前几天学习了下Beautiful Soup的使用,本来想多写些内容的,但是发现,官方的介绍实在太详细了,每种方法基本都覆盖到了,
直接看官方的例子就足够了,而且还有一个中文版的,这里的话,就简单实践下,介绍几个常用的方法和一些小经验。
官方文档:https://www.crummy.com/software/BeautifulSoup/bs4/doc/
这里,我们就简单的解析下博客专栏,https://blog.hellobi.com/
就是这里的博客

这里的话,没有做太多的限制,我们直接解析就可以
1. 分析网页
我们再Firefox中,使用 Firebug很方便

这里的话,文档结构也很清晰,很适合我们练习
基本代码,我们获取网页信息
# -*- coding: utf-8 -*-
import urllib
from bs4 import BeautifulSoup
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
#加载网址,获取当前页面
def getHTML(url) :
page = urllib.urlopen(url)
html = page.read()
return html
2.常用类

html = getHTML('https://blog.hellobi.com/')
soup = BeautifulSoup(html, "html.parser")
这里,我们初始化Beautiful Soup,使用“html.parser”,这是一个默认的解析器,他还有其他的解析器,官网有介绍,这里就不说了,其他也没有测试过
这里,顺便说下Python中查看类的帮助信息,使用dir()函数,可以查看类的属性和方法列表
print type(soup)
print dir(soup)

我们还可以使用help函数,查看详细的帮助信息
print help(soup)

Beautiful Soup是最基础的类,其他的还有Tag,这个用起来和HTML中的标签类似
print soup.title
print type(soup.title)
#print soup.head
print type(soup.head)
这里,的title,head都是HTML中的tag,也是Tag类的对象
print soup.title.string
print type(soup.title.string)
print dir(soup.title.string)
然后,我们需要使用Tag的内容时,就用到了NavigableString

3.常用函数
blog_index=1
for blog in soup.find_all('div', class_='blog-item'):
print '----------------------------------------------------------'
print '第%s篇博客' %(blog_index)
title = blog.select_one('div.caption > h2 > a')
print '博客标题: ',title.string
author = blog.select_one('div.caption ul a')
print '作者: ',author.text.strip()
vote = blog.select_one('div.cp div.blog-votes span')
print '推荐次数: ',vote.string
info = blog.select_one('div.cp div.blog-views span')
print '阅读次数: ',info.string
blog_index+=1
上面的代码,就是遍历的首页的所有博客信息,很简单,就是一个find_all()和一个select_one()
 j
j
find_all()
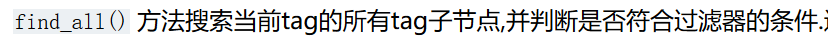
select_one()
select() 方法中传入字符串参数,即可使用CSS选择器的语法找到tag:
思想其实都一样,就是根据一定的规则,找到我们想要的标签
后面的话,我们再找到总页数,遍历一下,就可以获取所有的博客基本信息啦
https://blog.hellobi.com/?page=2
传递页码就可以了
好了,这里就举这一个简单的小例子,大家多在实践中使用就好了
