通过"自动数值"节点,您可以为连续(数值范围)结果自动创建和比较不同的模型,例如预测某项财产的应征税值。借助于单独节点,可以估计和比较一组候选模型,并生成一个模型子集以进一步分析。这类节点与自动分类器(预测目标变量为分类变量)节点工作方式相同。该节点将候选模型中的最佳模型合并到单个汇总(整体)模型块中。此方法将自动化操作的方便性与组合多个模型的优势融为一体,从而产生任何单一模型所不能带来的更为准确的预测。
本示例主要讲述一个负责调整和评估房地产税的机构。为使预测更为准确,他们将构建一个根据建筑类型、周边状况、占地面积以及其他已知因素预测属性值的模型。
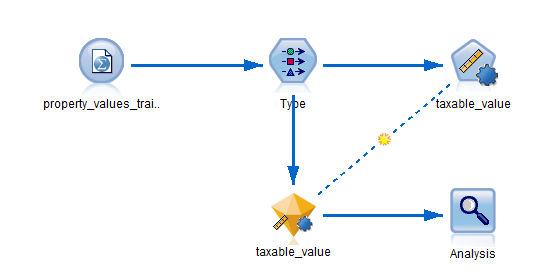
训练数据
数据文件包含一个名为 taxable_value 的字段,该字段就是要预测的 目标字段 或值。其他字段所包含的信息有周边情况、建筑类型以及内部体积,它们均可以用作预测变量。
字段名称 标签
property_id 属性标识
周边状况 城市内的区域
building_type 建筑物的类型
year_built 建造年代
volume_interior 内部体积
volume_other 车库和其他建筑所占的体积
lot_size 占地面积
taxable_value 应征税值
1.读入数据:
2. 添加类型节点,然后选择 taxable_value 作为目标字段(角色为目标)。所有其他字段的角色均应设置为输入,从而指示这些字段将用作预测变量。
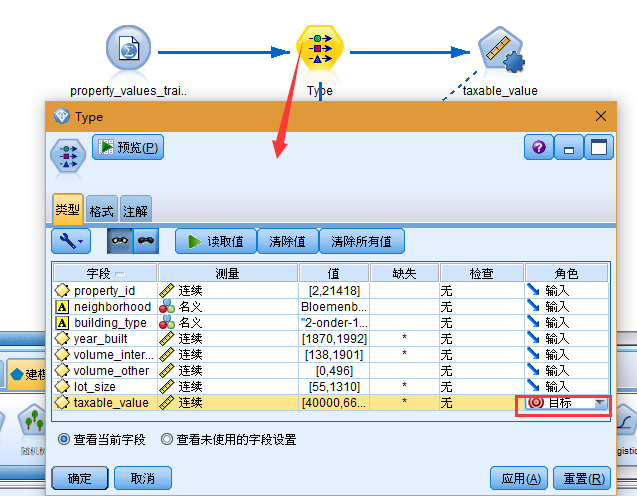
3. 附加自动数值节点,并选择相关性作为对模型排序的方法。
4. 将要使用的模型数设置为 3。这意味着在执行节点时将构建三个最佳模型。
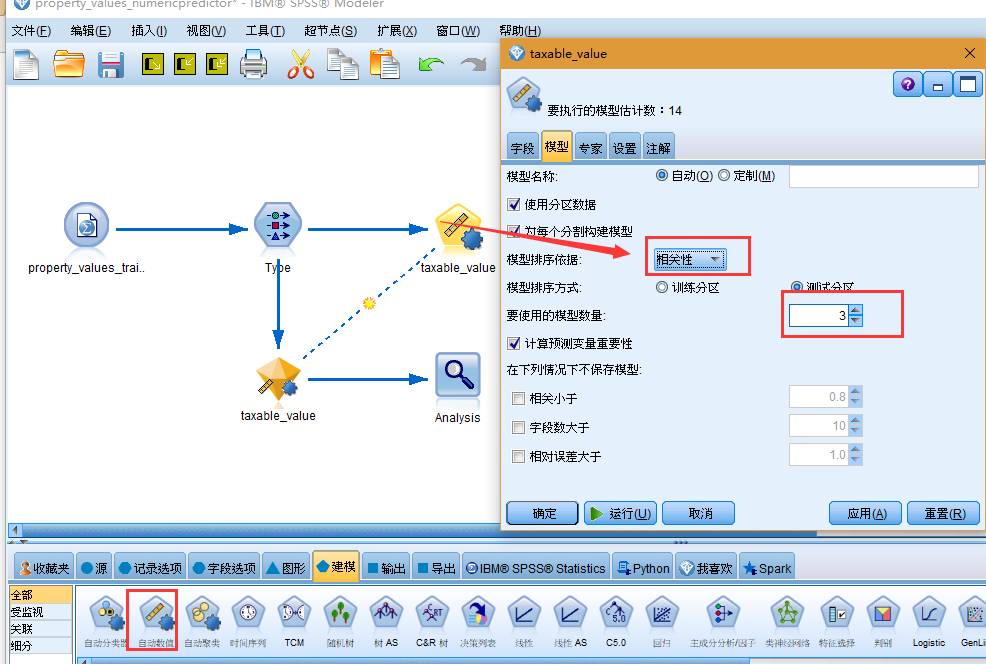
5. 在"专家"选项卡中,保留缺省设置;节点将为每个算法估算单个模型(共七个模型)。(可以修改这些设置,以对每个模型类型的多个变量进行比较。)
由于在"模型"选项卡上将要使用的模型数设置为 3,因此节点将计算七个算法的准确性,并构建包含三个最准确算法的单个模型块。
6. 在"设置"选项卡中,保留缺省设置。由于这是一个连续目标,因此会由各个模型的平均评分生成整体评分。
模型比较
1. 单击"运行"按钮。
