
首先来看下标准的词表示方法。绝大多数基于规则和统计的NLP问题中,都将单词看作原子符号,比如,酒店,会议,步行。在词向量术语中,它是一个向量,其中一个元素为1,其余元素都为0,
[0 0 0 0 0 0 0 0 0 0 1 0 0 0 0]
这种方法被称为 “one-hot” 表示法,这种表示方法的缺陷显而易见,有多少个单词就需要多少维度,会浪费很多空间。另外,它还有一个问题,比如: motel [0 0 0 0 0 0 0 0 0 0 1 0 0 0 0] AND hotel [0 0 0 0 0 0 0 1 0 0 0 0 0 0 0] = 0
接下来看看基于分布相似性的表示方法。这种方法中,为了表示一个词,会借助它的邻居来表示。它是当代统计NLP中最成功的一种方法。

颜色比较重的表明是在描述银行业。上下文的范围不同,比如局部或更大的范围,可以得到相应的语义或句法聚类。
还有基于类别的和基于聚类的词表示方法。基于类别的模型会根据分布信息来学习相似单词构成的类别,主要包含以下几类:
• Brown clustering (Brown et al. 1992) • Exchange clustering (Martin et al. 1998, Clark 2003) 软聚类方法对每个聚类或主题中的单词学习相应的分布,这个分布可以用来表示单词属于每个聚类的可能性,代表性方法如下: • Latent Semantic Analysis (LSA/LSI), Random projections • Latent Dirichlet Analysis (LDA), HMM clustering
基于神经网络的嵌入可以得到单词的分散式表示,这种方法思想简单,将向量空间语义跟概率模型的预测结合起来即可得到 (Bengio et al. 2003, Collobert & Weston 2008, Turian et al. 2010)。这些方法,包括深度学习模型,都将一个单词表示成一个稠密的向量。比如下面一个例子:

一个可视化示例如下:

还有一种比较有意思的表示方法。这种方法可以用嵌入空间中进行向量减法来体现相似性。比如,在句法上,

动词和形容词也具有类似的形式。
在语义上有如下表示 (Semeval 2012 task 2):
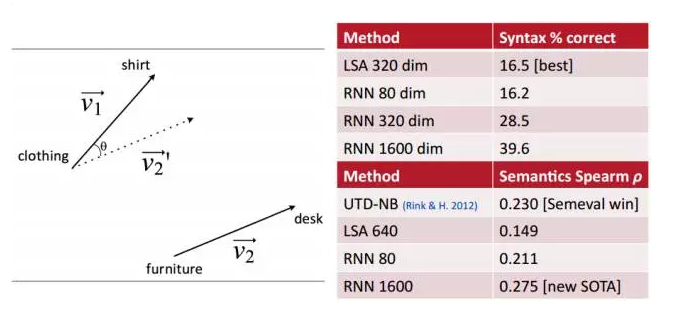
最后来看下基于神经网络的单词嵌入方法的优点:
跟 LSA 相比,基于神经网络的单词嵌入方法通过加入一个或多个任务的监督,更具有表达意义。比如判别式微调,无监督单词嵌入法中不能捕获情感信息,而基于神经网络的方法可以做到。
