
进入正题之前,首先来看几个问题
1. 垃圾邮件判定问题

如何判断这封邮件是不是垃圾邮件呢?
2. 作品所属人问题
• 1787到1788年: 有多篇匿名短文试图让美国宪法批准纽约州,短文的作者来自Jay, Madison, Hamilton。 • 有12篇短文的作者尚待确定 • 1963年: Mosteller 和 Wallace用贝叶斯方法解决了

3 判断是男性作者还是女性作者
下面这两段是男性写的还是女性写的呢?
By 1925 present-day Vietnam was divided into three parts under French colonial rule. The southern region embracing Saigon and the Mekong delta was thecolony of Cochin-China; the central area with its imperial capital at Hue was the protectorate of Annam…
Clara never failed to be astonished by the extraordinary felicity of her own name. She found it hard to trust herself to the mercy of fate, which had managedover the years to convert her greatest shame into one of her greatest assets…
来自:S. Argamon, M. Koppel, J. Fine, A. R. Shimoni, 2003. “Gender, Genre, and Writing Style in Formal Written Texts,” Text, volume 23, number 3, pp 321–346
4 电影评价
正性还是负性电影评价?  • unbelievably disappointing
• unbelievably disappointing  • Full of zany characters and richly applied satire, and some great plot twists
• Full of zany characters and richly applied satire, and some great plot twists
• this is the greatest screwball comedy ever filmed • It was pathetic.The worst part about it was the boxing scenes.
5 判断文章主题

相关主题层次结构
• 拮抗剂和抑制剂 • 血液供给 • 化学 • 药物疗法 • 胚胎学 • 传染病学 • …
对于以上几个问题,可以概括一下,文本分类主要涵盖了以下几个问题:
• 学科分类,主题或流派 • 垃圾邮件识别 • 作者标示 • 年龄性别标示 • 语言识别 • 情感分析 • …
文本分类的定义如下:
• 输入:
• 文档 d • 固定的类别集合 C = {c1, c2, …, cJ } • 输出:预测类别 c ∈ C
想要进行分类,首先要有特征,文本分类中有一种获得特征的方式,即硬编码规则
• 由一些单词或其他特征构成的规则 垃圾邮件:邮箱在黑名单列表里或者邮件包含 “dollars” 和 “have been selected” • 如果规则由相关领域的专家来定义,则可以得到高准确率 • 但是构建并且维护这些规则代价较高
文本分类问题对应的有监督机器学习问题具体如下:
• 输入
文档 d 固定的类别集合 C = { c1, c2,…, cJ } m个人工标注文档构成的训练集 (d1,c1), ... ., (dm,cm) • 输出
学习得到的分类器 γ: d →c
其中有监督机器学习中的分类器可以是以下任何一种分类器:
• 朴素贝叶斯 • 逻辑回归 • 支持向量机 • k-近邻分类器 • …
下面进入正题----朴素贝叶斯方法
首先给出朴素贝叶斯的直观解释
• 简单(朴素)的基于贝叶斯规则的分类方法 • 依赖于文档的非常简单的表示,比如单词袋 (Bag of words)
单词袋表示对应的过程如下:


