
Keras 作者 @François Chollet说:开发Keras的时候,我遵循一个关键原则,就是“逐步揭示复杂性”。开始可以很简单,也可以逐渐复杂化、应对更灵活的场景,只需要增量化的学习。就像在复杂地图里局部放大一样。本文将按照增量化学习的原则,帮助大家逐步揭示Tensorflow2.0版本的复杂性。
我们都知道,在 Tensorflow2.0 中模型构建方式主要有三种:
• Sequential API• Functional API• Subclassing
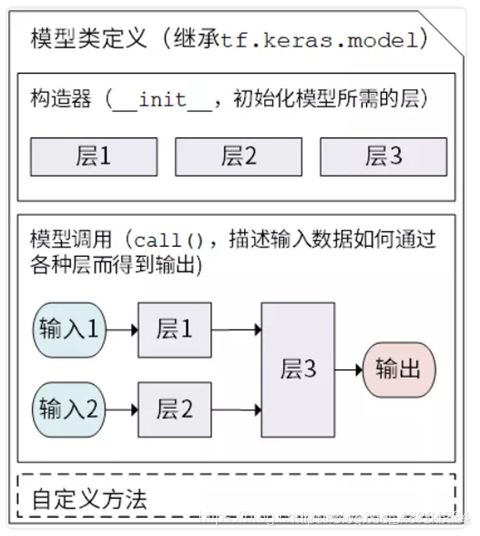
三种模型构建方法其复杂性以及对应的灵活性如下图所示:
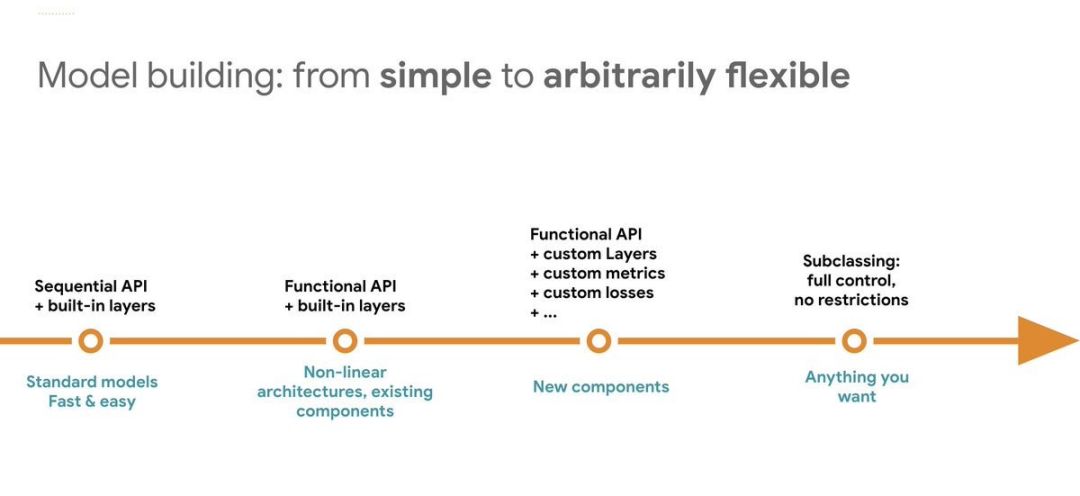
同样的,在 Tensorflow2.0 中也有多种训练模型的方式,最简单的可以直接调用fit()、train_on_batch()方法,如果仍然不够灵活,我们可以利用GradientTape()来自定义训练循环。
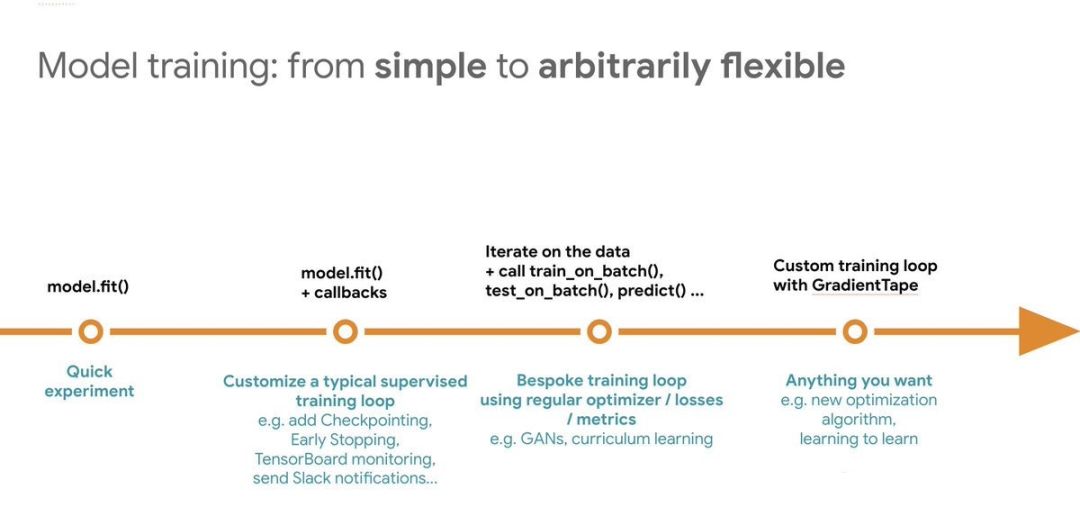
现在我们将上面两幅图正交后合并到一起,就可以形成如下图所示的二维的坐标轴。
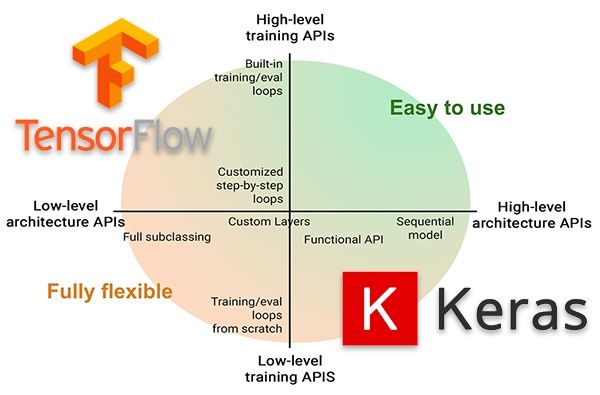
上面这幅图信息量其实很大,横轴表示模型构建的 API, 从低级到高级,对应的复杂性由高到低;纵轴表示模型训练的API, 从低级到高级,对应的复杂由高到低。按照象限来划分的话,可以看到第一象限的复杂性是最低的,其次是2、4象限,复杂性最高的是第3象限,但是其灵活性也是最高的。
从这幅图我们观察到,在Tensorflow2.0中,我们可以灵活搭配使用模型构建 API 和模型训练 API。
•第一象限:高级API搭建模型+高级API训练模型•第二象限:低级API搭建模型+高级API训练模型•第三象限:低级API搭建模型+低级API训练模型•第四象限:高级API搭建模型+低级API训练模型
这一切都能够按照我们的预期正常工作,只取决于我们的需要。
在文章接下来的内容中,我们将在 Fashion-MNIST 数据集上演示对应四个象限不同复杂度的模型构建和训练方法。
准备工作

Fashion-MNIST是一个替代MNIST手写数字集的图像数据集。其涵盖了来自10种类别的共7万个不同商品的正面图片。可以用它来测试你的机器学习和深度学习算法性能。
为了方便后面的演示,我们先下载 Fashion-MNIST 数据集,进行预处理后,拆分为训练集和测试集。
# !pip install -q -U tensorflow==2.0
import tensorflow as tf
import matplotlib.pyplot as plt
# Load the fashion-mnist pre-shuffled train data and test data
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
plt.imshow(x_train[10])
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape)x_train shape: (60000, 28, 28, 1) y_train shape: (60000,)
高级API搭建模型+高级API训练模型
Sequential API 搭建的模型是layer-by-layer的,它是最简单的定义模型的方法,但是有几个不足:
•不能够共享某一层•不能有多个分支•不能有多个输入
# !pip install -q -U tensorflow==2.0
import tensorflow as tf
import matplotlib.pyplot as plt
# Load the fashion-mnist pre-shuffled train data and test data
(x_train, y_train), (x_test, y_test) = tf.keras.datasets.fashion_mnist.load_data()
plt.imshow(x_train[10])
x_train, x_test = x_train / 255.0, x_test / 255.0
x_train = x_train[..., tf.newaxis]
x_test = x_test[..., tf.newaxis]
