1.序
DataFrame是2维的标签数组,可以把他当成电子表格(Excel),数据库里的表,a dict of Series。
DataFrame初始化,也可以有不同的输入,
在Series中呢,我们有一个index的概念,在DataFrame中,我们除了index,还有一个columns的概念
index:行标签
columns:列标签
2. DataFrame初始化
class pandas.DataFrame(data=None, index=None, columns=None, dtype=None, copy=False)
我们看到,这里有data,index,columns
我们可以只初始化data,其他都默认
import pandas as pd
import numpy as np
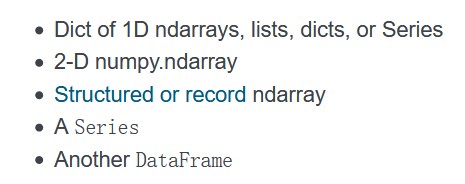
df = pd.DataFrame(np.random.randn(5))
print(df)

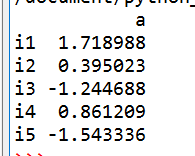
我们看到,index,依然是下标从0开始,columns呢,也是从0开始的
我们可以,初始化index,和columns
df = pd.DataFrame(np.random.randn(5),index=['i1','i2','i3','i4','i5'],
columns=['a'])
2.1 From dict of Series or dicts
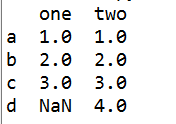
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
这里,我们定义一个dict,value是Series,就是我们给2个一维数组都加了一个key,然后把他们拼到一起,就成了一个DataFrame,key就变成了columns
为了让数据均匀,空的数据会默认为NaN
这些都是默认的,我们也可以显示初始化index和columns
df = pd.DataFrame(d,index=['a','c','p','q'])

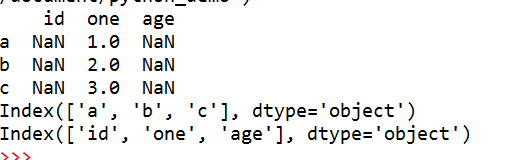
我们显示初始化index的话,会用我们指定的index去和data中Series的index去匹配,匹配上了就使用,匹配不上就剔除掉了,如上,只有'a','c'是有的,所以其他的都剔除掉了,像'p','q'是data中没有的,所以就是用NAN代替了
columns也是同样的道理
df = pd.DataFrame(d,index=['a','b','c'],columns=['id','one','age'])

我们可以查看DataFrame的index和columns
print(df.index)
print(df.columns)
2.2 From dict of ndarray/lists
d = {'one' : [1., 2., 3., 4.],'two' : [4., 3., 2., 1.]}
df = pd.DataFrame(d)

index会默认初始化,range(n)
这时,我们显示初始化index的时候,index的长度一定要和dict中ndarray的长度一样,不然,会报错
df = pd.DataFrame(d,index=['a','b','c','d','e'])

2.3 From structured or record array
data = np.zeros((2,), dtype=[('A', 'i4'),('B', 'f4'),('C', 'a10')])
data[:] = [(1,2.,'Hello'), (2,3.,"World")]
df = pd.DataFrame(data)
print(df)
这里先定义了一个数据结构,(对numpy还不熟,希望没说错),2行,3列,分别指定了每一列的数据类型;
然后进行初始化

这里的index是默认range(n)初始化的,columns是data中指定的名字,numpy中的数组后面也得学习下
df = pd.DataFrame(data,index=['ff','ss'])
我们显示初始化index的话,一定要和data中的行数一样,
columns的话,会取data中名字一样的
df = pd.DataFrame(data, columns=['one','two','C','B','A'])

2.4 From a list of dicts
data2 = [{'a': 1, 'b': 2}, {'a': 5, 'b': 10, 'c': 20}]
df = pd.DataFrame(data2)
print(df)

这里会将list中的元素做一个union,合并到一起去,
如果显示初始化index,columns的话,index的长度一个要和list的长度一致,columns 的话,则会自动处理,有则显示,无则显示NAN(有无表示是否和dict中的key匹配的上)
df = pd.DataFrame(data2,index=['x','y'],columns=['a','b','c','d'])

2.5 From a dict of tuples
df2 = pd.DataFrame({('a', 'b'): {('A', 'B'): 1, ('A', 'C'): 2},
('a', 'a'): {('A', 'C'): 3, ('A', 'B'): 4},
('a', 'c'): {('A', 'B'): 5, ('A', 'C'): 6},
('b', 'a'): {('A', 'C'): 7, ('A', 'B'): 8},
('b', 'b'): {('A', 'D'): 9, ('A', 'B'): 10}})
print(df2)
这个感觉类似Excel里面合并单元格的操作,就不多做练习了,啥时候用上了再说

2.6 From a Series
这个和前面都比较类似,我们看个例子
s = pd.Series(np.random.randn(5),index=['a','b','c','d','e'])
print(s)
df3 = pd.DataFrame(s,index=['x','y','a','b'])
print(df3)

2.7 常用构造函数
这里就不多说了,大家可以自行学习下

3. Column selection,addition,deletion
这里主要是说对DataFrame中对column的一些操作
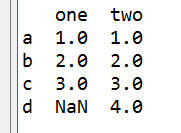
d = {'one' : pd.Series([1., 2., 3.], index=['a', 'b', 'c']),
'two' : pd.Series([1., 2., 3., 4.], index=['a', 'b', 'c', 'd'])}
df = pd.DataFrame(d)
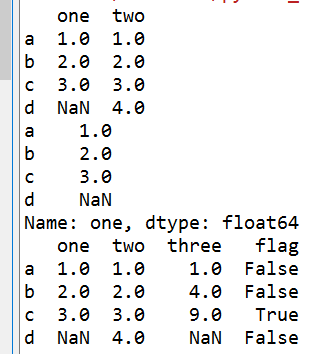
print(df)
#输出列名为one的数据
print(df['one'])
#给列three赋值,one列*two列
df['three'] = df['one']*df['two']
#给列flag赋值,one列的值是否大于2
df['flag'] = df['one'] > 2
print(df)
删除操作
del df['flag']
df.pop('three')
print(df)
DataFrame.insert(loc, column, value, allow_duplicates=False)[source]
关于DataFrame的其他操作,后面会再详细说明,这里就简单说到这了。
4.附录(参考资料)
官方教程:DataFrame
---------update at 2017-08-07
5.DataFrame使用后记
记录下DataFrame使用的小技巧
5.1索引对象
pandas中的索引对象负责管理轴标签和其他元数据(比如轴名称)。构建Series或DataFrame时,所用到的任何数组或其他序列的标签都会
转换成一个index。
索引创建后是不可以修改的
obj = pd.Series([4, 7, -5, 3])
obj
Out[144]:
0 4
1 7
2 -5
3 3
dtype: int64
obj.index
Out[145]: RangeIndex(start=0, stop=4, step=1)
o_ind = obj.index
o_ind
Out[147]: RangeIndex(start=0, stop=4, step=1)
o_ind[0]=9
Traceback (most recent call last):
File "<ipython-input-148-f7ee6348297a>", line 1, in <module>
o_ind[0]=9
File "D:\Users\yugui\Anaconda3\lib\site-packages\pandas\core\indexes\base.py", line 1620, in __setitem__
raise TypeError("Index does not support mutable operations")
TypeError: Index does not support mutable operations

