来源:大数据开放实验室
许多机器学习引擎例如Transwarp Discover,通常内置有大量常用的机器学习算法:包括统计算法、分类算法、聚类分析、回归分析、频度关联分析和神经网络等,用户可以通过它们快速地构建大规模数据挖掘系统和方案。但是,如果用户之前已经积累了一些自己的算法,同时又希望能够使用引擎本身提供的机器学习算法库,这个时候就会出现一个兼容性问题:如何让自由算法和已有算法库一起发挥作用?
为了帮助用户完美解决引言中提出的兼容性问题,Transwarp Discover在4.6版本推出了一个新功能——一站式rJava自主开发,使自由算法和内置算法库得以在Discover中共同运作。用户只要下载星环科技提供的一站式工程文件,直接在该工程下编写自己的算法,然后加载到Discover中,就可以在Rstudio中调用自主开发的新算法。新加载的算法还可以通过指定权限的方式共享给集群上的其他用户。
rJava的详细教程请读者参看星环科技官网上的Transwarp Discover rJava自主开发手册。这里我们通过一个具体的例子以简单介绍它的应用方式。
自主开发流程简介
Discover中rJava的自主开发流程分为以下几步:
1. 下载一站式工程文件rJavaApp.rar,下载链接:https://pan.baidu.com/s/1boLaFRT 密码: e45y;
2. 使用Intellij IDEA打开解压后的工程文件,新建Scala或Java脚本,并编写新算法的代码;
