFrame({'key':list('bbccaa'),'data1':np.random.randint(0,10,size=6)})
b = pd.DataFrame({'key':list('abc'),'data2':np.random.randint(0,10,size=3)})
a
Out[18]:
data1 key
0 8 b
1 0 b
2 5 c
3 2 c
4 3 a
5 6 a
b
Out[19]:
data2 key
0 0 a
1 3 b
2 2 c上面是我们的原始数据集,一个a,一个b,key是相同的字段,可以用来关联,
a.merge(b)
Out[20]:
data1 key data2
0 8 b 3
1 0 b 3
2 5 c 2
3 2 c 2
4 3 a 0
5 6 a 0这个翻译成SQL,就是a join b on a.key=b.key(因为我们没有指定根据什么字段去关联,所以会使用a、b中名字一样的字段去关联)
我们当然可以手动指定关联的字段
on : label or list
Field names to join on. Must be found in both DataFrames. If on is None and not merging on indexes, then it merges on the intersection of the columns by default.
left_on : label or list, or array-like
Field names to join on in left DataFrame. Can be a vector or list of vectors of the length of the DataFrame to use a particular vector as the join key instead of columns
right_on : label or list, or array-like
Field names to join on in right DataFrame or vector/list of vectors per left_on docs
如果,数据集中,关联字段名称一样,直接使用on就行了,如果不一样,就可以分别使用left_on 和right_on
a.merge(b,on='key')
Out[21]:
data1 key data2
0 8 b 3
1 0 b 3
2 5 c 2
3 2 c 2
4 3 a 0
5 6 a 0
a.merge(b,left_on='key',right_on='key')
Out[22]:
data1 key data2
0 8 b 3
1 0 b 3
2 5 c 2
3 2 c 2
4 3 a 0
5 6 a 0如果关联字段又多个,就指定为数组就行了
c = pd.DataFrame({'lkey1':list('ab'),'lkey2':list('xy'),'ldata1':np.random.randint(0,10,size=2)})
d = pd.DataFrame({'rkey1':list('ab'),'rkey2':list('xy'),'ldata1':np.random.randint(0,10,size=2)})
c
Out[25]:
ldata1 lkey1 lkey2
0 8 a x
1 2 b y
d
Out[26]:
ldata1 rkey1 rkey2
0 5 a x
1 7 b y
#因为找不到名字一样的字段做关联,所以是空的结果(有一个字段是一样的,ldata1,但是都一样,刚刚d的名字忘改了......)
#正常找不到关联字段,是会报错的
c.merge(d)
Out[27]:
Empty DataFrame
Columns: [ldata1, lkey1, lkey2, rkey1, rkey2]
Index: []
#我们将组合建传入,即可
c.merge(d,left_on=['lkey1','lkey2'],right_on=['rkey1','rkey2'])
Out[28]:
ldata1_x lkey1 lkey2 ldata1_y rkey1 rkey2
0 8 a x 5 a x
1 2 b y 7 b y
#看下结果集,我们会发现,c和d中有一个同名的字段ldata1,这里默认加了后缀 _x,_y来表示区分
#我们也可以通过参数来指定后缀名称
suffixes : 2-length sequence (tuple, list, ...)
