通过CLEMENTINE的"自动分类器"节点,您可以为分类(例如某个指定客户是否可能拖欠贷款或者是否对特定的报价做出响应)或名义(集合)目标自动创建和比较多个不同的模型。在本例中,我们将搜索标志(是或否)结果。在一个相对简单的流中,节点生成一组候选模型并对它们进行排序,选择最有效的模型,然后将它们合并为一个汇总(整体)模型。此方法将自动化操作的方便性与组合多个模型的优势融为一体,从而产生任何单一模型所不能带来的更为准确的预测。
本示例基于某个公司,该公司希望通过为每个客户提供适合的报价以实现更高收益。
数据:
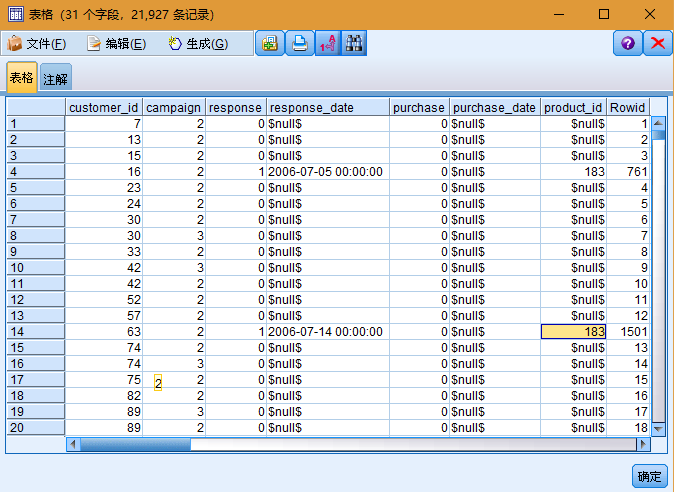
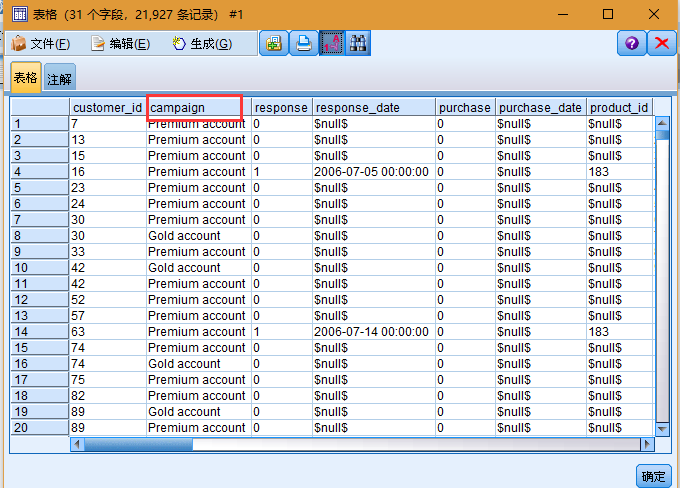
文件 pm_customer_train1.sav 的历史数据可跟踪过去的营销活动中为特定客户提供的报价,由 campaign 字段的值表示。Premium account 活动中的记录数最大。campaign 字段的值在数据中实际编码为整数(例如 2 = Premium account)。您可为这些值定义标签以用于给出更有意义的输出。
此文件还包含一个 响应 字段,该字段表明所提供的报价是否被接受(0 = 否 ,1 = 是 )。这将是您希望预测的 目标字段 或值。此外,还包括一些字段,这些字段包含有关每位客户的人口统计信息和财务信息。这些字段可用于构建或"训练"根据收入、年龄或每月交易次数等特征来预测个人或群体的响应率的模型。
