
前言
随着pandas近两三年来的风靡发展,尤其是在金融量化分析领域的突出表现,几乎席卷了整个金融圈,在被各类应用型分析工具霸占的市场,pandas带着开源开放的精神态度,借助着Python语言强大的功能底蕴,以简单、高效的优势,开始占据了日趋统治的地区。
在其他数据分析领域,pandas也同样发挥着至关重要的作用,不论是在互联网领域的电商营销数据分析,网络用户行为分析,还是传统领域的工业数据分析等等,pandas都已经开始配合着其它大数据分析工具和开发语言担负起了数据粘合与结果输出的关键角色。
正因为pandas的价值体现,越来越多热衷于数据分析的新人开始试水pandas带来的数据分析之便,而作为入门者,在学习的过程中也难免会碰到一些问题。今天,就给大家介绍一下pandas的数据选取时用到几种方法。
pandas数据选取之不同
我们都知道,pandas里最常用的数据结构DataFrame实际是一个二维表,行和列的设计很便于数据的选取。在讲解之前,我们先初始化好一个DataFrame形式的数据,想到近期对高增长低估值的股票有炒作预期的可能性,这里就以上市公司的业绩预告的数据作为演示。(这里不讲怎么挖掘高增长预期股,大家各自发挥)


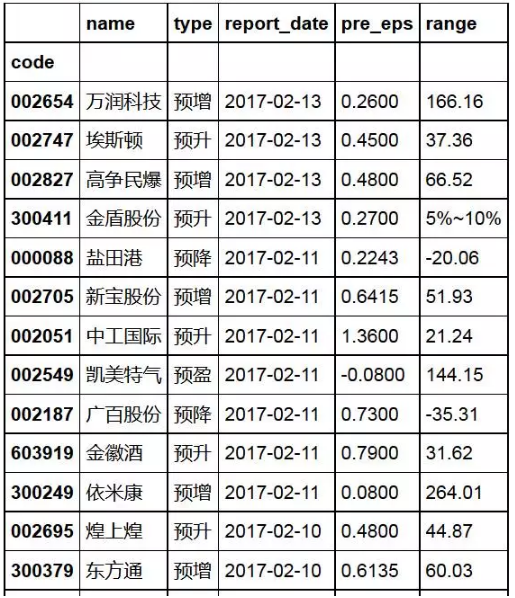
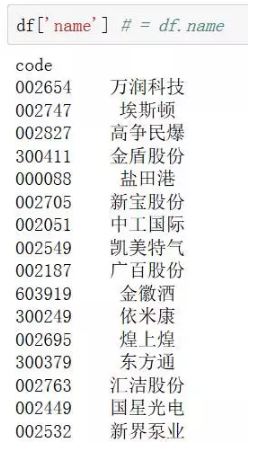
有了一个DataFrame数据,我们来看看pandas官方教学中最常见最容易的数据选取方式是怎么样的。那就是通过中括号[]来获取直接获取数据。
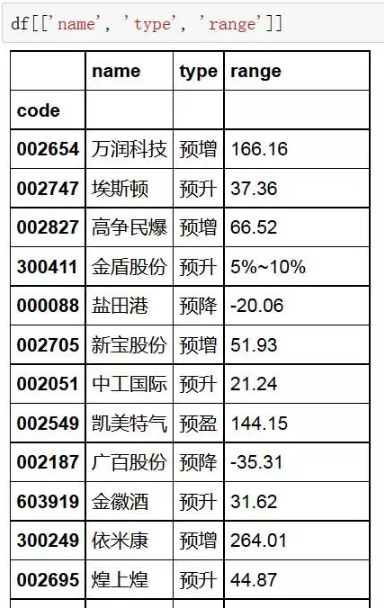
选取多列数据,则可以通过列名数组来获取。
除了以上的方法,pandas还有其他几种数据选择的方法,而且在实际的数据分析生产环境中,官方也是推荐使用经过了优化的pandas数据访问方式 .loc、.iloc、.ix、.at、.iat这几种模式。(在老的pandas版本中,是xs / icol / irow)
到底这几类方法有什么区别?很多初学者经常在这里容易被搞糊涂,其实只要了解了数据选择时的输入值的含义,就明白了其实原由。
根据我的理解,我们先来看看这几个方法的说明:

