2014年写过一篇利用R语言爬取团购网数据的文章前几天被大家发掘出来了,如果大家对这篇文章感兴趣可以查看原文地址:
http://blog.csdn.net/jiabiao1602/article/details/41746967?locationNum=2&fps=1
今天我们就一起来利用简单的R函数做一些爬虫工作,当做是为一些爬虫爱好者提供一些思路。假如想爬取天善社区现在的在线课程数据,查看你感兴趣课程的相关信息(授课老师、课时数、价格、销量)等等。接下来,让我们一步步完成以上的需求。
先看看天善社区的视频首页地址:https://edu.hellobi.com/course/explore?page=1,首页截图如下:
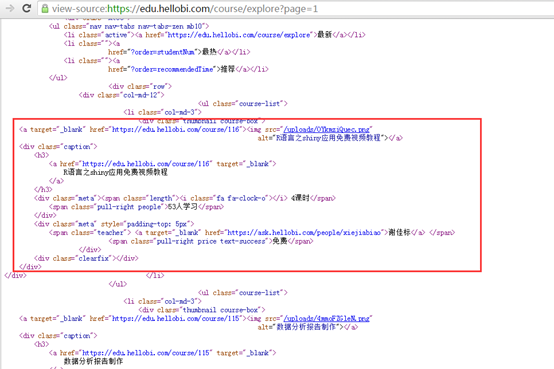
在网页上点击鼠标右键,选择查看网页源代码,查看当前页面的HTML源码:
假如各位看官不懂得爬虫技术,只要懂得运用readLines函数和简单的正则表达式就能完成简单的爬虫工作。
首先我们先利用readLines函数将网页的html信息爬取到R中。
web <-readLines("https://edu.hellobi.com/course/explore?page=1",encoding ='UTF-8')
查看读取后的结果:
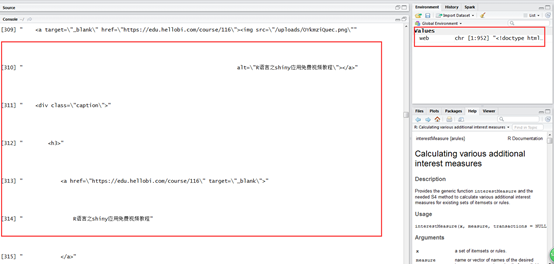
可见,已经把HTML的源码爬到R中,接下来,我们一步步提取需要的数据。
先提取课程名称。
> # 提取课程名称所在的行
> class <-web[grep("class=\"caption\"",web)+3]
> # 查看结果
> class
[1]" R语言之shiny应用免费视频教程"
[2]" 数据分析报告制作"
[3]" SAS可视化数据挖掘与分析"
[4]" 网站统计分析之Googleanalytic介绍与应用"
[5]" R语言之数据探索"
[6]" 【数据V课堂视频教程回放】10月13日Python实战案例分享:爬取当当网商品数据"
[7]" Python数据分析与挖掘实战"
[8]" 《零基础Hadoop特训营第一期》"
[9]" R语言之高级绘图"
[10] " 从零开始学习Spark免费视频教程"
[11] " ELK大型日志系统原理与实践详解"
[12] " R语言数据绘图基础"
[13] " 从 通用的数据挖掘流程 到 推荐系统、 自然语言处理"
[14] " Python3零基础快速入门"
[15] " 独一无二的数据仓库建模指南系列教程升级版 【12大章节、彻底无死角,全面掌握数据仓库建模】"
[16] " Storm基础应用案例讲解"
> # 删除多余的空格
> class <- gsub("","",class)
> # 查看结果
> class
[1]"R语言之shiny应用免费视频教程"
[2]"数据分析报告制作"
[3]"SAS可视化数据挖掘与分析"
[4]"网站统计分析之Googleanalytic介绍与应用"
[5]"R语言之数据探索"
[6]"【数据V课堂视频教程回放】10月13日Python实战案例分享:爬取当当网商品数据"
[7]"Python数据分析与挖掘实战"
[8]"《零基础Hadoop特训营第一期》"
[9]"R语言之高级绘图"
[10] "从零开始学习Spark免费视频教程"
[11] "ELK大型日志系统原理与实践详解"
[12] "R语言数据绘图基础"
[13] "从通用的数据挖掘流程到推荐系统、自然语言处理"
[14] "Python3零基础快速入门"
[15] "独一无二的数据仓库建模指南系列教程升级版【12大章节、彻底无死角,全面掌握数据仓库建模】"
[16]"Storm基础应用案例讲解"
现在提取课程数信息。
> # 提取课时所在的行
> length <-web[grep("class=\"length\"",web)]
> # 查看结果
> length
[1]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 4课时</span>"
[2]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 3课时</span>"
[3]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 2课时</span>"
[4]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 2课时</span>"
[5]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 15课时</span>"