1.读入数据
2. 添加类型节点,然后选择响应作为目标字段("角色"为目标)。将此字段的"测量"设置为标志。
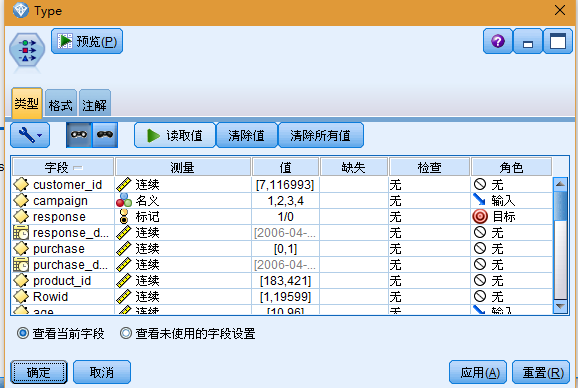
3. 对于下列字段,将角色设置为无:customer_id、campaign、response_date、purchase、purchase_date、product_id、Rowid 和 X_random。当您构建模型时,将忽略这些字段。
4. 单击类型节点的 读取值 按钮以确保值获得实例化。正如前述内容所示,我们的源数据包含有关四项不同活动的信息,每个活动针对不同类型的客户帐户。这些活动在数据中编码为整数,以方便记住每个整数所代表的帐户类型,让我们为每一个都定义标签。
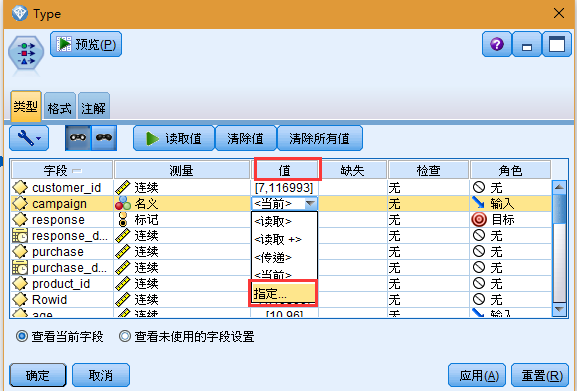
5. 在活动字段的行上,单击值列中的条目。
6. 从下拉列表选择指定。
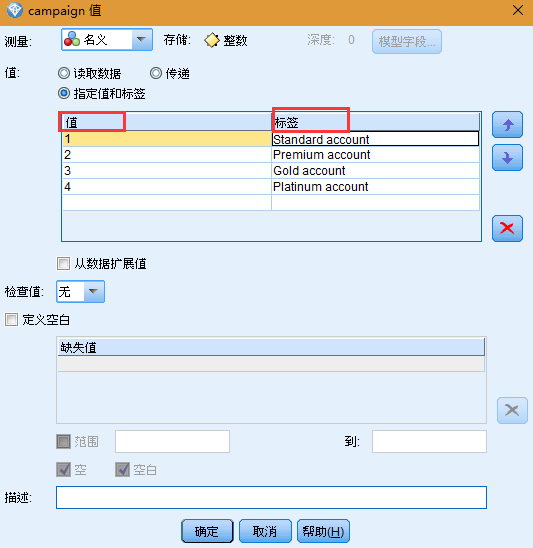
7. 在标签列中,键入活动字段四个值中每个值所显示的标签。单击确定。
8. 将表节点附加到类型节点。
9. 打开"表"节点,然后单击运行。
