在《Hadoop平台中SQL优化的四个思路》一文中,我们对Hadoop平台中的SQL优化思路做了简单介绍,为的是让读者能对SQL优化有一个宏观掌握。
本文将针对Transwarp Data Hub(TDH)中的常见SQL的场景,继续深入讨论如何对不同类型SQL选择不同的优化策略。根据SQL特性以及数据特性,本文把TDH中涉及的SQL场景分为以下六类,分别对它们的优化方法进行分析。
1. 大表与大表的普通Join
2. 大表与小表的MapJoin
3. 重复元素多的场景
4. Map Task数量多执行时间短
5. Reduce Task数量多执行时间短
6. 利用临时表优化的混合场景
大表与大表的普通JOIN
这里所说的普通JOIN并不单指语句中的JOIN操作,而是指它的实现方法。许多SQL处理引擎,如Inceptor,会根据JOIN左右两表的尺寸、尺寸差距、数据切分方式,采用不同的JOIN执行策略,普通JOIN是其中最基础的一种。
实现普通JOIN的过程是这样的:扫描过滤两张表的数据(Map Stages),然后通过Shuffle将Key哈希值相同的数据分发到各个节点,在各节点内部执行JOIN(Reduce Stages),示意如下。
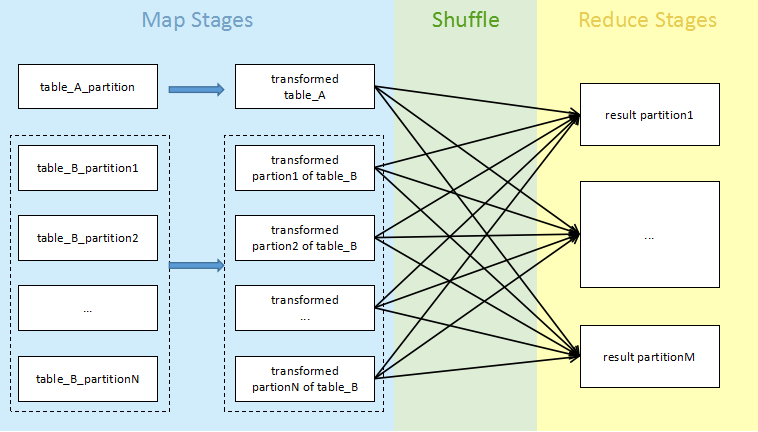
普通JOIN通常在两表数据量都很大的情况下被采用。在执行它时应重点关注Shuffle 和JOIN Stage节点的数据量是否过大,是否有磁盘溢出趋势,若有此倾向,请适当增加Reduce Task 数目。
注意,数据量极大的Shuffle对网络通信有很严重的影响,因而大表之间的普通JOIN并不被推荐,只是和其他JOIN方式相比,普通JOIN对于两张大表JOIN而言已经是性能很好的处理方式了。所以有多表JOIN时,必须尽量避免大表与大表直接JOIN,如果语句中有小表,务必先用小表过滤大表,即尽可能先做与小表有关的JOIN,再加入大表。
大表与小表的MapJoin
MapJoin是一种针对大表与小表JOIN的特殊实现方式,在大小表数据量悬殊的情况下能有效的提升JOIN执行效率,一般受优化开关或者Hint控制启动。
MapJoin的基本思想是将小表的数据广播给每个Executor,Executor拿到数据后,会为小表建立Hash表,并读取本地大表的数据块,根据Join Key查小表Hash表,完成JOIN。其过程示意如下图所示:
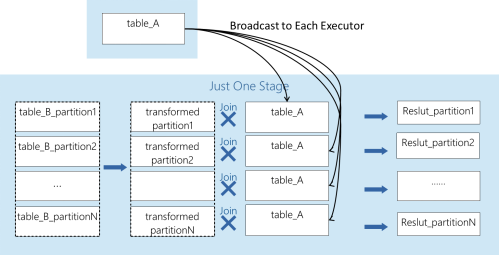
和普通的JOIN相比,MapJoin对大表的操作都是在本地完成,减少了Shuffle,绕过了大量的大表数据传输,所以网络开销小,特别适用于大小表的JOIN。
但是它有两个主要缺点:小表的Hash表需要常驻内存,所以内存开销大;小表的数据广播和Hash表的建立是串行执行,会影响效率。为了减弱这两种缺点带来的影响,执行MapJoin时须重点关注JOIN的顺序和过滤后小表的行数:优先执行过滤性较高的MapJoin;且小表的行数不可过大,通常允许的小表上限为20万条。注意,如果JOIN的大表极大,考虑到大表与小表的大小相对性,允许将可接受的小表行数上限提升至100万条。
重复元素多
如果某SQL访问的数据中重复元素很多,而且需要Shuffle,将容易导致Shuffle有较大数据量,对网络I/O和内存都会带来很大的负担。如果我们能够在Shuffle前消除或者合并这些重复元素,将缓解这种压力。
建议的做法是,执行SQL之前检查数据聚合率,如果重复元素很多,聚合率高,请考虑在保证查询语义不变的情况下用GROUP BY去重,或者改写为其他形式的实现方式。
例如,如果某语句执行两表的普通JOIN,并对JOIN结果的JOIN Key去重,如下面这条SQL:

其中,被扫描的两表student和user数据量都很大,而且关于JOIN Key都有很高的聚合率,此时可以先做GROUP BY去重,再JOIN,即把上面的语句改写为如下形式,可以获得更优性能:

Map Task数量多执行时间短
Map Task的数量同数据块的数量大小相关,比如某表有40万个数据块,以它为数据扫描源时,会对应产生40万个Map Task。当Map Task数量多且执行时间短时,说明存在大量小文件。过多的小文件将对性能产生巨大的损耗,因为任务本身的启动需要开销,一旦Map Task处理的数量很少,处理能力不饱和,就会使任务分配过程占用过多不必要的资源,引起引擎的执行效率下降。
