以前搞Java的时候,知道Selenium是做自动化测试的,后来发现搞爬虫也会用到Selenium,这里就和Python整合方面,简单学习下。
1. 什么是Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。这个工具的主要功能包括:测试与浏览器的兼容性——测试你的应用程序看是否能够很好得工作在不同浏览器和操作系统之上。测试系统功能——创建回归测试检验软件功能和用户需求。支持自动录制动作和自动生成 .Net、Java、Perl等不同语言的测试脚本。
--百度百科
官网地址:http://www.seleniumhq.org/
因为Selenium可以录制不同的动作,模拟操作,和Python结合以后,在爬取数据的时候就很方便,所以下面我们来看看需要怎样配置。
2. 安装配置
2.1火狐浏览器插件安装
插件地址:https://addons.mozilla.org/en-US/firefox/addon/selenium-ide/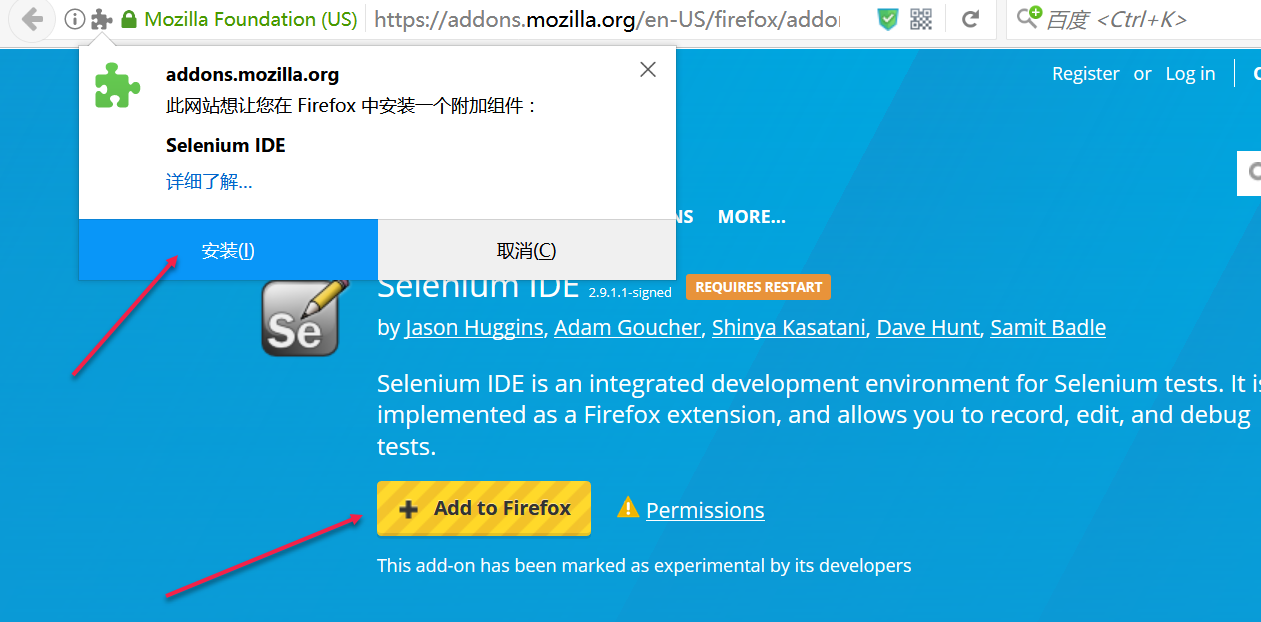
安装之后,我们可以直接在浏览器中使用Selenium
2.2火狐浏览器driver下载
这个再后面会用到,地址:https://github.com/mozilla/geckodriver/releases
WebDriver是Selenium的API,我们用Python集成开发会很方便,这个下载后,需要放到Path路径下



2.3Python安装Selenium模块
pip install selenium

3.示例代码
我们先来看一个简单的例子,我们打开火狐浏览器,然后让浏览器加载一个URL
from selenium import webdriver
browser = webdriver.Firefox()
browser.get('http://www.baidu.com/')
error 信息:
File "D:\Users\yugui\Anaconda3\lib\site-packages\selenium\webdriver\common\service.py", line 81, in start
os.path.basename(self.path), self.start_error_message)
WebDriverException: 'geckodriver' executable needs to be in PATH.