3. 将调试通过的代码编译打包成.Jar文件;
4. 通过Discover Rstudio平台上的“upload”交互方式将Jar包上传至集群;
5. 基于Discover R函数txAddJar和txGrant实现对Jar包中用户自主开发的类和方法进行调用及共享。
基于rJava的自主开发步骤
K-Means算法是最简单的一种聚类算法,但是我们都知道,传统的K-Means算法的初始聚类中心是随机选取的,聚类的精确程度不高,如果基于数据样本密度和距离对初始中心点的选取进行改进的话,聚类的精确程度会大大提高。现在我们根据某一给定场景的特性,通过一站式工程文件对该场景进行K-Means新算法的开发,并且把新算法上传到Discover平台,在Rstudio中进行调用。
1. 下载并解压一站式工程文件rJavaApp.rar,并使用Intellij IDEA打开工程文件,如下:
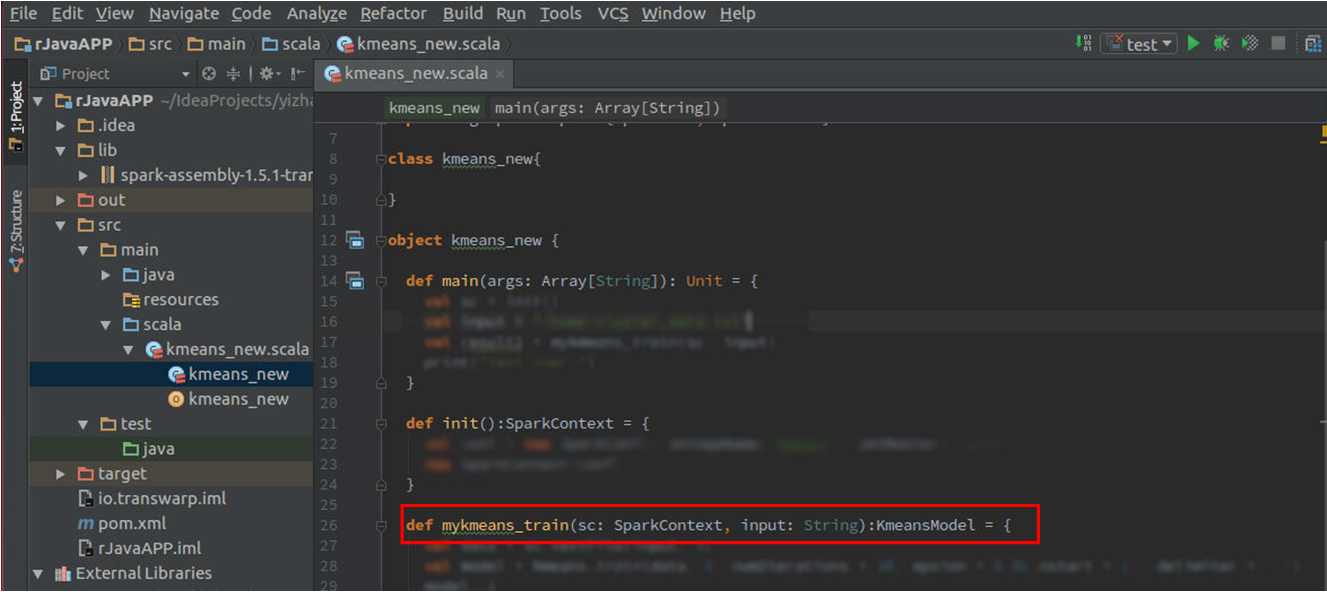
2. 新建scala脚本,并编写新算法代码
3. 对工程进行调试,调试成功后,将其编译打包成.Jar文件
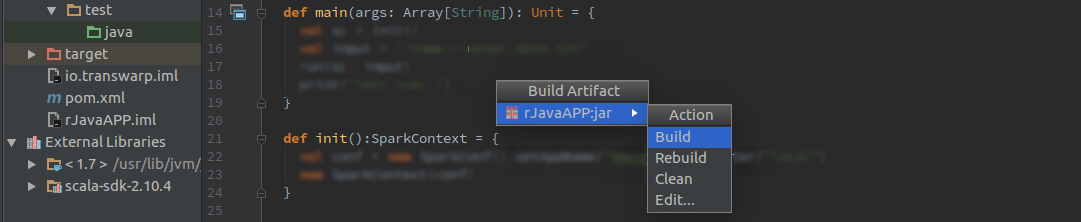
Build后的Jar包位置在当前工程的out目录下,out/artifacts/rJavaApp_Jar/rJavaApp.Jar

