要学习pandas了,,看官网上的资料还是很多的,就根据找到的资料简单总结下吧。
这里也有很多同学分享的资料,这里都整理下,按照自己的理解整理下。
1. 序
这里的主要内容,参考官方教程:http://pandas.pydata.org/pandas-docs/stable/dsintro.html#dsintro
pandas里面有3个基本的数据结构,

我们可以把Series,理解成一维数组,但是又和常规的一维数组不太一样。
Series是一维的标签数组,可以存储任意的数据类型(integers,strings,floating point numbers,Python objs,etc.)
这里为什么是标签数组呢?因为他多了一个轴的概念,类似索引,我们往下看下就知道了。
2. Series初始化
引入必要的类
import pandas as pd
import numpy as np
基本初始化语法:
s = pd.Series(data, index=index)
这个data,就是我们要初始化的数据,index,就是那个标签了,即索引
data呢,常规可以为:

2.1 from ndarray
如果data是ndarray,index的长度必须和data的长度一样,或者保持默认,index会自动初始化,就是下标从0开始
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
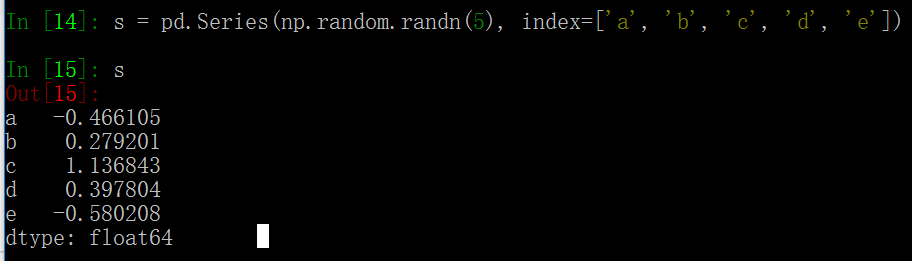
这里呢,我们data的长度是5,我们index的长度也是5
如果不是5呢,我们试试

这里是会报错的,少了不行,那多了呢?

也是不行的,所以,如果初始化index的话,长度一定要和data一样
当然,默认是可以的,
s = pd.Series(np.random.randn(5))

index默认初始化,从0开始
2.2 from dict
如果data为dict,因为dict是key,value的,所以,默认初始化时,会使用key来初始化index

当然,我们也可以,显式初始化index

通过上面的例子,我们发现,如果指定的index没有包括所有的data中的key,那么就只显示index中有的;
如果指定的index中有data中key没有的,那么就用NAN来赋值
2.3 from scalar value
如果data是常量,那么我们必须初始化index

刚试了下,好像也不用,默认会初始化一个长度的

3.Series使用
Series使用起来也很方便
3.1 Series is ndarray-like
我们可以使用下标,
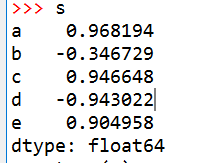
s = pd.Series(np.random.randn(5), index=['a', 'b', 'c', 'd', 'e'])
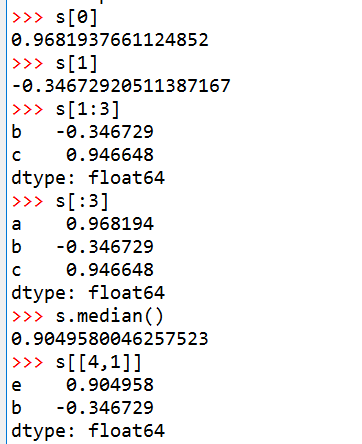
3.2 Series is dict-like
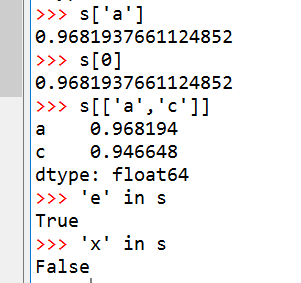
我们也可以像dict一样,使用index来操作Series
4.附录(参考资料)
博客:1.1 pandas数据结构Series
官方教程:Intro to Data Structures
------update at 2017-08-07
5. Series使用后记
这里记录些Series使用上的心得
Series使用起来,不仅可以使用下标来获取元素,也可以使用index来获取
s = pd.Series(np.random.randn(5) , index=list('abcde'))
s
Out[89]:
a -0.434789
b -0.047950
c -0.826720
d 1.493415
e 0.806696
dtype: float64
s[0]
Out[90]: -0.43478889663783105
s['a']
Out[91]: -0.43478889663783105
s[1:3]
Out[92]:
b -0.04795
c -0.82672
dtype: float64
s['b':'d']
Out[93]:
b -0.047950
c -0.826720
d 1.493415
dtype: float64
s[[3,2,1]]
Out[94]:
d 1.493415
c -0.826720
b -0.047950
dtype: float64
s[['b','c','a']]
Out[95]:
b -0.047950
c -0.826720
a -0.434789
dtype: float64
对于NaN值得处理,我们可以使用isnull,notnull来判断是否有NaN值
a = {'lufei':10,'namei':30,'qiaoba':40}
s = pd.Series(a,index=['lufei','namei','qiaoba','suolong'])
s
Out[98]:
lufei 10.0
namei 30.0
qiaoba 40.0
suolong NaN
dtype: float64
s.isnull()
Out[99]:
lufei False
namei False
qiaoba False
suolong True
dtype: bool
s.notnull()
Out[100]:
lufei True
namei True
qiaoba True
suolong False
dtype: bool
Series的索引就可就地修改,直接使用s.index
s.index
Out[104]: Index(['lufei', 'namei', 'qiaoba', 'suolong'], dtype='object')
s.index=list('abcd')
s
Out[107]:
a 10.0
b 30.0
c 40.0
d NaN
dtype: float64