[6]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 2课时</span>"
[7]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 25课时</span>"
[8]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 32课时</span>"
[9]" <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 24课时</span>"
[10] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 9课时</span>"
[11] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 18课时</span>"
[12] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 14课时</span>"
[13] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 4课时</span>"
[14] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 5课时</span>"
[15] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 27课时</span>"
[16] " <divclass=\"meta\"><span class=\"length\"><iclass=\"fa fa-clock-o\"></i> 3课时</span>"
> # 利用正则表达式提取课时数
> length <-substr(length,regexpr("i>",length)+2,regexpr("课",length)-1)
> # 查看课时数
> length
[1]" 4" " 3" " 2" " 2" " 15" " 2" " 25" " 32" "24" " 9" " 18"" 14" " 4" "5" " 27" " 3"
学习人数、授课老师、课程售价的信息根据以上方式提取出来,代码如下:
> # 提取学生人数
> people <-web[grep("class=\"pull-right people\"",web)]
> people <-substr(people,regexpr(">",people)+1,regexpr("人",people)-1)
> # 提取授课老师
> teacher <-web[grep("class=\"teacher\"",web)]
> for(i in 1:length(teacher)){
+ teacher[i] <-substr(teacher[i],gregexpr(">",teacher[i])[[1]][2]+1,gregexpr("<",teacher[i])[[1]][3]-1)
+ }
> # 提取课程价格
> price <-web[grep("class=\"teacher\"",web)+1]
> price <-substr(price,regexpr(">",price)+1,regexpr("/",price)-2)
将结果整理成data.frame形式。
>result <- data.frame(课程=class,课时数=length,学生人数=people,授课老师=teacher,课程价格=price)
>DT::datatable(result)
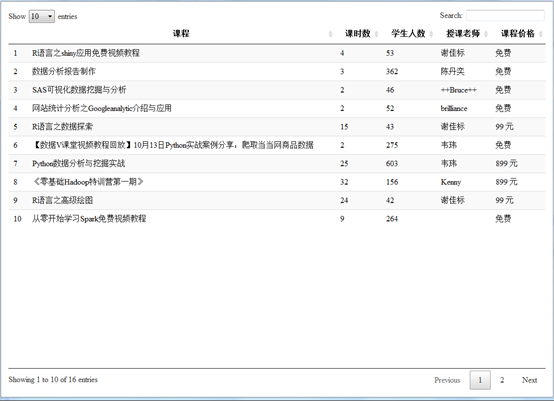
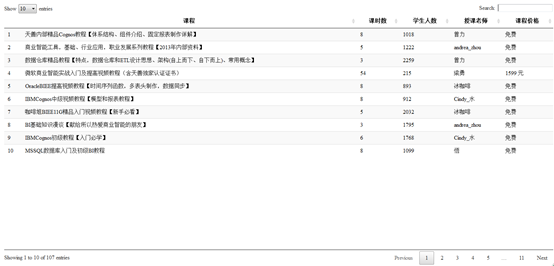
可见,第一页的课程信息全部被爬下来了(备注,第十个课程无授课老师,直接跳过)。
我们发现,天善一共有7页视频,现在利用爬虫全部爬取下来,总结网页地址:
https://edu.hellobi.com/course/explore?page=1
https://edu.hellobi.com/course/explore?page=2
……
爬取全部网页数据的完整代码如下:
# 方法一 利用readLines函数和正则表达式提取网页数据
# 爬取全部网页
web <- NULL
for(i in 1:7){
url<- paste0("https://edu.hellobi.com/course/explore?page=",i)
web1<- readLines(url,encoding = 'UTF-8')
web<- c(web1,web)
}
