发现了一篇很好的教程,介绍一些Excel中的常用操作,怎样在pandas中实现,很不错,这里学习,顺便分享下。
原文地址:用Pandas完成Excel中常见的任务,这个是翻译的,再原文是:Common Excel Tasks Demonstrated in Pandas
好了,下面,我们开始学习下。
1. 基础数据
这个是从网上找的一个成绩单,拿了一部分数据
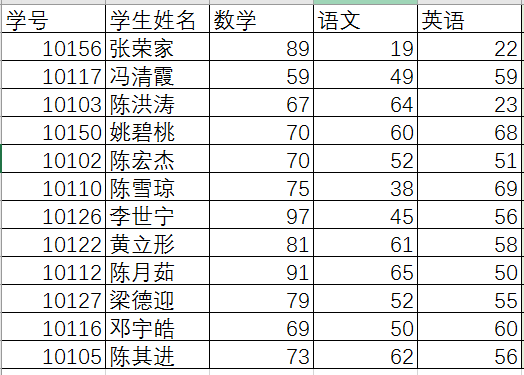
首先呢,我们想要,在加一列,显示总分,Excel中很方便
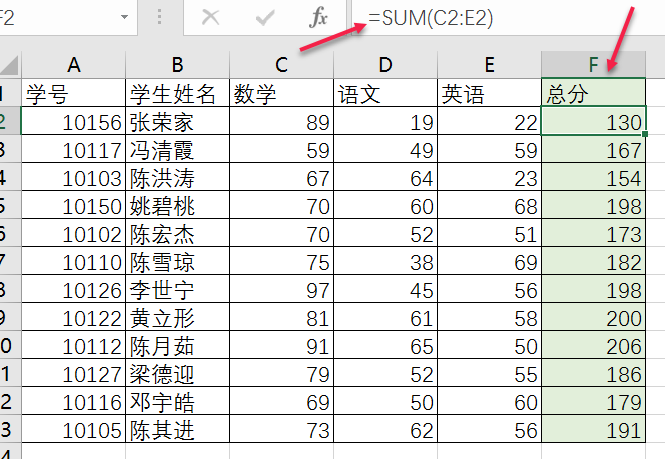
在pandas中呢,其实,我们就是需要“数学”,“语文”,“英语”这3列加在一起,我们怎样获取这3列呢?
前面,我们说过在DataFrame中,怎样去筛选数据
import pandas as pd
import numpy as np
df = pd.read_excel(r'D:\document\tableau_data\data_stu.xlsx',sheetname=0)
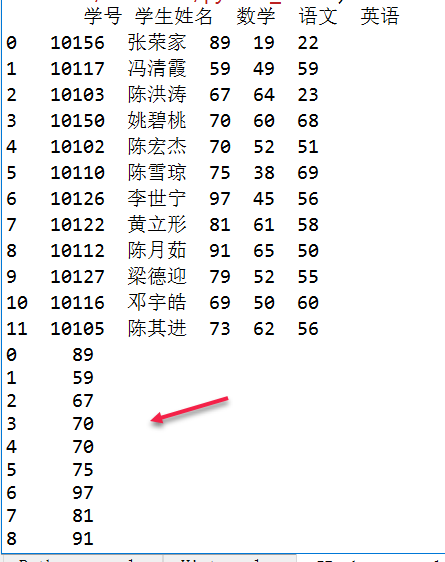
print(df)
print(df['数学'])
print(df['语文'])
那我们只需要新增一列,把已知的3列加起来就行
df['总分'] = df['数学'] + df['语文'] + df['英语']
print(df)

也是很方便,按照思路,直接相加就行了
下面呢,我们来统计下,数学的总分、语文的总分,就是把每一列的数据都相加

DataFrame中有很多的聚合函数,这里简单介绍下
#数学的最大值
print(df['数学'].max())
#数学的最小值
print(df['数学'].min())
#数学的平均值
print(df['数学'].mean())
#数学的总分
print(df['数学'].sum())
这个和SQL里面一样,Excel里也是这样的,他会从这一列中,获取最大值、最小值等等
下面,我们算个列的总分
df['总分'] = df['数学'] + df['语文'] + df['英语']
sum_data = df[['数学','语文','英语','总分']].sum()
print(sum_data)
print(type(sum_data))