print("x_train shape:", x_train.shape, "y_train shape:", y_train.shape)使用 fit() 训练模型:
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose = 1, save_best_only=True)
model.fit(x_train,
y_train,
batch_size=32,
epochs=10,
validation_data=(x_valid, y_valid),
callbacks=[checkpointer])
低级API搭建模型+高级API训练模型
模型子类化具有很多优势。它可以更容易地实施模型检查。我们可以通过断点调试的方式,在指定代码行停留,并检查模型的激活函数或 logit 函数。当然,灵活性也意味着更多的问题,需要我们掌握更多的知识。
使用Subclass Model 训练模型:
classFashionNet(Model):
def __init__(self):
super(FashionNet, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
returnself.d2(x)
使用 fit() 训练模型:
model = FashionNet()
model.build(input_shape=(None,28,28,1))
model.compile(loss='sparse_categorical_crossentropy',
optimizer='adam',
metrics=['accuracy'])
checkpointer = ModelCheckpoint(filepath='model.weights.best.hdf5', verbose = 1, save_best_only=True)
model.fit(x_train,
y_train,
batch_size=32,
epochs=10,
validation_data=(x_valid, y_valid),
callbacks=[checkpointer])
低级API搭建模型+低级API训练模型
使用Subclass Model 训练模型:
classFashionNet(Model):
def __init__(self):
super(FashionNet, self).__init__()
self.conv1 = Conv2D(32, 3, activation='relu')
self.flatten = Flatten()
self.d1 = Dense(128, activation='relu')
self.d2 = Dense(10, activation='softmax')
def call(self, x):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
returnself.d2(x)使用 tf.GradientTape() 来训练模型:
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.batch(batch_size=32)
test_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_ds = test_ds.batch(batch_size=32)
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template= 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))
高级API搭建模型+低级API训练模型
函数API是一种创建更灵活模型的方法。它可以处理非线性拓扑、具有共享层的模型和具有多个输入或输出的模型。函数式API有更强的功能
•定义更复杂的模型•支持多输入多输出模型•可以定义模型分支,比如 inception block , resnet block•方便layer共享
inputs = Input(shape=(28,28,1))
conv2d = Conv2D(filters=32, kernel_size=3, padding='same', activation='relu')(inputs)
flat = Flatten()(conv2d)
dense = Dense(128, activation='relu')(flat)
outputs = Dense(10, activation='softmax')(dense)