通过index值获取
在使用数据之前,为避免造成数据混乱,我们先给index排序一下:
df = df.sort_index()
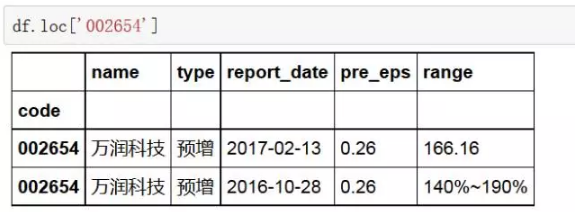
1、使用index值(标签)获取行数据
2、通过index值在选取列值
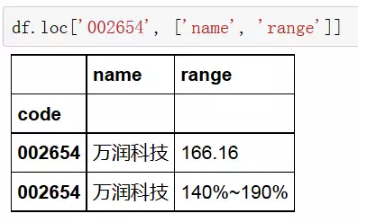
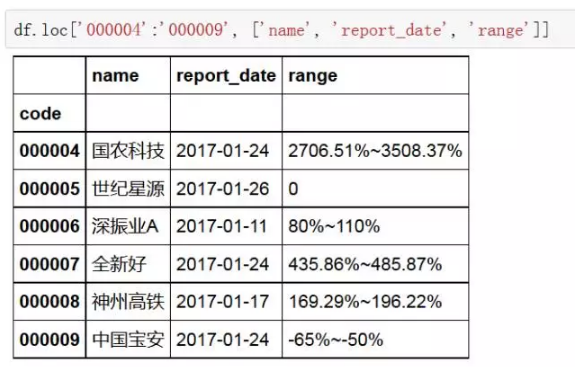
3、通过index值切片
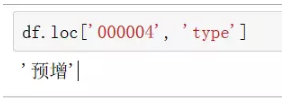
4、获取一个单元值
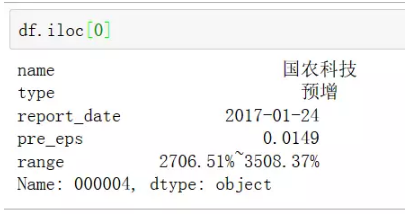
5、通过index值快速访问数据

通过index位置获取数据
1、通过index索引标号获取行数据
如果通过iloc输入index值,pandas会抛出异常

反之,在使用loc时如果输入index标号同样也会出现错误,除非index标号和index值正好有重合的情况。
2、通过index标号切片
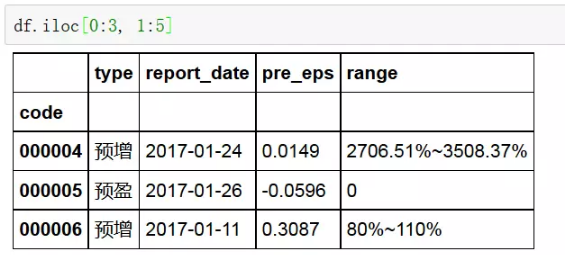
3、通过指定index标号
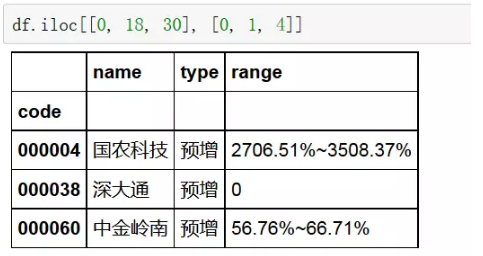
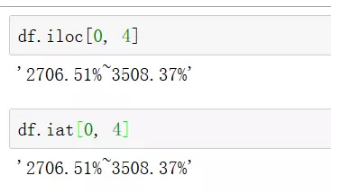
4、取指定单元数据
5、ix获取数据
ix结合了loc和iloc的方式,可是方便获取行值和列值数据,这里不再作说明。
各类选取方法性能比对
在获取和修改DataFrame数组的时候,都会涉及到性能的问题,这里借用了一个网络上列子进行说明,大家通过测试代码的结果,就可以轻易看出哪类方法的性能更好。

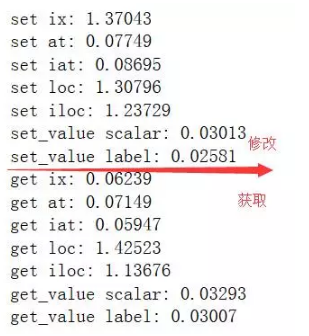
通过结果可以看出,at和iat在选取和修改数据上都比loc性能要更好一些,而在与ix相比在选取和修改上有一些差异。
另外,pandas还提供了两个获取和修改数据方法,get_value和set_value。在性能方面,都有很好的表现,根据pandas的代码说明,iat与这两个方法相比,在获取数据时iat性能更好,而在修改数据时性能比起set_value相对较差,但根据测试结果却有些出入,有时间和兴趣的朋友可以根据代码再进行研究和测试。
由于篇幅有限,以上性能测试代码并不能看清楚,有兴趣尝试的朋友可以通过在本公众号直接私信回复“性能测试”自动获取代码。