这样,我们构造了一个Series前面呢,我们知道,Series可以初始化一个DataFrame
df2 = pd.DataFrame(sum_data)
print(df2)

初始化之后呢,是这样的,但是,结构不太一样,我们可以做一下行列转换
df2 = pd.DataFrame(sum_data).T
print(df2)

这回样子像一些了,但是DataFrame中,需要保持结构一致,我们还需要填充几列
我们可以用到reindex函数,重构一下索引
DataFrame.reindex(index=None, columns=None, **kwargs)
df2 = pd.DataFrame(sum_data).T
df2 = df2.reindex(columns=df.columns)
print(df2)

到了这里,我们只要将这个DataFrame插入到原来的DataFrame中就行了
DataFrame.append(other, ignore_index=False, verify_integrity=False)
Append rows of other to the end of this frame, returning a new object. Columns not in this frame are added as new columns.
刚试了下,发现,前面不重构索引的话,也是可以的,这里会自动补全
df3 = df.append(df2,ignore_index=True)
print(df3)

原文中还有些模糊匹配的例子,这里就不练习了,
下面,我们看个分类汇总的小问题,这里又增加了一个班级列,要不不好测试
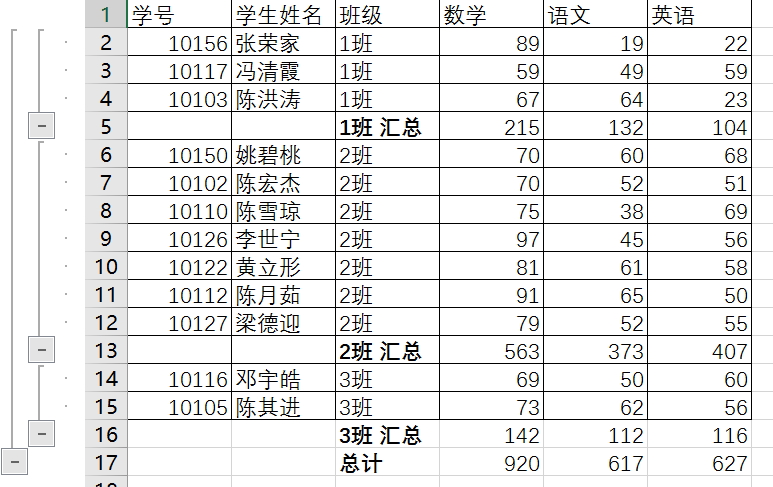
Excel里面实现,应该是这样的,
在pandas中,我们要使用groupby这个函数
print(df[['班级','数学','语文','英语']].groupby(by=['班级']).sum() )

原文中,还有一个格式化和rename index的问题,格式化还没搞明白,后面再说下吧
DataFrame.rename(index=None, columns=None, **kwargs)
df2 = df[['班级','数学','语文','英语']].groupby(by=['班级']).sum()
print(df2)
df2 = df2.rename(index={'1班':'1班-汇总','2班':'2班-汇总'})
print(df2)
我们可以通过一个dict,来替换索引的名字

好了,今天的分享就是这些,总结下呢,主要是对DataFrame中函数的理解和使用,还是得多多的练习才可以。
-- 这里回头试下那个格式化的问题,刚刚学习了下,可以参考:Python基础(2)- 格式化format
主要就是format那个函数的使用,还有DataFrame中那个applymap的使用
DataFrame.applymap(func)
Apply a function to a DataFrame that is intended to operate elementwise, i.e. like doing map(func, series) for each series in the DataFrame
import pandas as pd
import numpy as np
df = pd.read_excel(r'D:\document\tableau_data\data_stu.xlsx',sheetname=0)
print(df)
df2 = df[['班级','数学','语文','英语']].groupby(by=['班级']).sum()
print(df2)
df2 = df2.rename(index={'1班':'1班-汇总','2班':'2班-汇总'})
print(df2)
def score(s):
return '@{:.2f}@分'.format(s)
df3 = df2.applymap(score)
print(df3)