4. 在Rstudio界面,将生成的Jar包上传到Discover平台

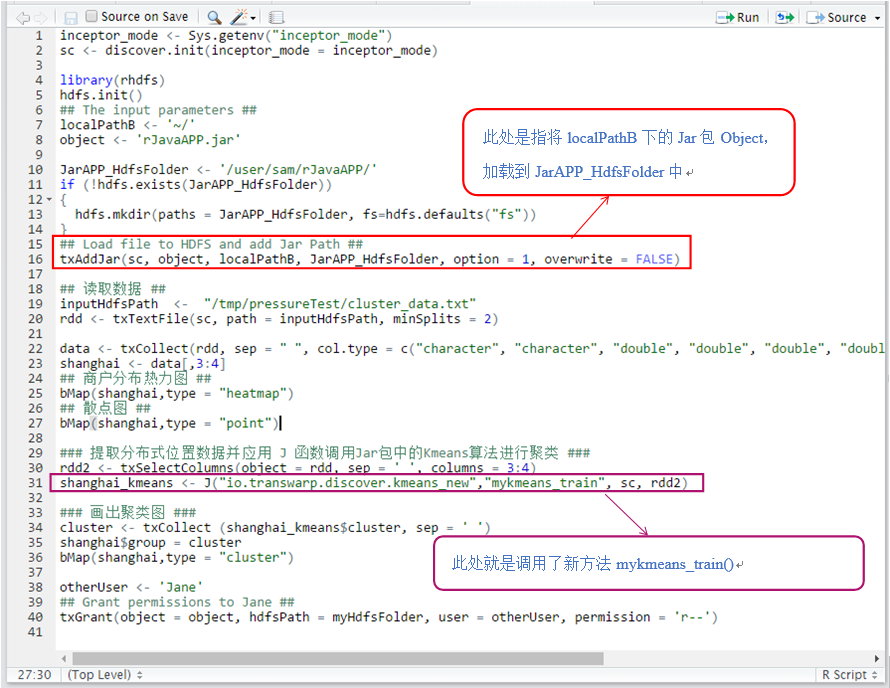
5. 现在就可以调用Jar包中的新算法了,在调用Jar包的新算法之前,需要使用txAddJar函数将Jar包加载到自己的HDFS中,具体参数和用法可以在Rstudio中使用“?txAddJar”查看。示例代码如下:
6. 下面是分别利用传统的K-Means算法和新的K-Means算法对上海地区商家的经纬度进行聚类分析的结果。图1是上海地区商家经纬度热点图,图2是上海地区商家经纬度散点图,图3是传统K-Means算法聚类结果,图4 新的K-Means算法聚类结果:
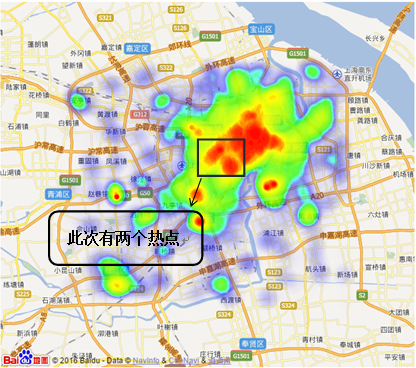
图1 上海地区商家经纬度热点图
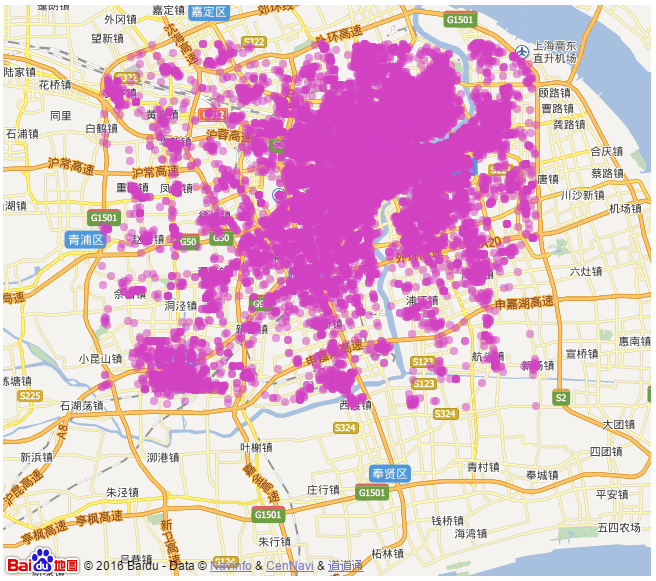
图2 上海地区商家经纬度散点图
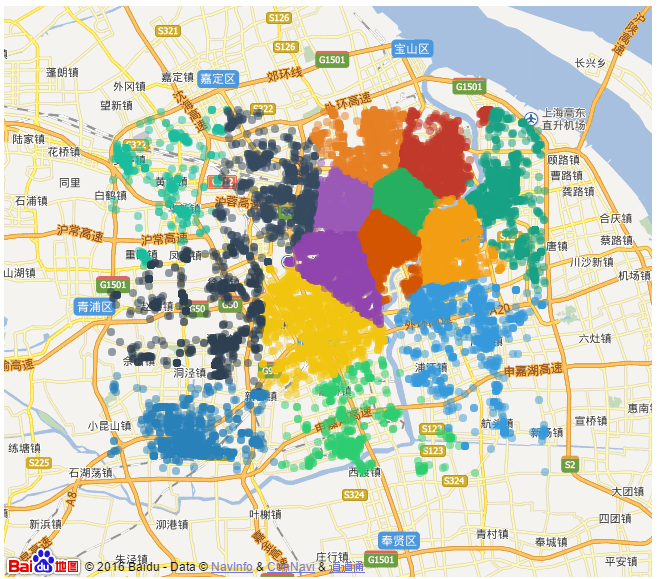
图3 传统K-Means算法聚类结果(不同颜色代表不同类)
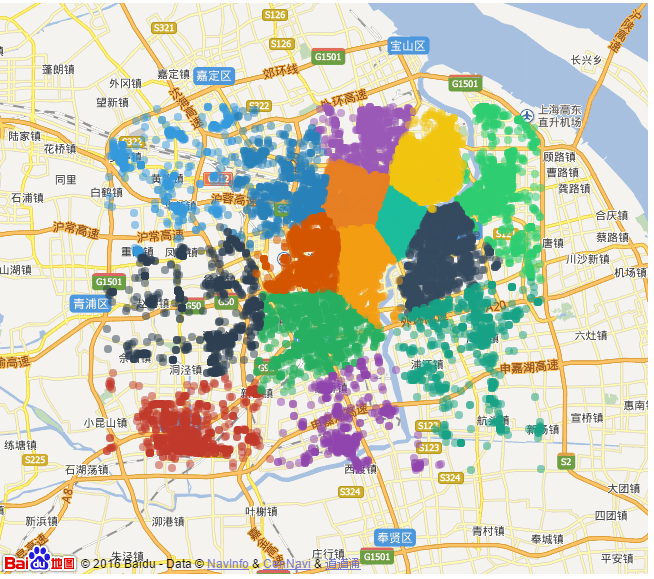
图4 新的K-Means算法聚类结果(不同颜色代表不同类)
从图中我们可以看到,针对于本数据集,新开发的K-Means算法聚类精度要比传统的K-Means算法稍微好一些,不过如果要证明新算法优越性还需要依靠大量的数据实例,但是至少证明了一点,在Discover平台上扩展自主开发的新算法是一件比较简单方便的事。