利用加黑单词可以得到如下的单词袋子集

然后通过简单的统计词频即可得到

单词袋
用于文档分类示例如下

前面介绍了一些基本问题,那么如何形式化朴素贝叶斯分类器呢?如何将贝叶斯法则用于文档和类别?
对于一篇文档 d 和类别 c ,容易得到
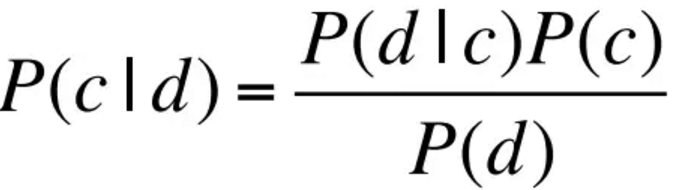
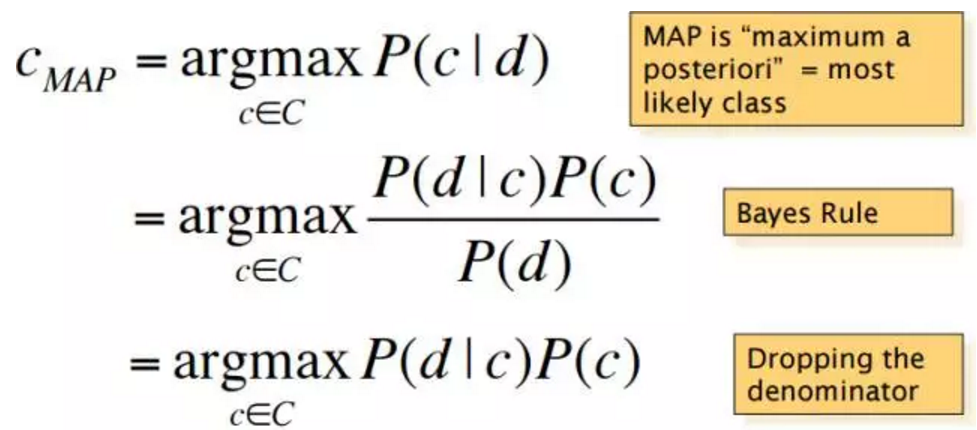
其中MAP是最大化后验概率, 第二步是利用了贝叶斯法则,第三步是因为分母跟类别无关,所以可以去掉。
然后,可以得到
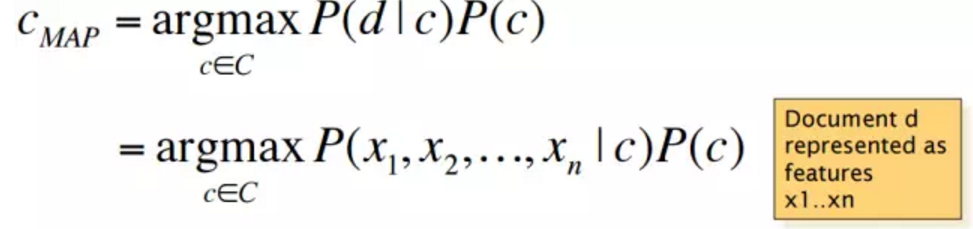
文档d可以用相应的特征x1, ..., xn来表示。

怎么才能知道每个类别出现的可能性有多大?为了顾及前一项,只有当一个非常非常大的训练样本集存在时,才可以估计出来每个类别出现的可能性。为了计算每一类出现的可能性,只需要计算语料库中的相对频率。
多项朴素贝叶斯独立性假设

• 单词袋假设:假设单词位置无关
• 条件独立假设: 假设概率P(xi | cj )在给定类别c时是相互独立的
数学表示如下式:

多项朴素贝叶斯分类器形式如下:
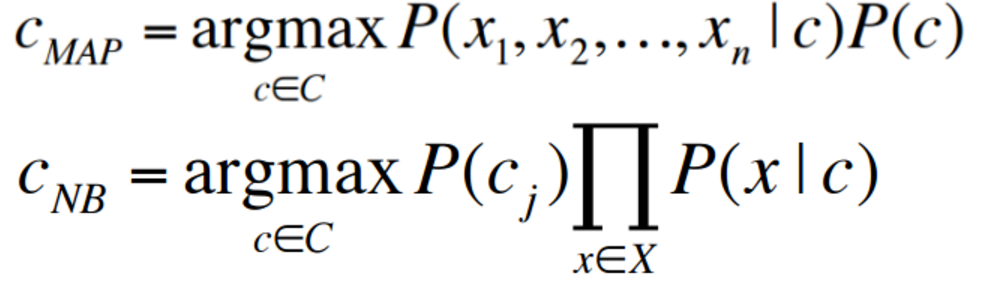
如何将多项朴素贝叶斯用于文本分类问题呢?首先假设 positions ← 测试文档中所有单词的位置构成的集合,则

怎么学习多项朴素贝叶斯模型呢?
可以利用最大似然估计法来学习多项朴素贝叶斯模型。基于频率可以得到:
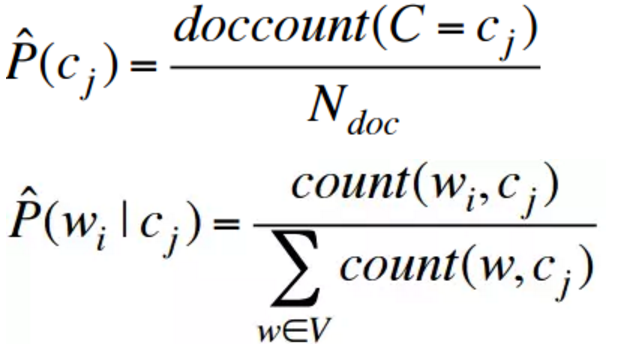
参数估计:

其中分子表示单词 wi 在主题为cj的文档中出现的次数,分母表示主题为cj的文档中所有单词出现次数之和。
对于分母,可以利用以下方法来计算
• 将所有主题为 cj 的文档合并起来创建一个大型文件 • 利用大型文件中w的频次来计算分母
最大似然法有一定的问题,比如,如果训练文档中没有单词fantastic, 而且主题是积极肯定的,那么下面的概率就会为0