本文建议尽量在不改变数据分布的前提下,采取措施对数据块进行合并,从而减少数据块和需启动的Map Task数目。
注意,不建议为每个Task安排过多的任务量,因为任务量过多会减少并行工作的Task数量,同样影响效率。在设计数据块尺寸下限时,尽量保证单个Task的处理时间不低于2s,设计上限时,对应Task的GC时间占总执行时间的比例不应超过20%。
Reduce Task数量多执行时间短
和上面的场景类似,如果创建过多Reduce Task,每个Task通过Shuffle仅获得很少数据量,任务启动消耗的资源占据大量比重,将导致执行效率低下。
对于这样的场景,请减少Reduce Task的数量。
通常(不是绝对),大表JOIN或者GROUP BY后,产生的数据量相对原始数据小很多。这时可以减少后面Reduce Task的数目,使Reduce Task的启动更有价值。
利用临时表优化的混合场景
当SQL混合了以上多种场景时,分析和优化的难度将增加,此时创建临时表是一种有效的的降低语句复杂度的手段。临时表是一种存放在系统的临时文件夹中的表,在退出数据库之后被自动释放。创建临时表的好处是,能够帮助分析语句各部分影响性能的程度,发现阻碍性能表现的根源。而且,对于实例中会被经常执行的语句块,为它们创建临时表可以避免对相同的语句的反复编译运行。
建议在处理复杂SQL时采用如下步骤:首先拆解SQL,对语句中的子查询或者中间生成的计算结果创建临时表;接着构造一个新的语句,将这些临时表串联起来用于计算,达到和原语句同样的效果。注意,在创建临时表以及构造新的语句时若遇到上面的五种场景,应遵循对应的优化策略。
下面有三种可创建为临时表的常见场景:
a. WITH-AS
如果SQL中有WITH-AS短语,且短语内的部分执行耗时较久,如果你希望避免今后对这段语句重复执行,可以将其内容提取出来建为临时表。
b. 非关联子查询
不涉及两张表之间关联的查询称为非关联子查询。如果语句中有非关联子查询,可直接将子查询建为临时表。
c. 关联子查询
对于不属于以上两种情况的SQL语句,一般会涉及子查询与外部查询之间关键字关联的问题,由于表之间因条件限制而产生了相互制约,因此此类问题分析起来会更复杂一些,用户需要通过分析执行计划来决定如何分割原语句。操作顺序通常是,EXPLAIN语句,然后根据执行计划的顺序,手工创建临时表。
整体思路
通过对以上六种场景的分析,本文推荐了一些TDH平台中对不同情况适用的SQL优化方法。最后在这里对SQL优化设计的一般流程和整体思路提供一些建议,希望可以帮助读者把握基本的优化方向。
Step1:拿到SQL时,请先解决语法不兼容问题。因为厂家标准不同,需要在当前使用的平台上按规范统一。
Step2:然后抽取若干典型代表的SQL,运行一遍,看兼容问题是否解决,语句是否可以实现。接着对选出的这几个语句进行优化并运行。一定不要直接执行所有的语句,一是因为等待结果的耗时很长,二是因为增加了分析的困难度。
Step3:观察是否存在这样两种异常:1. Task数目十分庞大,且单个耗时短;2.某(些)Stage运行速度很慢。
Step4:针对Step3发现的异常,进行性能优化。检查和优化的过程大体分为以下五个方面:
资源使用。观察系统资源占用量与使用情况。
分析数据。获取每个表的各行各列的特性,比较分析是否存在记录行数很大的表、表与表的特点差异和记录行数量级的差距。
分析执行计划。明确是否应该用MapJoin,是否应调整JOIN顺序,是否需要谓词下推。
分析过滤率。计算过滤率,核对JOIN顺序并做出调整,先JOIN数据量少过滤率高的表。
对SQL分类,选择典型,重点分析。从最影响性能且容易改善的部分开始,不断优化、迭代,直至得到满意效果。
Step5:最终把选用的优化手段按类型应用到其他语句上。
对SQL优化进行实践的过程中,需要读者不仅仅只是理解这些优化思想,更重要的是在足够多的案例中去累积经验,多尝试多比较,提高对特征SQL的敏锐度,将充裕的理论转化为价值,将了解的事物变成属于自己的东西。
————————
往期回顾:
技术|Inceptor任务的图形化分析(一)
技术|Kappa:比Lambda更好更灵活的实时处理架构
技术|TDH的图形化集群服务指标监测工具及其使用方法介绍
关于:本文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————

