来源:大数据开放实验室
PageRank是Google研发的主要应用于评估网站可靠度和重要性的一种算法,是进行网页排名的考量指标之一。本文将对PageRank的原理进行讲解,并以此为出发点介绍如何利用Transwarp Data Hub的Graphene在实际中满足相关分析需求。
在开始PageRank原理介绍之前,请读者先阅读下面这则案例:
有一个借贷俱乐部,共100位成员,俱乐部的每位成员都有一个借贷“诚信指数”,用来表示该成员的可靠程度。现在来了一个新的成员小白,他打算将自己的5万块钱放贷给俱乐部的人,假设俱乐部中每个人都有相等的贷款需求而且有相同的支付贷款利息的能力,小白希望把钱借贷给最让人放心的成员,即找到“诚信指数”最高者。
首先小白收集了俱乐部的一些信息,包括所有成员名单和俱乐部内部成员间的信任关系(谁信任谁)。然后使用0-99之间的连续整数对100位成员分别进行编号,并利用所有人之间的信任关系组织成一张图(图1)。其中信任关系依靠有向箭头表明,例如“87 –> 92”表示87号成员信任92号成员:
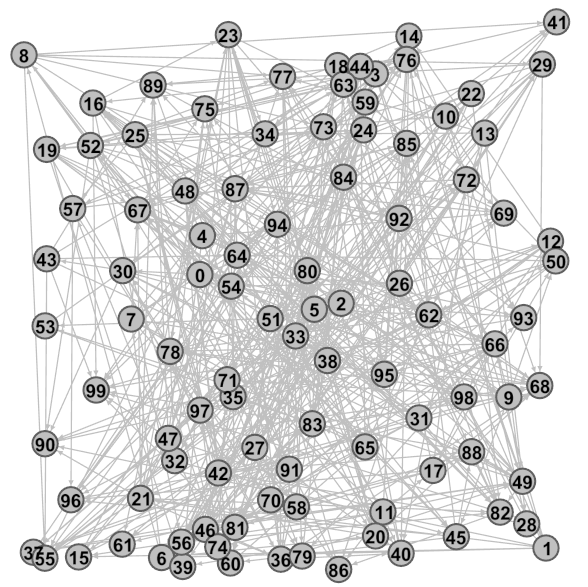
图 1 计算“诚信指数”之前的成员信任关系图
接着小白根据下面两条规则计算对上图中的每个节点计算“诚信指数”。
节点作为箭头终点的次数越高(即入度越高),“诚信指数”越高。
高“诚信指数”的节点会提高被它指向的节点的“诚信指数”。
根据这两条原则,小白对代表俱乐部每位成员的100个节点分别计算出了各自的“诚信指数”,绘制出了图2。其中,面积越大颜色越深的节点“诚信指数”越高,反之则越低;并且每位成员出发的边的颜色与该成员对应的点的颜色相同。
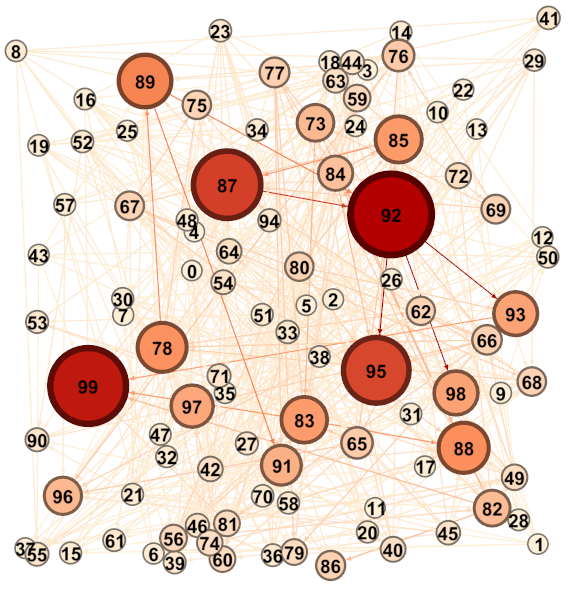
图 2 计算“诚信指数”之后的成员信任关系图
由图2小白可以得到这样的结论:92和99是可靠度最高的两位成员,对这二者放贷的风险较低。
在此过程中可以发现,实现从图1到图2的转变最重要的就是遵循计算“诚信指数”的两条规则,而这两条规则实际就是PageRank算法的核心。
PageRank算法介绍
现在来正式介绍PageRank算法的概念和原理:
PageRank简介
PageRank算法是一种链接分析算法,由Google提出并用于标识网页重要性。PageRank算法基于两个假设:
1)入链数量假设:如果一个网页的入链数量越多,则其重要程度越高。
2)入链质量假设:高质量的网页为其链接的页面带去更多权重。
以上两个假设分别对应小白规则一和规则二。基于这两条假设,PageRank算法为每个页面设置初始权重值,根据网页间的链接关系,在多轮迭代中更新每个网页的权重,直至各页面的权重值稳定。不考虑作弊的情况,我们通常将最终权重值越高的节点视为越可靠网页。
