前文传送门:
从零开始学自然语言处理(十七)—— 统计语言模型(下)
在之前的两篇文章中,我们讲解了统计语言模型来计算句子的概率大小,并且讲到了平滑方法。当我们学会计算句子的概率大小后,我们通常会思考,如何衡量和比较不同的统计语言模型好坏呢?
比较不同语言模型的好坏,我们最快想到的就是将不同模型用在同一个具体任务中,例如机器翻译,然后分别得到模型的准确率。当然,这是很好的评价方式,但是这种评价方式的缺点是不够客观,因为你使用的是某个研究方向的任务去衡量结果,同时,这种方法计算缓慢,通常一个任务的数据量较大,使用这种评价方法得到结果需要较长时间。那有没有其他方法评价呢?答案是有的!我们回想一下统计语言模型做的事情其实就是计算一句话的概率,所以对于一句正常的语句,理论上来说,统计语言模型计算的概率越高,模型效果越好,因为概率越高,代表这句话是正常语句的概率越大。
所以困惑度(perplexity)这一指标被提出了。困惑度可以用来评价统计语言模型的好坏,其基本思想为:给测试集中的句子赋予较高概率值的语言模型较好(因为测试集中的句子都是正常句子),当统计语言模型训练完之后,那么训练好的模型在测试集上的概率是越高越好。
困惑度的计算方法如下:
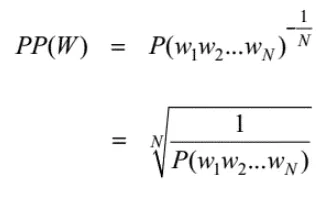
其中,N代表句子中词的个数,P(w1w2...wn)代表语言模型计算出的句子概率。
可以通过上面的公式看到,句子计算的概率越大,困惑度越小,也就是说小的困惑度等于好的模型。
当然,我们可以将公式化简转换为:
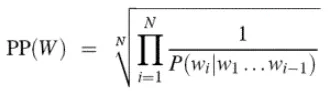
如果使用的Bi-gram,可进一步化简公式为:
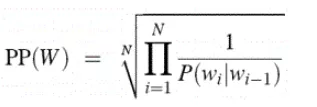
扫码下图关注我们不会让你失望!

