目前,在线展示广告越来越流行。在线展示广告的目的是获取更多的潜在客户,吸引客户购买商品。在线展示广告的一个基本要求就是通过广告获取用户所需费用要小于用户购买商品所耗费用,进而使得通过广告吸引来的客户为企业带来利润。
在线展示广告中,比较流行的方式是通过手工精心设计更吸引人的广告,来招揽客户。然而,这种方法具有其局限性,并不是所有用户的兴趣点都一致,由于这种方式没有个性化特征,所带来的效果并没有特别显著。既然人工方式带来的效果不显著,那么可以考虑利用机器学习自动挖掘其中的潜在特性,进而带来更好的效果。
什么是机器学习呢?机器学习即为利用算法自动发现人们自己不能发现的潜在特征,或者隐藏的一些规律。机器学习已经在很多领域取得了显著的效果,如图像识别,语音识别,自然语言处理等。
如何在市场营销中利用机器学习呢?首先需要找出相关的特征。在机器学习中,一般用一行表示一个样本,每个列是一个相关的特征。针对不同的应用场景,需要找出不同的特征。本文以客户流失预测为例,客户流失预测相关的特征大致有距离上次登录时间,下单数,消费总金额,评论数等等。
其次要确定目标变量。每个样本都对应一个目标变量,比如在客户流失场景中,可以用0和1来标识某个用户是否流失。
确定了特征和目标变量,就要收集相关数据。为收集相关数据,需要找到相关的数据库以及相关的表格中相应的列或者其他存储方式的原始数据。在这个步骤中,可以得到一张集成的表格,其中包含了相关特征和目标变量。每一行对应一个样本。
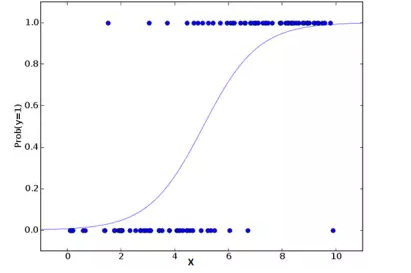
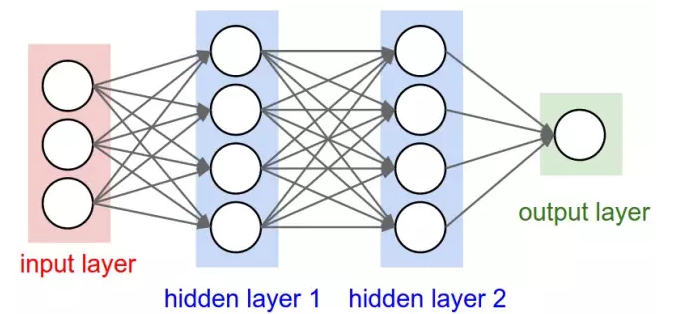
收集完数据,接下来要选择恰当的机器学习算法来解决客户流失预测问题。由于预测客户流失本质上是一个二分类问题,可以选择的算法主要有logistic regression(逻辑回归), decision tree(决策树),neural network(神经网络), support vector machine(支持向量机)等等。 现实问题中,通常数据比算法更重要,解决问题的算法有很多,只要收集的数据质量比较好,那么利用恰当的算法往往比复杂算法用于质量比较差的数据时取得的效果更好。简而言之,通常情况下数据比算法要重要。
logistic regresion 示意图
decision tree 示意图

neural network 示意图
support vector machine 示意图

选择了恰当的算法,就要对原始数据进行分割,分割成训练集和测试集。如此分割,是为了方便查看在训练集上训练所得模型是否在测试集中可以取得理想的效果。通常分割比例为6:4或者7:3。前者为训练集占比,后者为测试集占比。训练集用来训练算法,学习其中的参数,测试集用来查看或检验所选算法在测试集上的效果。
将原始数据分成训练集和测试集之后,就可以运行算法了。当前比较流行的机器学习算法都集成到了包里,用户可以利用R或者Python来运行相关算法。目前,数据科学(data science)领域比较流行的运行机器学习算法的两种语言就是R和Python。
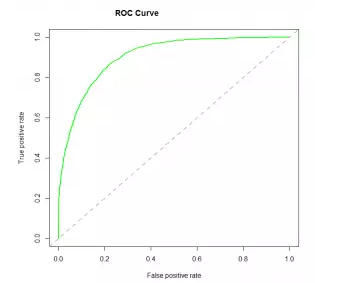
运行完算法,需要衡量算法效果。通常可以利用准确率,召回率,F1 score 以及AUC (Area under ROC)。准确率即为预测成流失的样本中真实流失样本占比,召回率即为原本即为流失样本且预测成流失样本的样本在真实流失样本中的占比。F1 score 是准确率以及召回率的调和平均。AUC是ROC(receiver operating characteristic)曲线下的面积,其中ROC是曲线,横坐标是FPR(FALSE positive rate),纵坐标是TPR(TRUE positive rate,也可以看做召回率)。
ROC 曲线示意图
通过机器学习算法也可以发现对客户流失造成较大影响的因素,进而可以采取相应的措施来挽留客户。挽留客户是营销领域中比较重要的一项任务,挽留了客户才可以使得客户为企业带来更大的价值。
