了解执行机器的运行情况对于性能调优、执行过程的问题排查十分重要。为方便对执行情况的监控,Inceptor专门提供了管理界面(4040端口),用于给用户查看系统性能和各机器各进程对各任务的执行情况。
为达到有效分析语句执行过程的目的,在浏览管理界面时,我们应该将重点放在以下这些环节:检查执行耗时,报错,查看所有Executor是否已正常启动、Executor ID号是否连续、配置是否生效等。本系列文章将针对这些项目,介绍Inceptor管理界面上各目录、标签与标题的代表含义,以及如何通过阅读各属相指标值,来判断系统的工作情况。
Inceptor管理界面端顶部提供了七个标签页:Jobs、Cluster、Local、Storage、Holodesk、Environment、Executors。如下图所示:

我们将分别介绍这七个标签页的使用和浏览方式。由于本次内容篇幅较多,因此分为多篇文章展开。本文将首先介绍Jobs和Cluster两个标签页,剩余标签页以及相关内容会在今后陆续提供。
Jobs和Cluster界面提供了在集群模式下执行的所有Job和Task的信息,使用频率较高,是进行管理监测时应注意关注的页面对象。
Cluster
首先来看Cluster标签页。Cluster页显示了所有在Cluster模式下执行的SQL语句的实现过程与相关信息。
在Cluster模式下,每条语句的实现过程被分为了一个或者多个Stage,Stage是一个基本的执行单元,它又由多个Task构成。所以我们在Cluster页面上看到的都是各个Stage及其所包含的Task的信息。
Cluster页是对各Stage运行情况的宏观描述,描述内容主要涵盖了以下9个基本信息:
Stage的类型有三种:Active Stages、Completed Stages、Failed Stages。分别显示在Clusters页面的头部中部与尾部三个板块,对应的含义分别如下:
提供正在运行的Stage信息。执行SQL时,如果某个Active Stage的耗时较长,可以进入Description中所提供的链接查看Stage的具体细节。
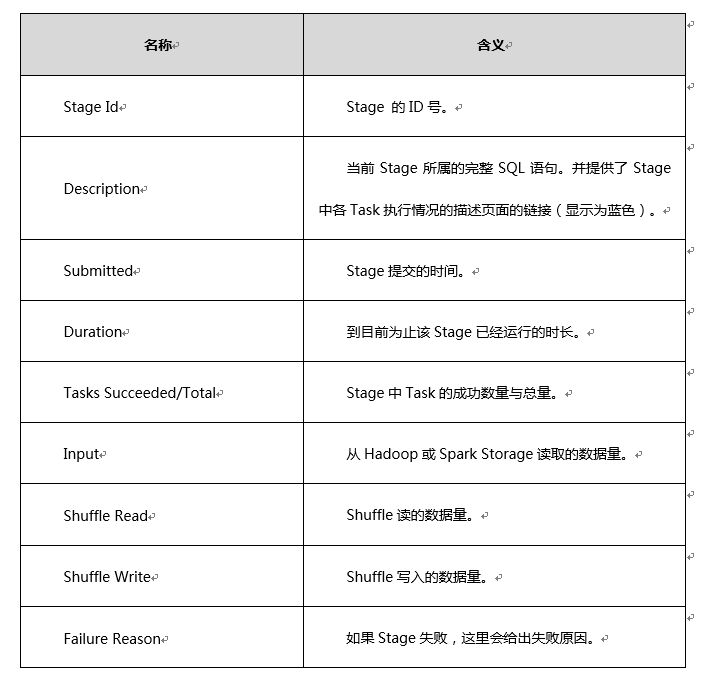
下面是一个Active Stage描述信息的示例:
从该图可以发现,Active Stage中成功Task数量和总数量是不相等的;而且在实际应用中我们会看到Active Stage的状态是处于实时变化中的。
该板块中,我们还可以通过"(kill)"按钮直接kill掉正在执行的Stage。
包含所有已完成的SQL语句的Stage信息。与Active Stage相同,此类Stage提供除了失败原因(Failure Reason)之外的所有基本描述信息,但不同的是Completed Stage的各信息状态是稳定的,而且成功Task数量总是等于总数目。
另外该列表还会提供实现该SQL语句所经过的Stage的总数量。
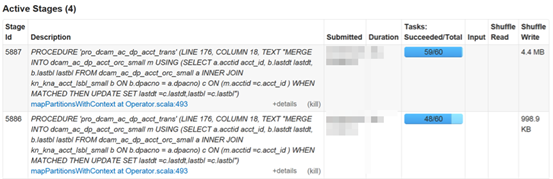
下面示例图提供了某条SQL语句所有Completed Stage的基本信息:
从上图可以看到,当前观察的这条语句被分为了4个Stage执行,每个Stage按照实现由先到后的实现顺序从下到上依次排列,即最上面的Stage是最新的,底部是最先完成的。
还可以发现,Task ID 号为7002和7003的Stage的Shuffle读和写的数据量分别为268.0B和538.0B,通过Shuffle Read和Shuffle Write的大小,用户可以获知Shuffle的数据量,从而判断当前的Shuffle是否给内存造成过大压力。
记录了所有执行失败的Stage的信息。对于此类Stage,管理界面会在Failure Reason一栏中给出具体的失败原因,此列内容很重要,对于问题分析和解决报错有很高的信息价值,当执行失败使请读者对此内容重点分析。
Failed Stage的信息显示结果示例如下:

从提供的失败原因可以知道该Stage的失败是因为ID为4300的Stage被kill掉,而导致后续相关Task都无法执行。
除了以上三种Stage的信息描述,Cluster页面还在页面左上角分别给出了这三类Stage的当前数量。如下图所示:

管理界面还可供查看每个Stage的工作内容、各个Task的执行时间、时间的统计信息、从属的Executor等Stage内部详细信息,以及不同Executor中Task的执行情况。呈现这类信息的页面链接提供于Cluster标签页的Description栏。此部分内容将在后面的文章中具体介绍。
Jobs
Jobs页面反馈了各个Job的执行信息与运行情况。每个Job由Stage构成。页面上对各Job的描述信息包括以下六个方面:Job Id、Description、Submitted、Duration、Stages:Succeeded/Total、Tasks(for all stages): Succeeded/Total。它们的代表含义和对Stage的描述信息一致,只不过是对整体Job的描述。
其中“Stages:Succeeded/Total”表示了该Job中成功执行的和全部Stage的数量;“Tasks(for all stages): Succeeded/Total”表示了该Job包含的所有成功的和总的Task数量。
通过点击Description中的链接进入Job的详细信息显示界面,可看到从属于此Jobs的所有Stage的信息。

进入该页面后,用户还可通过位于该页面左上角的DAG Visualization按钮获得当前Job的DAG。
DAG是表达各个RDD之间转换的关系的有向无环图,图形化的描述了各个操作符之间的传递顺序,直观的反映了Job执行的全过程。我们可以通过分析DAG,明确每一个Stage的任务内容,对于复杂的语句可以帮助锁定到出现性能问题的环节。
例如,对于如下语句:

该语句的内容可以大致分为三部分:第一个WITH-AS语句中的store_sales和date_dim的JOIN;第二个WITH-AS语句中的catalog_sales和date_dim的JOIN;两个WITH-AS短语的JOIN和聚合函数计算。
通过在管理界面上会观察发现该语句的执行被分为了两个Job。第一个Job负责扫描date_dim的数据,并结果放在HDFS上,为MapJoin准备。第二个Job负责了主要的工作,工作量较大,涉及的转换较多,过程较复杂,所以我们来对它的DAG进行分析,来看它的逻辑顺序是否是满足语句的实现需求。上述语句对应的DAG在管理界面上如下所示:
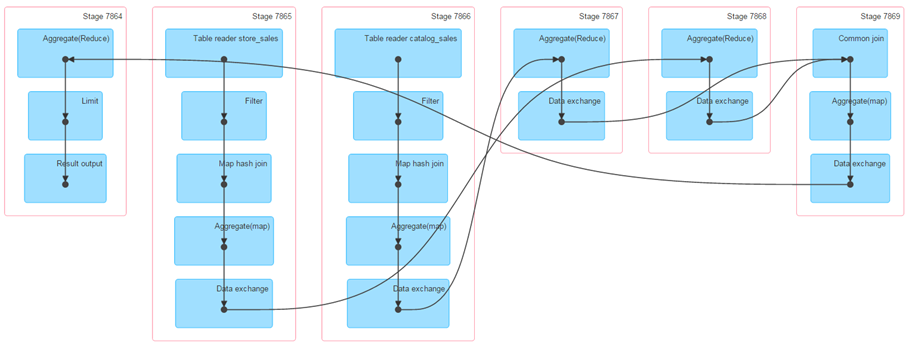
由图所示,该语句分为六个Stage执行。Stage ID号从2861开始分配至2866。每个Stage的内部由蓝色矩形纵向排列,表示该Stage内的RDD操作,操作名称显示在框内。箭头表示了RDD的转换走向。
由图可知,该Job从Stage 7865开始扫描过滤store_sales,接着和date_dim进行MapJoin,然后再通过Stage 7866在过滤catalog_sales后执行过滤结果集和date_dim的MapJoin。
接着Stage 7867和7868分别对这两个JOIN的结果Reduce,并把输出交给Stage 7869执行Common Join,最终Stage 7864又执行了一次Reduce并输出结果。
这样的执行顺序是完全符合语句的实现逻辑的。同理,读者可以借助界面提供的DAG去理解更复杂的SQL的实现过程,有效判断哪些环节出现了问题、哪些部分需要优化。
Jobs页面也根据Job的类型(Active Jobs、Completed Jobs、Failed Jobs)分别放在三个板块,分别提供正在执行的、已完成的、失败的Jobs信息。
使用总结
本文对Inceptor管理界面中的Jobs和Cluster两个标签页进行了简单介绍,分别简析了这两个页面上的字段信息含义。
在观察Cluster页面时,我们通常建议关注Stage的执行时间是否太长,失败Stage的数量是否过多,失败的原因是什么,每个Stage的Task总数是否过多或者过少以及成功Task的数量是否过少,Shuffle Read/Write的数据量是否过多。
类似的,在观察Jobs页面时,我们应观察Job的执行时间,失败Job的数量是否过多,失败Job中的失败Stage和失败Task的数量。另外,有了DAG的帮助,我们还可以理解Job的实现流程,Stage的工作内容,将成功和失败的Stage分别对应至具体的操作符。
在实际使用时,除了需要理解页面上各个字段所代表的含义,读者还应该分析出这些指标的高低所反馈的信息。我们会在今后的文章,结合后续内容,介绍如何根据这些指标数值提取信息进行性能优化。
————————
往期回顾:
技术|Kappa:比Lambda更好更灵活的实时处理架构
技术|TDH的图形化集群服务指标监测工具及其使用方法介绍
技术|深入浅出解析大数据Lambda架构
关于:本文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————