10. 在输出窗口上,单击显示字段和值标签工具栏按钮以显示标签。
11. 单击确定关闭输出窗口。
现在您可在输出窗口中显示标签而非整数了。
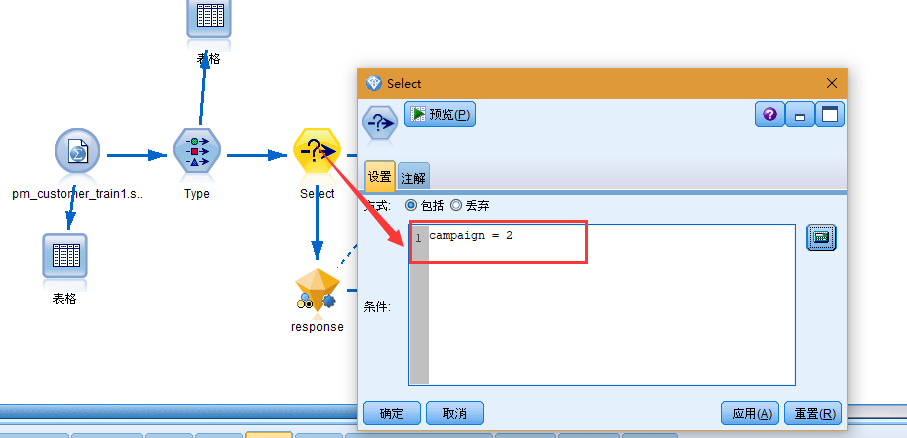
尽管数据包含有关四项不同活动的信息,但每一次的分析应侧重于其中一项活动。由于 Premium account 活动(在数据中编码为 campaign=2)中的记录数最大,因此可以使用选择节点实现仅在流中包含这些记录。
生成和比较模型
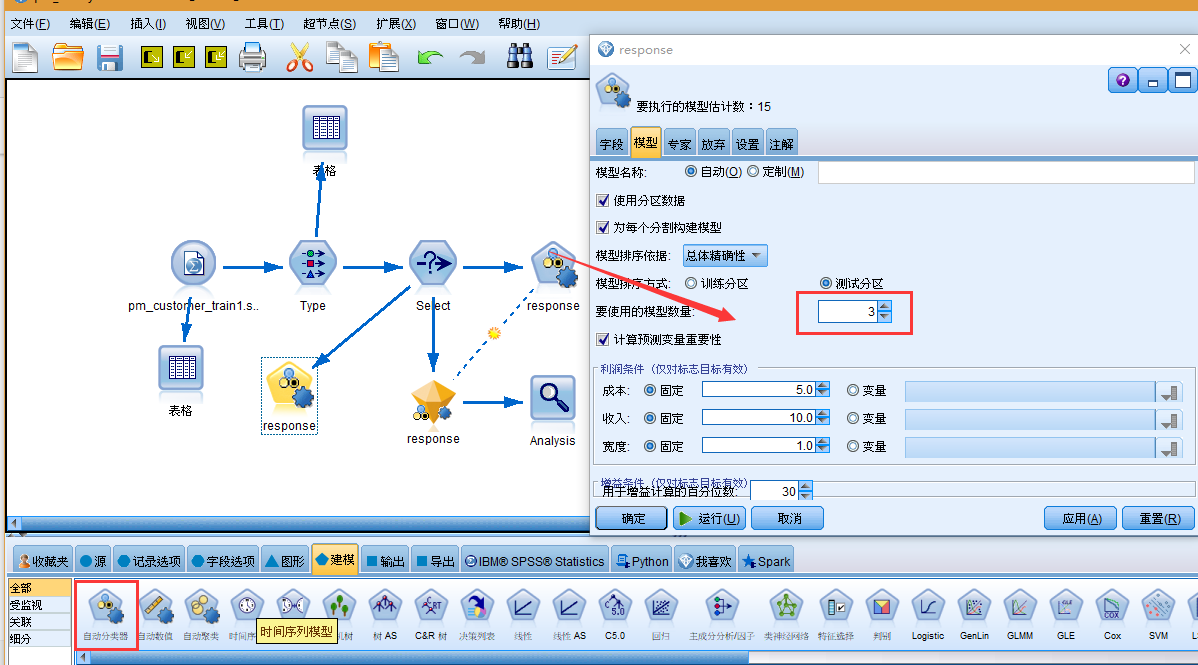
1. 附加一个自动分类器节点,然后选择总体准确性作为对模型进行排序的度量。
2. 将要使用的模型数设置为 3。这意味着在执行节点时将构建三个最佳模型。
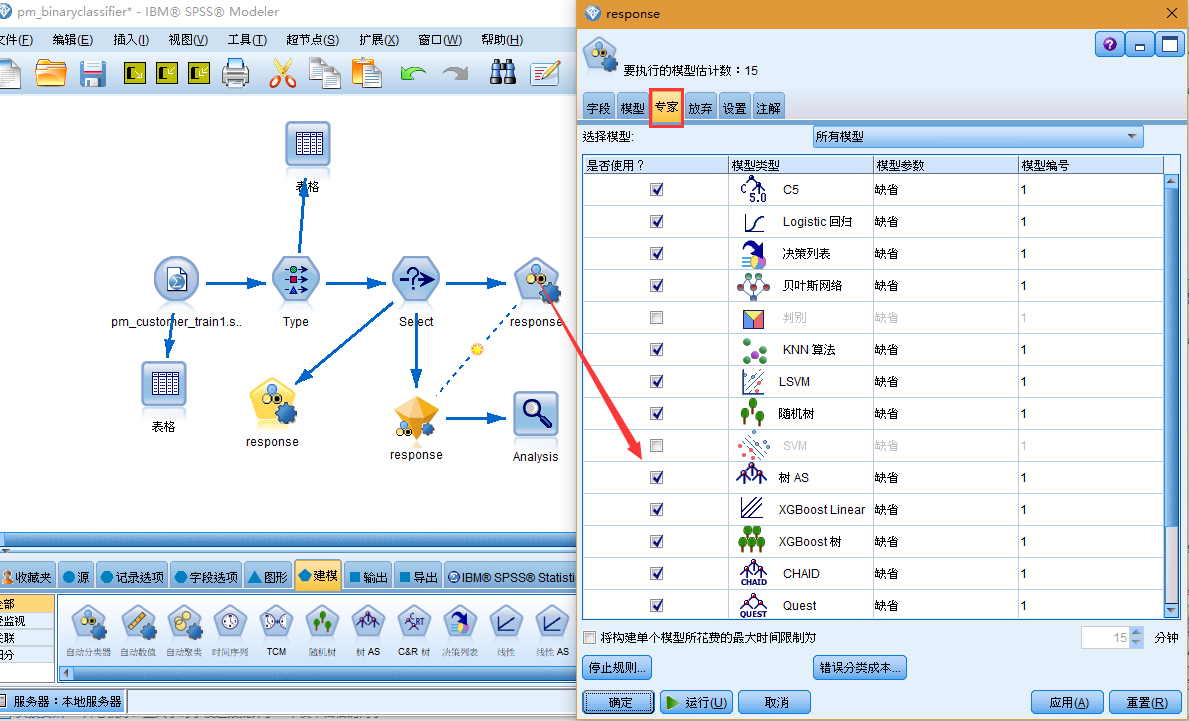
在"专家"选项卡上,可从最多 11 种不同模型算法中进行选择。
3. 取消选择判别和 SVM 模型类型。(这些模型需要花费更多时间来训练这些数据,因此取消选中它们将加快示例的执行速度。如果您不介意稍等一下,也可以保留它们的选中状态。)
由于在"模型"选项卡上将要使用的模型数设置为 3,因此节点将计算余下九个算法的准确性,并构建包含三个最准确算法的单个模型块。