# 提取课程名称所在的行
class <-web[grep("class=\"caption\"",web)+3]
# 查看结果
class
# 删除多余的空格
class <- gsub("","",class)
# 查看结果
class
# 提取课时所在的行
length <-web[grep("class=\"length\"",web)]
# 查看结果
length
# 利用正则表达式提取课时数
length <-substr(length,regexpr("i>",length)+2,regexpr("课",length)-1)
# 查看课时数
length
# 提取学生人数
people <-web[grep("class=\"pull-right people\"",web)]
people <- substr(people,regexpr(">",people)+1,regexpr("人",people)-1)
# 提取授课老师
teacher <-web[grep("class=\"teacher\"",web)]
for(i in 1:length(teacher)){
teacher[i] <-substr(teacher[i],gregexpr(">",teacher[i])[[1]][2]+1,gregexpr("<",teacher[i])[[1]][3]-1)
}
# 提取课程价格
price <-web[grep("class=\"teacher\"",web)+1]
price <-substr(price,regexpr(">",price)+1,regexpr("/",price)-2)
# 将结果整理成data.frame形式
result <- data.frame(课程=class,课时数=length,学生人数=people,授课老师=teacher,课程价格=price)
DT::datatable(result)
其实,R做爬虫也有很多功能强大的包,例如quantmod包、XML包、RCrul包、rvest包。善用这些包,可以实现复杂的爬虫工作,并大大简化代码量。最后,我们利用rvest包对以上的爬虫重做一遍,这边直接给出爬虫代码。
#### 利用rvest包爬取网页数据
library(rvest)
library(magrittr)
result <- data.frame(课程=1,课时数=1,学生人数=1,授课老师=1,课程价格=1)
result <- result[-1,]
for(i in 1:7){
url<- paste0("https://edu.hellobi.com/course/explore?page=",i)
web<- read_html(url,encoding = 'UTF-8')
class <- web %>% html_nodes("div.course-box") %>%html_nodes("img") # 提取课程名称
class <-substr(class,regexpr("alt=",class)+5,regexpr(">",class)-3)
length <- web %>% html_nodes("div.meta") %>% html_nodes("span.length")%>% html_text() # 提取课时数
people <- web %>% html_nodes("div.meta") %>% html_nodes("span.people")%>% html_text() # 提取学习人数
teacher <- web %>% html_nodes("div.meta") %>%html_nodes("span.teacher") %>% html_text() # 提取老师
price <- web %>% html_nodes("div.meta") %>%html_nodes("span.price") %>% html_text() # 提取价格
result1 <- data.frame(课程=class,课时数=length,学生人数=people,授课老师=teacher,课程价格=price)
result <- data.frame(rbind(result,result1))
}
# 查看结果
DT::datatable(result)
结果如下:

可见,天善线上一共有107套视频。我们想查看一下谢佳标老师现在在线的视频有哪些,中需要在serach窗口输入老师名字即可。
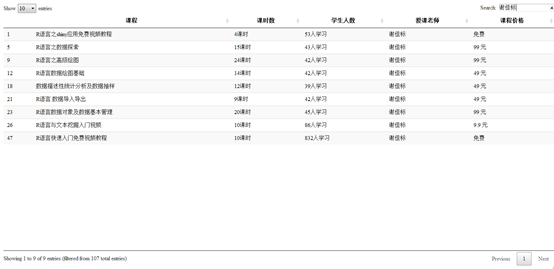
谢老师一共上线了9套视频,此外还有另外六套视频正在录制。想了解谢佳标老师课程更多的信息,可以点击数据挖掘R语言十三式的链接地址:
https://www.hellobi.com/event/137