Suffix to apply to overlapping column names in the left and right side, respectively
c.merge(d,left_on=['lkey1','lkey2'],right_on=['rkey1','rkey2'],suffixes=['_left','_right'])
Out[29]:
ldata1_left lkey1 lkey2 ldata1_right rkey1 rkey2
0 8 a x 5 a x
1 2 b y 7 b y

我们再看下一个例子
e = pd.DataFrame({'key':list('bbccaadd'),'data':np.random.randint(0,10,size=8)})
f = pd.DataFrame({'key':list('abcx'),'data':np.random.randint(0,10,size=4)})
e
Out[32]:
data key
0 4 b
1 5 b
2 1 c
3 2 c
4 7 a
5 7 a
6 7 d
7 9 d
f
Out[33]:
data key
0 6 a
1 9 b
2 2 c
3 8 x
e.merge(f,on='key')
Out[34]:
data_x key data_y
0 4 b 9
1 5 b 9
2 1 c 2
3 2 c 2
4 7 a 6
5 7 a 6熟悉SQL的同学,会发现,上面的结果集市inner join之后的结果,SQL中,还有什么left join、right join之类的,pandas中也有的
how : {‘left’, ‘right’, ‘outer’, ‘inner’}, default ‘inner’
left: use only keys from left frame, similar to a SQL left outer join; preserve key order
right: use only keys from right frame, similar to a SQL right outer join; preserve key order
outer: use union of keys from both frames, similar to a SQL full outer join; sort keys lexicographically
inner: use intersection of keys from both frames, similar to a SQL inner join; preserve the order of the left keys
#左关联,e为主即包含全部数据,不管是否可以和f关联上
e.merge(f,on='key',how='left')
Out[35]:
data_x key data_y
0 4 b 9.0
1 5 b 9.0
2 1 c 2.0
3 2 c 2.0
4 7 a 6.0
5 7 a 6.0
6 7 d NaN
7 9 d NaN
#右为主,即f为主,
e.merge(f,on='key',how='right')
Out[36]:
data_x key data_y
0 4.0 b 9
1 5.0 b 9
2 1.0 c 2
3 2.0 c 2
4 7.0 a 6
5 7.0 a 6
6 NaN x 8
#所有数据都包含
e.merge(f,on='key',how='outer')
Out[37]:
data_x key data_y
0 4.0 b 9.0
1 5.0 b 9.0
2 1.0 c 2.0
3 2.0 c 2.0
4 7.0 a 6.0
5 7.0 a 6.0
6 7.0 d NaN
7 9.0 d NaN
8 NaN x 8.0
前面,我们的例子,都是通过columns来关联的,有的时候,我们可能需要使用index来关联,者就用到了另2个参数
left_index : boolean, default False
Use the index from the left DataFrame as the join key(s). If it is a MultiIndex, the number of keys in the other DataFrame (either the index or a number of columns) must match the number of levels
right_index : boolean, default False
Use the index from the right DataFrame as the join key. Same caveats as left_index
e
Out[38]:
data key
0 4 b
1 5 b
2 1 c
3 2 c
4 7 a
5 7 a
6 7 d
7 9 d
g = pd.DataFrame({'data':np.random.randint(0,10,size=3)},index=list('abc'))
g
Out[40]:
data
a 9
b 4
c 0
#指定right_index=True,使用index去关联
e.merge(g,left_on='key',right_index=True)
Out[41]:
data_x key data_y
0 4 b 4
1 5 b 4
2 1 c 0
3 2 c 0
4 7 a 9
5 7 a 9
2. 轴向连接
这里主要是介绍pandas中另一个函数的使用,pd.concat,concat一看上去,感觉是做拼接用的
pandas.concat(objs, axis=0, join='outer', join_axes=None, ignore_index=False, keys=None, levels=None, names=None, verify_integrity=False, copy=True)
Concatenate pandas objects along a particular axis with optional set logic along the other axes.