7. 新上传的Jar包还可以通过txGrant函数通过指定权限的方式共享给集群上的其他用户,txGrant函数的使用方法也可以通过“?txGrant”的方式进行查看。示例代码如下:
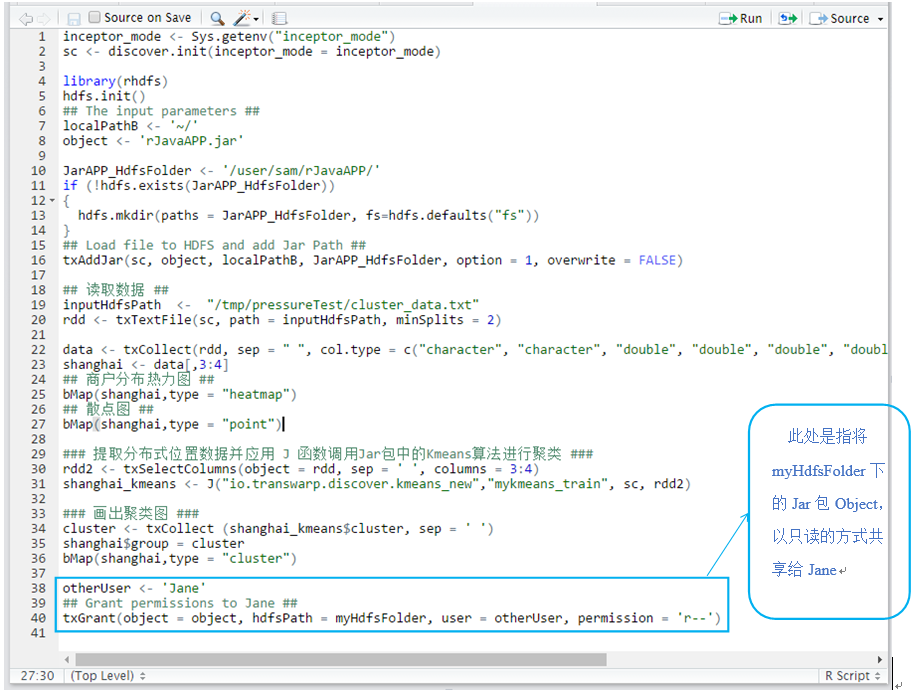
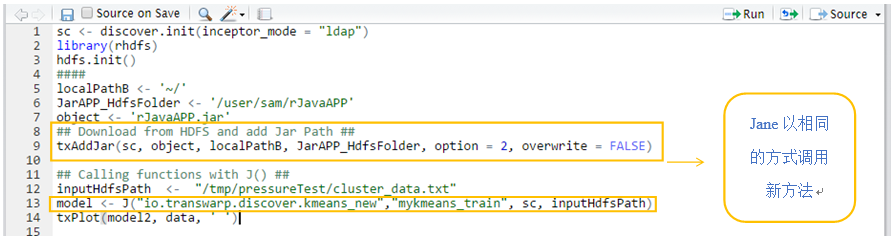
Jane有了使用Jar包的权限之后,可以通过下面的方式调用:
总结
从上面的实例中可以看出,一方面,rJava自主开发的方式无缝衔接了R语言和Java算法开发,使得熟悉Java/Scala语言的机器学习人员能够将自主开发的算法,上传到Discover平台,在Rstudio平台进行调用;另一方面,原本就内置有6000多种机器学习和数据挖掘算法,并提供了文本分析、交易反欺诈、风险分析、推荐系统、故障检测等多个行业模型的Transwarp Discover,如今,再配合用户自主开发的其他算法,适用性变得更广,灵活性也变得更强。
(正文内容到此结束)
往期回顾:
技术 | Docker+Jenkins打造自动化测试以及部署
技术 | 从数据挖掘经典算法PageRank入门Graphene
关于:大数据开放实验室
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