4. 在"设置"选项卡上,对于整体方法,请选择置信度加权投票。此选项确定如何为每条记录生成一个汇总评分。使用简单投票方式时,若三个模型中有两个模型均预测 是,则 是 将以 2 比 1 的投票结果取胜。在使用置信度加权投票方式的情况下,将基于各预测的置信度值进行加权投票。因此,如果一个预测 否 的模型的置信度比两个预测 是 的模型合在一起的置信度还高,则 否 取胜。
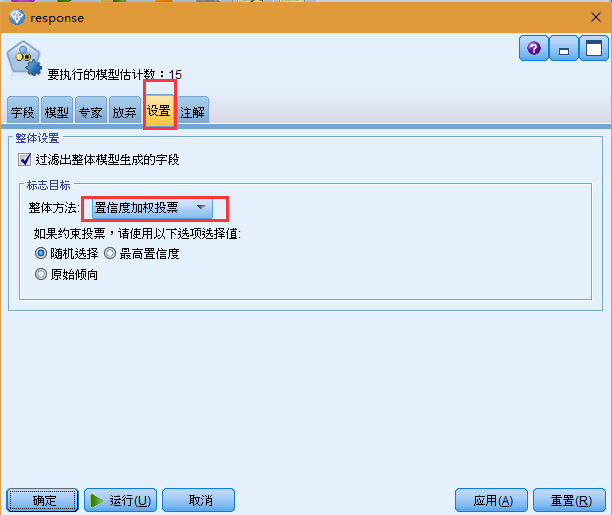
5. 单击运行。
几分钟后,将构建生成的模型块,并将其放入画布和窗口右上角的"模型"选用板中。您可以浏览此模型块,或者以多种其他方式对其进行保存或部署。
打开模型块;它将列出在运行期间创建的每个模型的详细信息。(对于可能会在大型数据集中创建数百个模型的实际情况,这可能会花费数小时的时间。)
如果需要进一步探索任何单独的模型,可在模型列中双击此模型块图标,以向下浏览至单独模型结果,您可以从中生成建模节点、模型块或评估图表。在图形列中,可以双击缩略图生成标准大小的图形。
自动分类器结果:
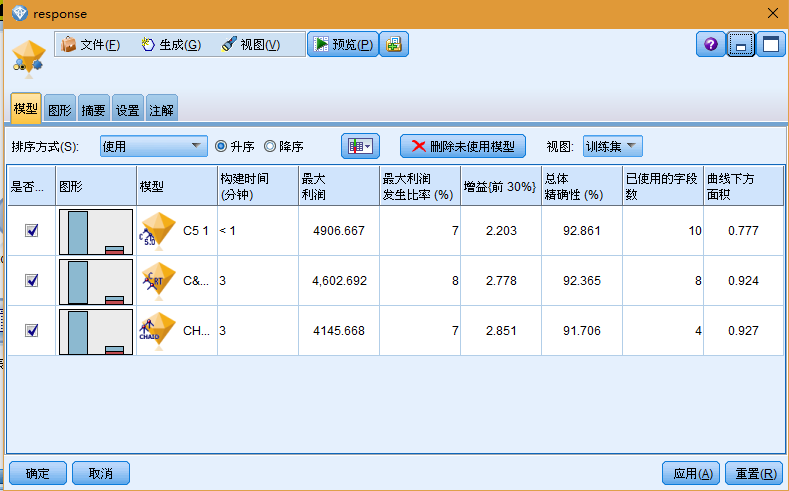
缺省情况下,由于在"自动分类器"节点的"模型"选项卡中选择了总体准确性度量,因此模型将根据此度量进行排序。根据这一度量,C51 模型的精确性最高,但 C&R 树和 CHAID 模型的精确性与之相差不大。