Can also add a layer of hierarchical indexing on the concatenation axis, which may be useful if the labels are the same (or overlapping) on the passed axis number.
我们先来看例子
s1 = pd.Series(['a', 'b'])
s2 = pd.Series(['c', 'd'])
s1
Out[51]:
0 a
1 b
dtype: object
s2
Out[52]:
0 c
1 d
dtype: object
pd.concat([s1,s2])
Out[53]:
0 a
1 b
0 c
1 d
dtype: object默认,是按纵轴进行拼接的,我们可以设置
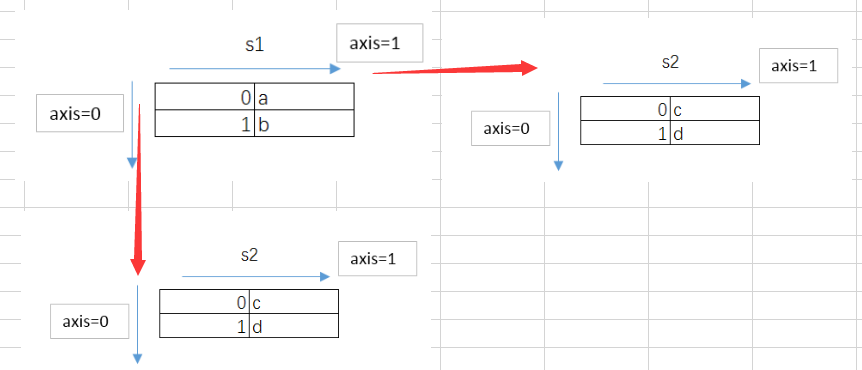
#横轴进行拼接
pd.concat([s1,s2],axis=1)
Out[54]:
0 1
0 a c
1 b d这里要注意下axis=1时,,如果index不一样,拼接的时候,是会合并的,如下面的例子
s1 = pd.Series([0,1],index=['a','b'])
s2 = pd.Series([2,3,4],index=['c','d','e'])
s3 = pd.Series([5,6],index=['f','g'])
pd.concat([s1,s2,s3])
Out[58]:
a 0
b 1
c 2
d 3
e 4
f 5
g 6
dtype: int64
s1
Out[60]:
a 0
b 1
dtype: int64
s2
Out[61]:
c 2
d 3
e 4
dtype: int64
s3
Out[62]:
f 5
g 6
dtype: int64
pd.concat([s1,s2,s3],axis=1)
Out[59]:
0 1 2
a 0.0 NaN NaN
b 1.0 NaN NaN
c NaN 2.0 NaN
d NaN 3.0 NaN
e NaN 4.0 NaN
f NaN NaN 5.0
g NaN NaN 6.0
这里,我们看个常用的参数,join,可以选择是取交集还是并集
join : {‘inner’, ‘outer’}, default ‘outer’
How to handle indexes on other axis(es)
#他们并没哟并集,所以是空
pd.concat([s1,s2,s3],axis=1,join='inner')
Out[73]:
Empty DataFrame
Columns: [0, 1, 2]
Index: []
s4 = pd.concat([s1*5,s3])
s1
Out[75]:
a 0
b 1
dtype: int64
s4
Out[76]:
a 0
b 5
f 5
g 6
dtype: int64
pd.concat([s1,s4],axis=1)
Out[77]:
0 1
a 0.0 0
b 1.0 5
f NaN 5
g NaN 6
#只返回了交集部分
pd.concat([s1,s4],axis=1,join='inner')
Out[78]:
0 1
a 0 0
b 1 5
我们也可以指明其他轴要使用的索引,要显示的index
join_axes : list of Index objects
Specific indexes to use for the other n - 1 axes instead of performing inner/outer set logic
pd.concat([s1,s4],axis=1,join_axes=[['a','b','c','d']])
Out[81]:
0 1
a 0.0 0.0
b 1.0 5.0
c NaN NaN
d NaN NaN3. 合并重叠数据
这里是另一个函数的使用介绍 combine_first,类似于numpy中where,
DataFrame.combine_first(other)
Combine two DataFrame objects and default to non-null values in frame calling the method. Result index columns will be the union of the respective indexes and columnsa = pd.Series([np.nan,2.5,np.nan,3.5,4.5,np.nan]
,index=['f','e','d','c','b','a'])
b = pd.Series(np.arange(len(a),dtype=np.float64)
,index=['f','e','d','c','b','a'])
b[-1]=np.nan
a
Out[85]:
f NaN
e 2.5
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
b
Out[88]:
f 0.0
e 1.0
d 2.0
c 3.0
b 4.0
a NaN
dtype: float64
#如果a的字段为nan,则用b的数据
np.where(a.isnull(),b,a)
Out[92]: array([ 0. , 2.5, 2. , 3.5, 4.5, nan])
a.combine_first(b)
Out[93]:
f 0.0
e 2.5
d 2.0
c 3.5
b 4.5
a NaN
dtype: float64
combine_first还会做数据对齐的操作
b[:-2]
Out[95]:
f 0.0
e 1.0
d 2.0
c 3.0
dtype: float64
a[2:]
Out[96]:
d NaN
c 3.5
b 4.5
a NaN
dtype: float64
b[:-2].combine_first(a[2:])
Out[94]:
a NaN
b 4.5
c 3.0
d 2.0
e 1.0
f 0.0
dtype: float64
本站文章版权归原作者及原出处所有 。内容为作者个人观点, 并不代表本站赞同其观点和对其真实性负责。本站是一个个人学习交流的平台,并不用于任何商业目的,如果有任何问题,请及时联系我们,我们将根据著作权人的要求,立即更正或者删除有关内容。本站拥有对此声明的最终解释权。