由下式可以知道

只要有一项概率为0, 则整体就会为0。
为解决上述问题,可以利用拉普拉斯平滑算子来优化此问题:

多项朴素贝叶斯的学习过程如下:

其中,α是拉普拉斯平滑因子。
朴素贝叶斯跟语言模型有什么关系呢?首先来看下多项朴素贝叶斯的生成式模型

朴素贝叶斯跟语言模型对比总结
• 贝叶斯分类器可以利用任何一种特征
• 比如URL, 邮箱地址, 字典, 网络特征 • 但是如果只利用文字特征,并且利用文本中的所有单词(而不是一个子集, 则朴素贝叶斯跟语言模型相似性非常大
朴素贝叶斯中的每一类都是一个一元语言模型
• 每个单词的判定概率: P(word | c) • 每个句子的判定概率: P(s|c) = Π P(word|c)
如下面的例子:

其中class pos 表示积极类别。
朴素贝叶斯可以看作语言模型,下面的问题是判断哪一类产生以下句子的概率更大一些。

下面看一个多项朴素贝叶斯的例子:

用到的两个公式如下:


在训练集中,通过简单的频数统计,即可得到以下先验知识:

也可以下面的条件概率:

其中分母中加的6是单词的(去重)总数。
测试样本分为两类的概率分别如下


接下来,再回到如何将朴素贝叶斯用于垃圾邮件过滤中。垃圾邮件过滤相关的特征有以下几个:
• 提到仿制“伟哥” • 线上药店 • 提到百万美元 ((dollar) NN,NNN,NNN.NN) • 短语:留下深刻印象 女孩 • 发件人邮箱:由很多数字开头 • 主题全是大写字母 • HTML 中图片所占区域的占比多于文本占比 • 百分百保证 • 声称你被移除列表 • '有名望的非公认大学' • http://spamassassin.apache.org/tests_3_3_x.html
简单总结:朴素贝叶斯并不那么朴素
朴素贝叶斯具有以下几个特点
• 速度很快,存储需求低 • 对无关特征具有鲁棒性,即去掉无关特征不影响结果 • 很多特征重要性一样的领域中,效果较好,而决策树会呈现碎片现象,尤其是数据量较少时 • 如果独立性假设成立,则朴素贝叶斯效果最优:如果独立性假设是正确的,则朴素贝叶斯是最优的贝叶斯优化分类器
• 文本分类问题中一个可信赖的基准分类器,但有些分类器准确率会更高
接下来看看精准率,召回率以及F测度。
先看一个2×2的列联表

其中精准率和召回率的定义如下:
精准率:tp/(tp+fp)召回率:tp/(tp+fn)
基于准确率和召回率衍生出来一个测度,即F测度。F测度是折衷了准确率和召回率而得到的,它是对准确率和召回率的加权调和平均:

注: 令α=1/(β^2+1)即可得到上面等式的变换。
实际中,比较常用的是F1测度,即β = 1 (意即 α = ½),此时 F = 2PR/(P+R)
上面讨论的是二分类问题,那么如何扩展到多分类问题呢?多分类问题可以转化为多个二分类问题来解决。
对于多值分类问题,一个文档可能属于多个类,或者属于一个类,又或者不属于任何一个类。对于每个类 c∈C, 构建一个分类器 γc,将类 c 跟其他类 c’∈C 区别开来。给定测试文档 d, 可以利用每个 γc 来预测它的类别, 如果某个γc 返回真,则文档 d 属于这个类。
另外一种情况,类别之间是相互排斥的,每个文档只能属于一类。对于每一类 c∈C,构建一个分类器将类别 c 与所有其他类别 c’ ∈ C 区别开。给定测试文档 d, 利用每个 γc 来预测文档的类别, 文档 d 属于那个得分最高的类。
下面在数据集上来评估朴素贝叶斯分类器,数据集Reuters-21578是一个比较经典的数据集,也是用得比较多的数据集,9603篇文章用来训练,3299 篇用来测试 (ModApte/Lewis 分割), 共 118 个类别。每篇文档可以属于多个类,共学习118个二分类器。平均每篇文档有1.24个类别。118个类别中只有将近10个类别覆盖的文档较多。这10个类别的训练测试样本数示例如下, 格式:(#train, #test)
• Earn (2877, 1087) • Acquisitions (1650, 179) • Money-fx (538, 179) • Grain (433, 149) • Crude (389, 189) • Trade (369,119) • Interest (347, 131) • Ship (197, 89) • Wheat (212, 71) • Corn (182, 56)
对于每一对类别,多少c1类的文档被错分成c2类呢?从下面的混淆矩阵可以看出,在下表中的 c3,2: 90 个小麦为主题的文档被错分成家禽类别的文档