PageRank算法原理
1)简化公式
PageRank算法的简化公式如下所示:
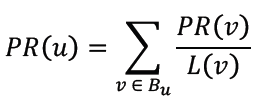
其中L(v)表示网页v的出链数量,PR(v)表示网页v的PageRank值,Bu表示网页u的入链集合。从该公式不难看出,每个页面的PageRank值是由其所有入链网页的PageRank值累加得到。
2)阻尼系数(Damping Factor)
PageRank算法可以视为对网页跳转的模拟,当有些网页只有入链而没有出链时,则无法从这些网页跳转出去,使得每个网页的PageRank值最终为0。下图给出了这个问题的实例,网页C没有到其他页面的链接,随着算法的不断迭代,每个网页的权重值不断减少,最终收敛于0。
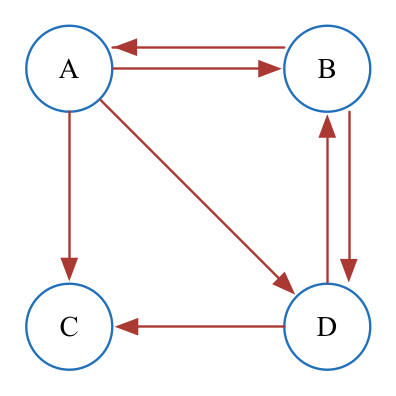
为了避免上述问题,在算法中引入阻尼系数d,作为网页随机跳转的概率。PageRank的计算公式也被修正为:
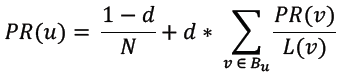
其中d为常数,一般取值为0.85。
Graphene实现PageRank
Graphene介绍
Graphene是由星环科技研发的专门处理和分析大规模图数据的分布式图计算平台。其中,“图计算”是一种在以“图论”为基础的数据结构上的计算模式。科学研究和实际生活中的典型图数据有:web图,社交网络图,信息网络图,生物网络图以及机器学习中推荐相关的图数据等。针对不同的应用场景中的各种不同问题,有不同的图计算需求,相应的就有很多不同的图算法,PageRank就是其中之一。
Graphene提供了多种图算法以满足不同用户对不同场景的需求,其中包括PageRank。为了方便用户把焦点放在图模型的设计和分析,而不是算法的实现上,Graphene将复杂的PageRank并行计算过程封装起来,为用户提供方便可靠的算法函数graph_pagerank()作为接口,得以使实现细节对上层透明。
操作过程
在Graphene中调用graph_pagerank()实现PageRank的操作过程分为三个步骤:数据准备,“诚信指数”计算,结果收集。下面以开篇的案例为例,对实现PageRank的每个步骤做以详细说明。
1) 数据准备:首先需收集成员信任关系数据,并按照下图中以边列表(edgelist)的格式存储在HDFS下的文件中(假设该文件在HDFS中的位置为:/tmp/graphsql/credit_data/credit_data.txt)。列表中每一行代表图中一条边,每条边包括源节点Source和目标节点Target,表明成员Source信任成员Target。我们以第二行“80 93”为例,它表示编号为80的俱乐部成员信任编号为93的俱乐部成员。