将构建模型块,并将其放入画布和窗口右上角的"模型"选用板中。您可以浏览此模型块,或者以多种其他方式对其进行保存或部署。
打开模型块;它将列出在运行期间创建的每个模型的详细信息。(对于在大型数据集中估算数百个模型的实际情况,这可能会花费数小时的时间。)
如果需要进一步探索任何单独的模型,可在模型列中双击此模型块图标,以向下浏览至单独模型结果,您可以从中生成建模节点、模型块或评估图表。
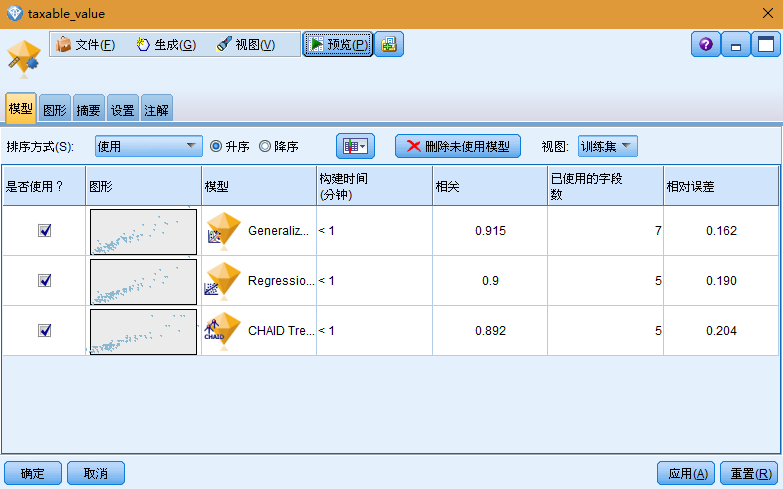
由于您在"自动数值"节点中选择了相关性度量,因此模型将根据此度量进行排序。出于排序目的,将使用相关性的绝对值,值越接近于 1 表示关系越强。在本度量中,广义线性模型的排序最佳,但是还有几个模型也近乎准确。除此之外,广义线性模型还具有最低的相对错误。通过单击列标题或从工具栏上的 排序方式 列表中选择所需的测量,您可以对不同的列进行排序。每个图形都显示了相对于模型预测值的观察值图,从而可以快速直观地表示模型之间的相关性。对一个好的模型来说,所有的点都应聚集在对角线附近,在本例中所有模型都是如此。在图形列中,可以双击缩略图生成标准大小的图形。
基于这些结果,您可以决定使用所有这三个最准确的模型。通过结合多个模型的预测,可以避免单个模型的局限性,从而使总体准确性更高。确保选中了所有三个模型。在模型块后面附加一个"分析"节点("输出"选用板)。右键单击分析节点,然后选择运行以运行流。
由整体模型生成的平均评分会添加到名为 $XR-taxable_value 且相关性为 0.922 的字段中,该相关性值高于三个单独模型中的这些相关性值。该整体节点还显示了较低的平均绝对误差,因此与任何单独模型相比,在应用到其他数据集时,执行效果可能会更好。
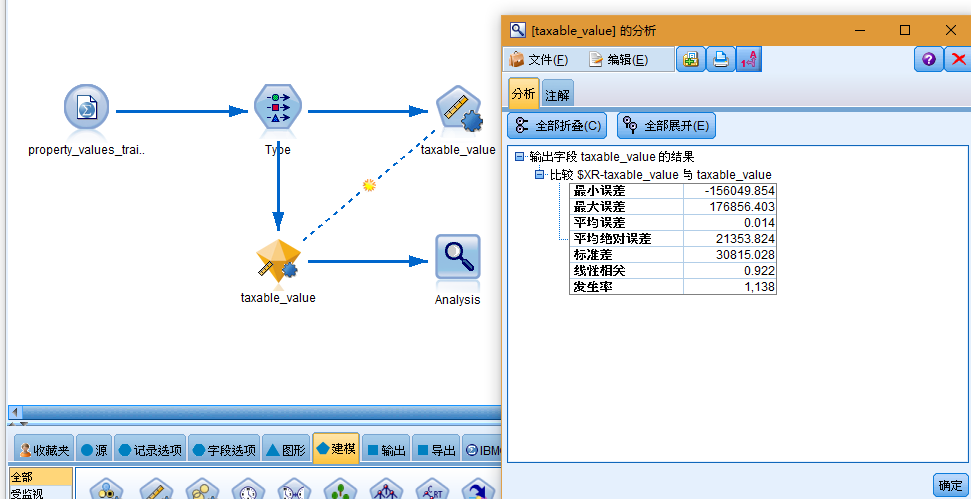
综上,您使用自动数值节点比较了多种不同的模型,然后选定三个最准确的模型并将它们添加到位于一个整体自动数值模型块内的流中。根据总体准确性,"广义线性"、"回归"和 CHAID 模型在训练数据方面表现最佳。 整体模型显示出优于两个单独模型的效果,并且在应用到其他数据集时,执行效果可能会更好。如果您的目标是尽可能多地自动执行这一过程,您可以通过此方法获得在大多数情况下都很稳健的模型,而无需深入挖掘任意一个模型的细节。