model.summary()如果我们想要更清晰地了解梯度和损失函数运行机制的话,你可以使用梯度带。这对研究学者尤其有用。通过梯度带,我们可以手动定义训练过程的每一步。
训练一个神经网络的基本步骤如下:
•正向传播•损失函数评估•反向传播•梯度下降
当你想要进一步了解神经网络训练的时候,梯度带就变得很有指导意义。如果你需要检查不同模型权重的损失值或者梯度矢量本身的话,你可以直接把它们打印出来。梯度带提供了很大的灵活性。但是正如子类化对比序列化一样,更好的灵活性也需要额外的代价。同 fit() 方法相比,我们在这里只需要手动定义一个训练循环。
使用 tf.GradientTape() 来训练模型:
train_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
train_ds = train_ds.batch(batch_size=32)
test_ds = tf.data.Dataset.from_tensor_slices((x_train, y_train))
test_ds = test_ds.batch(batch_size=32)
loss_object = tf.keras.losses.SparseCategoricalCrossentropy()
optimizer = tf.keras.optimizers.Adam()
train_loss = tf.keras.metrics.Mean(name='train_loss')
train_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='train_accuracy')
test_loss = tf.keras.metrics.Mean(name='test_loss')
test_accuracy = tf.keras.metrics.SparseCategoricalAccuracy(name='test_accuracy')
def train_step(images, labels):
with tf.GradientTape() as tape:
predictions = model(images)
loss = loss_object(labels, predictions)
gradients = tape.gradient(loss, model.trainable_variables)
optimizer.apply_gradients(zip(gradients, model.trainable_variables))
train_loss(loss)
train_accuracy(labels, predictions)
def test_step(images, labels):
predictions = model(images)
t_loss = loss_object(labels, predictions)
test_loss(t_loss)
test_accuracy(labels, predictions)
EPOCHS = 5
for epoch in range(EPOCHS):
train_loss.reset_states()
train_accuracy.reset_states()
test_loss.reset_states()
test_accuracy.reset_states()
for images, labels in train_ds:
train_step(images, labels)
for test_images, test_labels in test_ds:
test_step(test_images, test_labels)
template= 'Epoch {}, Loss: {}, Accuracy: {}, Test Loss: {}, Test Accuracy: {}'
print(template.format(epoch+1,
train_loss.result(),
train_accuracy.result()*100,
test_loss.result(),
test_accuracy.result()*100))总结
Tensorflow2.0 版本后,上手难度的确降低了很多, 正如 François Chollet 所说,一开始可以很简单,当我们需要处理更复杂的问题、应对更灵活的场景的时候,只需要增量化的学习。使我们很容易在灵活性和复杂性之间找到满意的折中方案。