我们通常在做中文文本分析的时候,首先都需要先对文本进行分词,分割成我们想要的形式,这里的话我就使用python进行文本分词,并保存在本地相应文件夹中,这里的话我使用的数据集是answer;好像复旦大学某个人收集的,抱歉,我没记住名字,至少说明我还是有点责任感,哈哈;
入正题因为使用的python进行分词的话,我们就不得不进行一下对jieba的简短介绍,毕竟这里的重点不是讲jieba,这个小而精悍的分词系统完全够我们用了,有兴趣的同学可以百度一下他们的口号;这里的话我看社区有个人写的挺好的,这里就不多写了;
链接:https://ask.hellobi.com/blog/wangdawei/8300 感谢这位作者的辛勤劳动;
首先导入我想要的包
# -*- coding: UTF-8 -*-
import sys
import os
import jieba
然后设置一下我们的中文环境,毕竟我的Python是2.7,不是3版本,会有编码的问题,蛋疼
# 设置中文环境
reload(sys)
sys.setdefaultencoding("utf-8")
这里我写一个读取文件的函数
#读取文件
def readFile(path):
fp = open(path, "rb")
content = fp.read()
fp.close()
return content
#在写一个保存文件的函数,方便我们调用,参数字母也代表是什么意思了,
def readfile(path):
fp = open(path, "rb")
content = fp.read()
fp.close()
return content
接下来我们要开始我们的主程序部分,这个部分实现的功能是,将一个文件目录下的所有分类目录文本进行分词,并保存在相应输出目录下;
#设置输出和输入目录
corpus_path = r"E:\python_txt\answer\train/" #输入目录
seg_path = r"E:\python_txt\answer\test/" # 输出目录
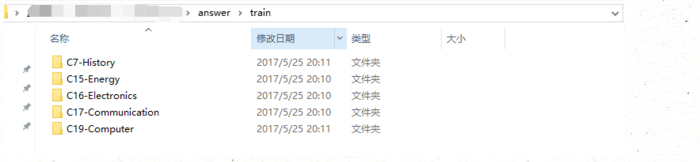
这是我们的输出目录
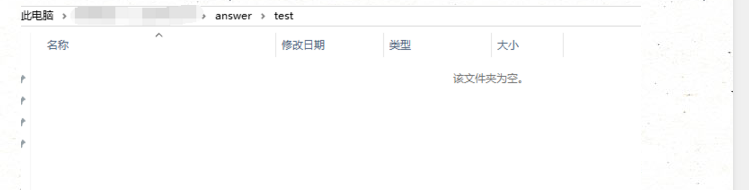
这是我们的输出目录, 空空如也,下面我们就看看我们原来的文本是怎么样
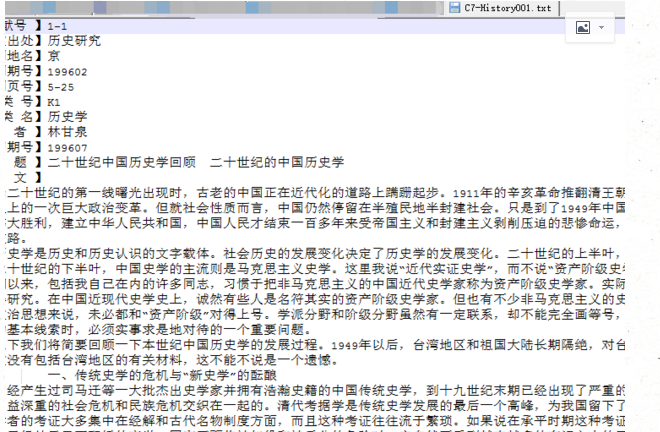
我们的文本是复旦那人收集的语料;接下来我们获取一下输入目录下的全部子目录名称
#获取在未分词语料下的所有子目录
catelist = os.listdir(corpus_path)
print catelist
结果上看没毛病,接下来开始写我们最重要的部分
#开始我们的迭代分词
for mydir in catelist:
class_path = corpus_path + mydir + '/' #构建出分词文本的目录
seg_dir = seg_path + mydir + '/' # 构建出输出分词的目录
if not os.path.exists(seg_dir): # 是否存在目录,不存在则创建一个
os.makedirs(seg_dir)
file_list = os.listdir(class_path) # 获取类别目录下的所有文件
for file_path in file_list:
full_name = class_path + file_path#构建出文本的目录作为参数传入我们调用的函数中
print full_name #打印一下分词的本文路径
content = readfile(full_name).strip()#文本删除前面的空白符
content == content.replace("'\r\n'", '').replace(""'()'"",'').strip() # 删除掉换行和多于的空格
content_seg=jieba.cut(content)#对文本进行分词
fp = open(seg_dir+file_path, "wb")#将文本写入文件中
for word in content_seg:
word=' '.join(word)#分词后的词语连接空格保存
fp.write(word.encode('utf-8'))#设置一下我们的编码格式
fp.close
print "分词结束"
好了,接下来看看我们的结果
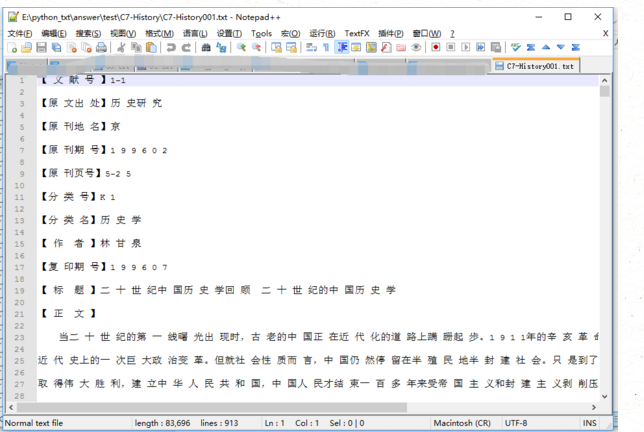
很好,这次文章就说到这里,下次说一下文本向量化