刚开始可能会报错,这是因为我们上面的那个driver没有加到PATH。
加到PATH后,再次执行,就可打开浏览器了
再来看一个略复杂的例子:
这是官方中的例子:http://www.seleniumhq.org/docs/03_webdriver.jsp#selenium-webdriver
from selenium import webdriver
from selenium.common.exceptions import TimeoutException
from selenium.webdriver.support.ui import WebDriverWait # available since 2.4.0
from selenium.webdriver.support import expected_conditions as EC # available since 2.26.0
#1.打开浏览器
browser = webdriver.Firefox()
#2.浏览器加载地址
browser.get('https://www.baidu.com/')
#3.输出浏览器标题
print(browser.title)
#4.一个断言,浏览器标题中包含'百度'关键字
assert '百度' in browser.title
#5.根据ID,获取搜索框
elem = browser.find_element_by_id('kw')
#模拟输入Python,进行搜索
elem.send_keys('python')
elem.submit()
try:
# 等待浏览器刷新,返回我们的搜索结果
WebDriverWait(browser, 10).until(EC.title_contains("python"))
# 输出当前浏览器的标题
print(browser.title)
finally:
# 关闭浏览器
browser.quit()
执行后,我们会看到,打开浏览器,然后搜索‘Python’,返回搜索结果后会关闭。
4.获取控件的方式
在上面的例子中,我们使用了find_element_by_id,就是通过标签的id来获取元素
这个和JS里面的差不多,还有很多其他的方法
#by id
#<div id="coolestWidgetEvah">...</div>
find_element_by_id(id_)
element = driver.find_element_by_id("coolestWidgetEvah")
#by class name
#<div class="cheese"><span>Cheddar</span></div><div class="cheese"><span>Gouda</span></div>
find_element_by_class_name(name)
cheeses = driver.find_elements_by_class_name("cheese")
论坛里这篇博客写的很好:Python3中Selenium使用方法
5. 实例练习
这里顺便写个小例子,练习下,我们方位豆瓣读书,然后搜索关键字,将所有的书都打印出来
import time
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import NoSuchElementException
#打开浏览器
browser = webdriver.Firefox()
#设置等待时长,最长等待10s
wait = WebDriverWait(browser,10)
#打开URL
browser.get('https://book.douban.com/')
#输出浏览器标题
print('browser title: ',browser.title)
#获取搜索框
inp_query = wait.until(EC.presence_of_element_located((By.ID,'inp-query')))
inp_query.send_keys('onepiece')
#可以直接提交,或者获取提交按钮再提交
inp_query.submit()
'''
#获取提交按钮
inp_btn = browser.find_element_by_class_name('inp-btn').find_element_by_tag_name('input')
inp_btn.click()
'''
def show_current_page():
print('-----------------------------------')
print('current url: ',browser.current_url)
#<ul class="subject-list">
rs = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'subject-list')))
book_list = rs.find_elements_by_tag_name('li')
print('current page total book: ',len(book_list))
print('info:',browser.find_element_by_class_name('trr').text)
#输出书的名字
for book in book_list:
print(book.find_element_by_tag_name('h2').text)
print('-----------------------------------')
#进入下一页
show_next_page()
def show_next_page():
#获取下一页的标签
#<span class="next">
span_next = wait.until(EC.presence_of_element_located((By.CLASS_NAME,'next')))
try:
#获取span中的a标签
a_next = span_next.find_element_by_tag_name('a')
a_next.click()
show_current_page()
except NoSuchElementException:
#已经没有下一页,可以退出了
print('now print all pages.')
finally:
browser.quit()
show_current_page()
#time.sleep(10)
#退出
browser.quit()
这里的元素获取方式,不是最佳的,代码还得继续优化,这个下一页挺好玩儿的,
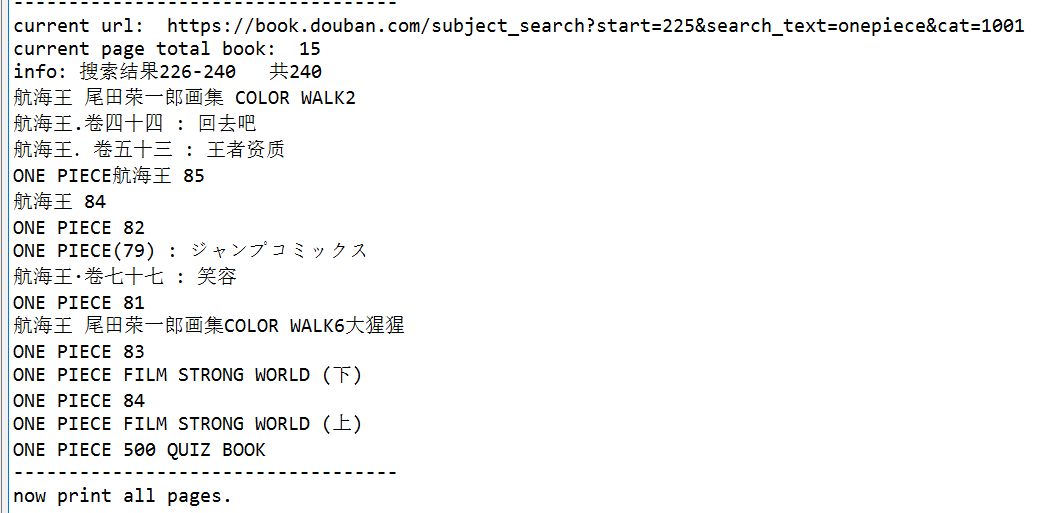
刚刚简单优化了下代码,主要改了些元素选择的方式,更直接了:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
from selenium.common.exceptions import TimeoutException
#打开浏览器
browser = webdriver.Firefox()
#设置等待时长,最长等待10s
wait = WebDriverWait(browser,10)
def main():
#打开URL
browser.get('https://book.douban.com/')
#输出浏览器标题
print('browser title: ',browser.title)
#获取搜索框
inp_query = wait.until(EC.presence_of_element_located((By.ID,'inp-query')))
inp_query.send_keys('onepiece')
#可以直接提交,或者获取提交按钮再提交
inp_query.submit()
show_current_page()
def show_current_page():
print('-----------------------------------')
print('current url: ',browser.current_url)
#搜索结果-汇总信息
page_info = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.article div.trr')))
print('info: ',page_info.text)
#搜索结果-书籍列表
book_list = wait.until(EC.presence_of_all_elements_located((By.CSS_SELECTOR,'div.article ul.subject-list li.subject-item')))
print('current page total book: ',len(book_list))
for book in book_list:
print(book.find_element_by_tag_name('h2').text)
print('-----------------------------------')
#进入下一页
show_next_page()
def show_next_page():
try:
#获取下一页的标签
a_next = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR,'div.article div.paginator span.next a')))
a_next.click()
show_current_page()
except TimeoutException:
print('超时了.')
span_next = EC.invisibility_of_element_located((By.CSS_SELECTOR,'div.article div.paginator span.next'))
if span_next:
print('now print all pages.')
else :
#真的超时,重试一次
show_next_page()
finally:
browser.quit()
if __name__=='__main__':
main()

