由于本人水平有限,对LDA的模型介绍可能不够深入或者有误之处还请各位指出,在下谢谢了;
在传统的主题挖掘中,我们可以最早的发现是使用文本聚类的算法,聚类的结果可能近似的认为满足一个主题,但是,这种基于聚类是算法普遍依赖文本之间的距离计算;而这种距离的量化在海量的文本中是难以定义的,在聚类的结果上也只是起到了区分类别的作用,并没有给语义上的信息;
主题模型是基于概率模型的主题挖掘算法,是一种使用概率的产生式模型来挖掘文本主题的新方法,在模型的假设中,主题可以根据一定的规则生成单词,那么在已经知道文本单词情况下,可以通过概率方法反推出文本集的主题分布情况;
接下来我们就开始进行用Python进行实操,从获取语料开始到得出模型的结果;这个数据集接着我的前两篇的数据一样,这个数据是未分词的训练集,这些是各个的类别目录,
接下来就是我们展示的文本,这个文本
接下来就是我们的代码部分,首先是导入我们想要的模块,也是坑爹,使用Pycharm的童鞋最好不要乱给自己的Python file 乱取名字,尔康我吃过苦头,重装了好几次pycharm 才知道是命名的冲突
# -*- coding: UTF-8 -*-
import sys
import os
import jieba
from mpltools import style
import numpy as np
from mpltools import style
import matplotlib.pyplot as plt
from gensim import corpora, models, similarities
这时候我们要设置一下我们的中文环境,这些代码这几篇文章都高度类似
# 设置中文环境#
reload(sys)
sys.setdefaultencoding("utf-8")
然后在写函数,一个读度文本的函数,一个读入停用词函数
#去除体用词
def get_stop_words(file_name):
with open(file_name,'r') as file:
return set([line.strip() for line in file])
# 度文本
def readfile(path):
fp = open(path, "rb")
content = fp.read()
fp.close()
return content
设置一下我们的路径,一个训练文本路径,一个是停用词的路径,在这里感谢一下数据集提供者,复旦的某位大神收集,虽然我也不知道名字,这有点尴尬;
corpus_path = r"E:\python_txt\answer\train/" # 未分词分类语料
stop_file_path=r"E:\python_txt/stoplist.txt"
这就是我们停用词的样子,这里注意,我在自己的电脑上测试的停用词一直不管用,后面慢慢想是不是和编码有关,果然,和你本地的编码有关系,这里我们设置文本的编码格式utf-8

这里开始分词的程序
#获取每个目录下的所有文件
catelist = os.listdir(corpus_path)
print catelist
# 读入停用词目录
stop_words=get_stop_words(stop_file_path)
#设置一下我们要存入分词后列表变量
train_set=[]
for mydir in catelist:
class_path = corpus_path + mydir + '/' # 拼出未分词的目录
print class_path
file_list = os.listdir(class_path) # 获取类别目录下的所有文件
print file_list
for file_path in file_list:
full_name = class_path + file_path#
print full_name
content = readfile(full_name).strip()
content == content.replace("'\r\n'", '').replace(""'()'"",'').strip() # 删除掉换行和多于的空格
content_seg=list(jieba.cut(content, cut_all=False))
train_set.append([item for item in content_seg if str(item) not in stop_words])#剔除停用词
print "分词结束"
结果如下,这说明我们的分词已经结束了
接下来就是模型构建的步骤了,首先构建词频矩阵
dic = corpora.Dictionary(train_set)
corpus = [dic.doc2bow(text) for text in train_set]
构建模型,这里的参数num_topics是你想设置的主题数多少,alpha参数就是主题密度,值越大表示文档中包含更多的主题,这里的默认是1/len(corpus)
tfidf = models.TfidfModel(corpus)
corpus_tfidf = tfidf[corpus]
lda = models.LdaModel(corpus_tfidf, id2word = dic, num_topics = 100,alpha=1)
corpus_lda = lda[corpus_tfidf]
这里我们打印一下前十名的主题规则,就是一些词的组合

看到第一个主题规则,我们肯定能猜想是和历史有关,其他或多或少都和电子计算机有关,这些都印证我们上面的目录分类
#画图
thetas=[lda[c] for c in corpus_tfidf]
plt.hist([len(t) for t in thetas], np.arange(100))
plt.ylabel('Nr of documents')
plt.xlabel('Nr of topics')
plt.show()
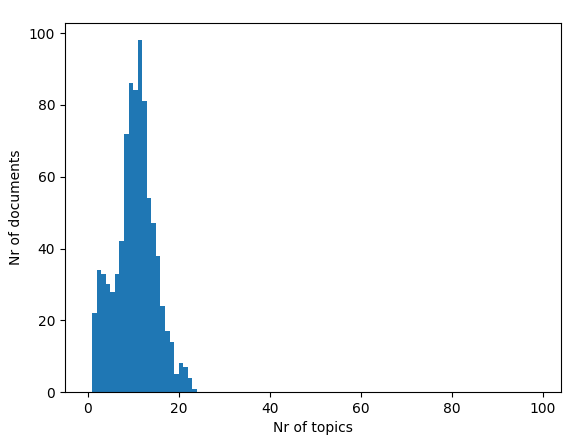
这个图上看,我们大概可以知道,主题数在10左右的文档有100个,大多数文档的主题都在7-16,如果把刻度分细或许可以了估计了;这篇文章就说到这里