对于每个类别的测度如下:
召回率: 样本集中第i类的文档被分为第i类文档的比例;

精准率: 被分为第i类文档中确实是第i类文档的比例;

准确率: 1-错误率 即正确分类的文档占比;

平均法可以分为微观与宏观平均法,如果有多个类,如何将多个性能度量组合成一个量?
• 宏观平均法: 对每个类计算效果,然后取平均; • 微观平均法: 对所有类获得相应决策, 计算列联表,然后评估
平均法示例
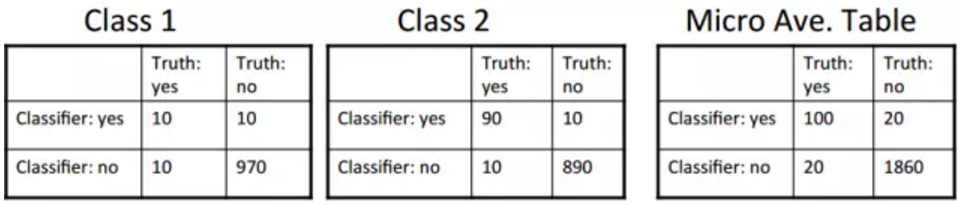
• 宏观平均精准率: (0.5 + 0.9) / 2 = 0.7 • 微观平均精准率: 100/120 = 0.83 • 微观平均评分由共同类别的评分来决定
开发测试集与交叉验证

• 度量标准: 精准率/召回率/F1 或者准确率 • 未知测试集合 •避免过拟合 (适合测试集合) • 对性能更保守的估计; • 根据不同的数据集,处理样本误差;
• 从每个分割获取结果 • 每个分割效果较差 • 计算开发测试集合上的性能
图示如下:

实际中可能遇到的问题:
正在为实际问题构建一个文本分类器,如何操作呢?
如果没有训练数据,则人工书写规则
如果是小麦或稻谷,并且不是整体或面包,则将类别定为稻谷
需要比较仔细的人工设计
• 在开发数据上人工调节; • 耗时:一个类需要两天
如果数据较少怎么处理呢?
• 利用朴素贝叶斯方法 • 朴素贝叶斯是一种高偏差的算法
• 获取更多有标签的数据 • 需要寻找一种有效的方式来给数据打标签 • 尝试半监督训练方法 • 比如 Bootstrapping,对于无标签数据利用 EM 算法, …
如果有一定数量的数据如何处理?
• 所有“聪明的”分类器都很好 • 比如 SVM • 比如正则化的 Logistic Regression • 也可以利用解释性较强的决策树 • 用户比较喜欢 • 比较像快速固定法
有大量数据的情形
• 可以获得高准确率 • 代价在于: • SVMs 的训练速度较慢, kNN的测试速度较慢 • 正则化的 logistic regression 效果可能会比较好 • 此时朴素贝叶斯又可以派上用场了
准确率会随数据规模的变化而变化,可以看出,如果有足够多的数据,从准确率角度来看,选择何种分类器并不是那么重要

实际问题中通常结合以下两点:
• 自动分类 • 人工复查 不确定的/难分的/新 样例
有时可能需要防止下溢,对应的策略:转化到对数空间
• 很多概率相乘会造成浮点数下溢
• 由于 log(xy) = log(x) + log(y) • 求概率的和相比求概率的乘积更好一些 • 如果某个类别对应的非正则化的概率评分最高,则对数化之后仍然最大 • 此时问题可以转化为只是一些权重的累加
如何改善性能呢?
• 领域相关的特征和权重在实际问题中非常重要
• 有时需要削减的项: • 不完整的数字,化学方程式, … • 但是通常也没有效果 • 提升权重,在以下情形中将单词记为出现两次: • 标题中的单词 • 单词出现在段落中的第一句 • 包含主题中单词的句子
参考资料:
https://web.stanford.edu/class/cs124/lec/naivebayes.pdf
Cohen, William W., and Yoram Singer. "Learning to query the web." AAAI Workshop on Internet-Based Information Systems. 1996.
Jordan, A. "On discriminative vs. generative classifiers: A comparison of logistic regression and naive bayes." Advances in neural information processing systems 14 (2002): 841.