2)“诚信指数”计算:准备好以上数据后,请在Graphene中执行下列语句:

3) 结果收集:Graphene计算成功后会将结果保存在本地文件夹 /tmp/D_pagerank_credit_data_result 中,打开该文件夹中的数据,就可以看到如下的结果内容(这里仅给出前20行)。每一行代表一个俱乐部成员的编号(id)和他的“诚信指数”(pageranks),pageranks越高,就说明越可靠。
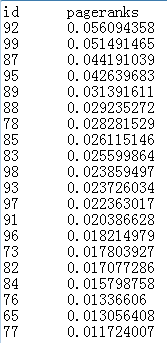
可以发现该文档中的数据和图2中点的大小和颜色是对应的。比如92和99排第1和2名,也就是图中颜色最深最大的两个点。
Graphene性能
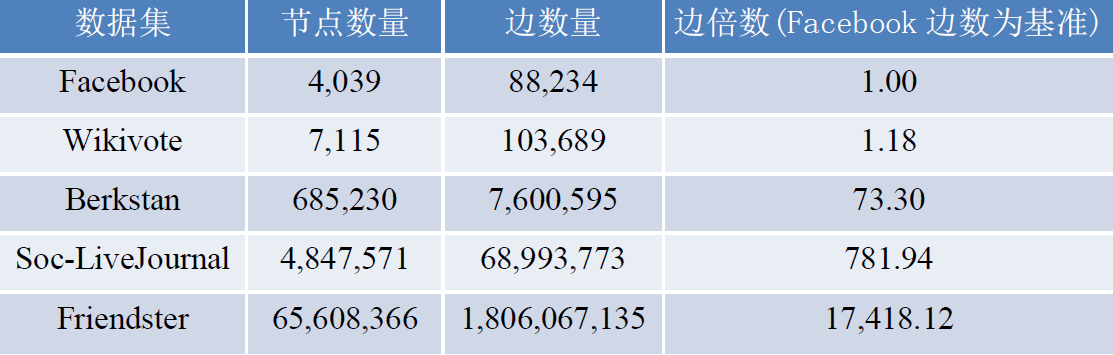
本次测试在不同数据集下测试Graphene平台中实现的PageRank算法的执行效率,算法迭代次数为10。测试所用数据集来自SNAP。
【测试环境】

【测试数据集】
【测试结果】
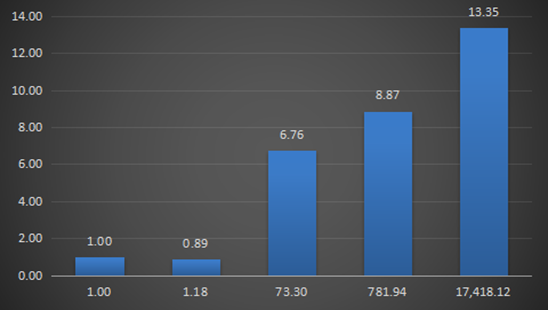
上图中的横坐标是每个数据集的边数相对于Facebook数据集的倍数,纵坐标是Graphene中的PageRank算法在每个数据集上的运行时间与相对于在Facebook数据集上的运行时间的比值。我们可以发现,虽然数据集边数以指数级增长,但是运行时间却是线性增长,这体现了Graphene能够很好的处理不同规模的数据集,特别是大规模的图数据。
另外我们还对Graphene同两个较主流的开源图计算平台——Spark中的GraphX和Facebook的Giraph,进行了比较。在上面相同的测试环境下,主要针对文件大小为33.5G,图中顶点数6千5百多万,边数为18亿多的大规模Friendster图数据进行了PageRank算法运行性能的对比。我们发现在测试环境相同的情况下Graphene正常完成完成10次迭代计算,而Giraph和GraphX都报了OutOfMemory的错误,算法无法正常完成。
通过测试对比,我们验证了Graphene能够对大规模数据提供可靠的PageRank算法支持,并且能力强于Giraph和GraphX。
【最后,附上Graphene分布式图计算平台中PageRank的调用方法和使用实例】

————————————
关于:大数据开放实验室
大数据开放实验室由星环信息科技(上海)有限公司运营,专门致力于大数据技术的研究和传播。若转载请在文章开头明显注明“文章来源于微信订阅号——大数据开放实验室”,并保留作者和账号介绍。
————————————

