基础介绍
作为一个分布式大数据处理平台,Transwarp Data Hub(TDH)中的服务通常有多个角色,例如HDFS服务角色包括NameNode (NameNode又分Active NameNode和Standby NameNode)、多个DataNode和多个JournalNode。每个角色都有一系列的指标来衡量其健康状况,所有角色的健康状况决定了服务的健康状况。指标多固然给集群的运维人员提供了很多关于服务的信息,但也使得服务的关键性指标“淹没”在大量指标之中,不易查找;另外,一些需要结合使用的指标散落在集群各处(例如YARN的资源和Inceptor的资源),逐个收集和汇总十分繁琐。
为了节省运维人员的时间,帮助运维人员更加直观、方便地查看服务状况,Transwarp Manager提供了汇总的指标图表页面:
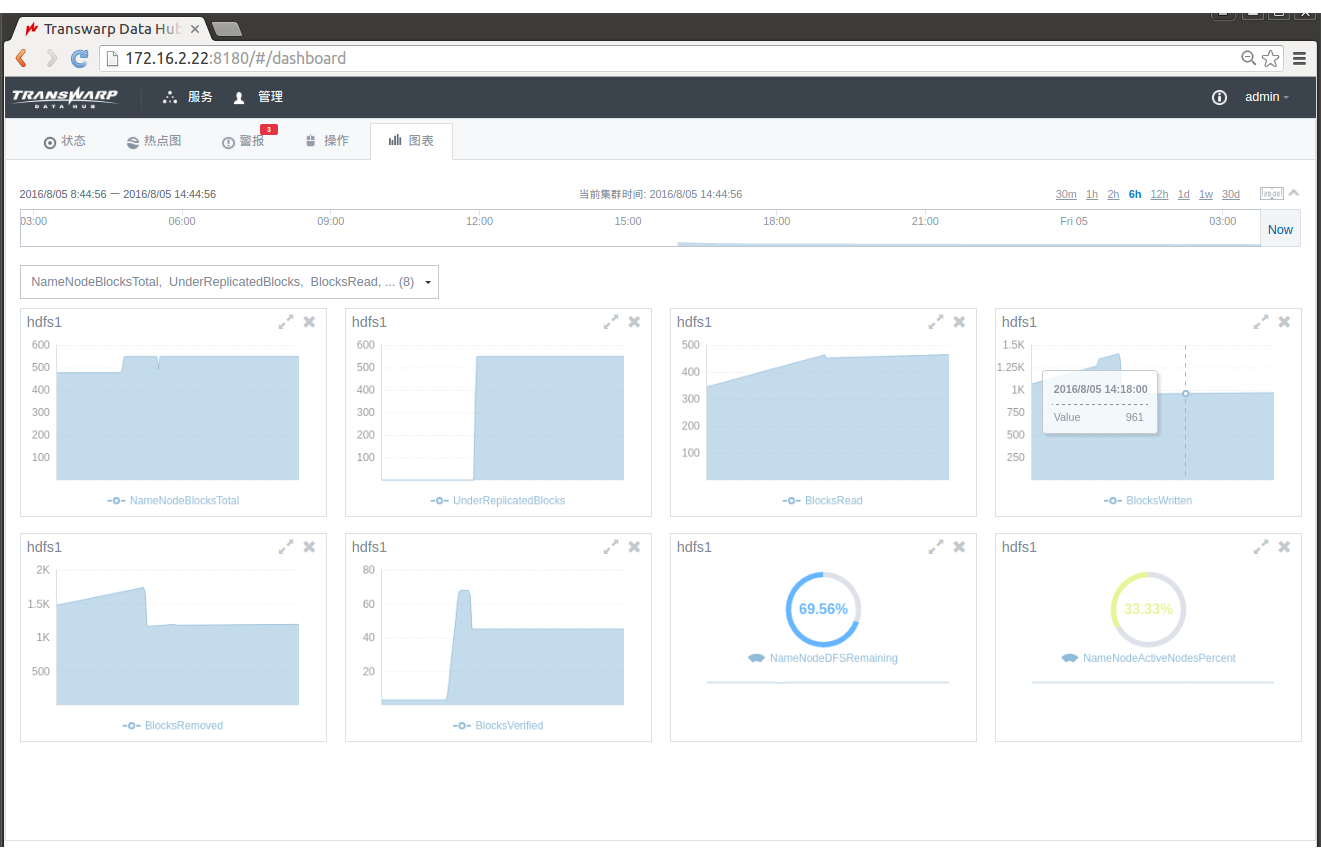
Transwarp Manager选取了每个服务最关键的几个指标作为指标图标页面的选项,在指标列表中勾选即可让想要查看的指标汇总在同一个页面上展示:

有了指标图表页面的帮助,运维人员可以一目了然地查看集群的关键指标,将不同服务的指标结合使用、对指标进行横向对比、观察指标随时间的变化等等。
指标图表监控实例:HDFS的指标监控
作为演示,下面我们将在一个由三台服务器组成的测试集群上触发一个关键性的HDFS事件——DataNode宕机,看看指标图表页面对这些事件的反馈。实际生产中,事件和指标的关系将是反过来的——运维人员需要根据指标的反馈来判断发生了什么HDFS事件。
【演示环境中的服务角色】
172.16.2.22: Active NameNode, DataNode和JournalNode
172.16.2.23: Standby NameNode, DataNode和JournalNode
172.16.2.24: DataNode和JournalNode
我们关闭一个DataNode。此时,Transwarp Manager的警报页面立刻给出了一个告警——DataNode不健康:
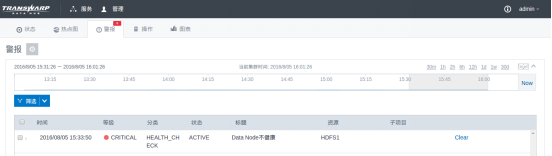
大约十分钟后,NameNode由于过久收不到来自这个DataNode的心跳,判定其死亡。指标图标页面发生了两个较大变化:
活跃的DataNode从显示100%变为显示66.67%,也就是2/3的DataNode存活;
UnderReplicatedBlocks(备份不够的数据块)从0变为549,和总数据块数目相同。
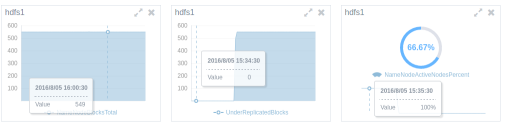
这两个变化都符合预期:
显而易见,集群中原来有3个活跃的DataNode,停止一个后活跃的DataNode剩余66.67%;
测试集群的HDFS的Replication Factor为3,也就是说每个数据块包括自己有3个备份,并且存在不同的DataNode上。因为测试集群中只有三个DataNode,每个DataNode上都包含所有数据块的一个备份。当任何一个DataNode停止运行,集群中的数据块都将只有两个备份,由于少于Replication Factor,被NameNode判定所有数据块都备份不够。
将被停止的DataNode启动后,我们看到活跃的DataNode重新变为100%,并且UnderReplicatedBlocks数量降为0——所有数据块都有三个备份:
总结
Transwarp Manager为TDH用户提供了一个全面了解各服务活动状态以及性能指标的平台,促进问题发现的及时性,并在探索问题根源时提供有效的线索。利用它可以极大的提高运维效率,减少运维工作的成本投入。所以会灵活应用并分析Transwarp Manger的性能指标界面,是使用TDH产品过程中的一项关键能力。
(正文内容到此结束)
往期回顾:
一站式rJava自主开发的应用实现
技术|深入浅出解析大数据Lambda架构
关于:此文由公众号大数据开放实验室原创
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