您可以通过单击其他列的标题对该列进行排序,或者也可以从工具栏的 排序方式 下拉列表中选择所需的度量。基于这些结果,您可以决定使用所有这三个最准确的模型。通过结合多个模型的预测,可以避免单个模型的局限性,从而使总体准确性更高。选择 C5.1, C&R 树和 CHAID 模型。
在模型块后面附加一个"分析"节点("输出"选用板)。右键单击分析节点,然后选择运行以运行流。由整体模型生成的汇总评分将显示在名为 $XF-response 的字段中。根据训练数据进行度量时,预测值与实际响应(如原始响应字段中的记录所示)相匹配的总体准确性为 92.82%。尽管该准确性低于此个案的三个模型中的最高准确性(C51 为 92.86%),但它们之间的差异非常小,可以忽略不计。一般来说,在应用到除训练数据之外的数据集中时,整体模型通常更可能具有良好效果。
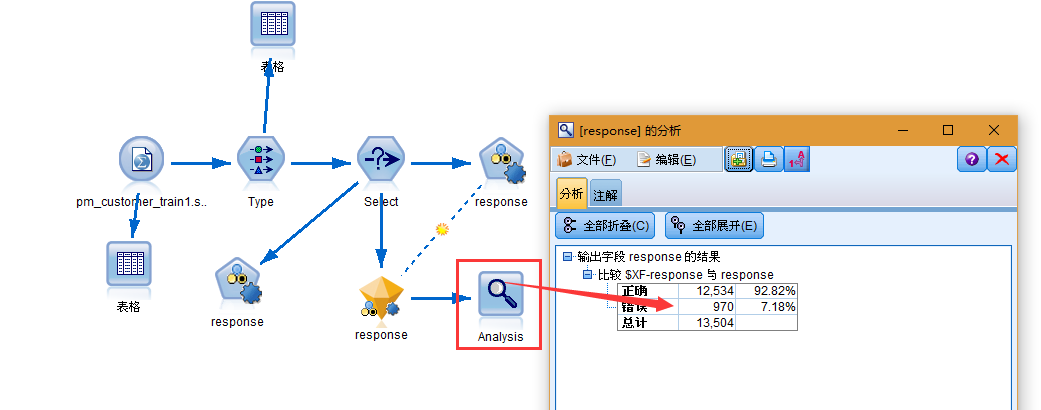
综上所述,使用"字段分类器"节点对多种不同的模型进行了比较,然后使用三个最准确的模型并将它们添加到整体"自动分类器"模型块内的流中。基于总体准确性,"C5.1"、"C&R 树"和 CHAID 模型对于训练数据效果最佳。整体模型与最好的单个模型相比效果相差不大,而且在应用到其他数据集时可以起到更好的效果。如果您
的目标是尽可能多地自动执行这一过程,您可以通过此方法获得在大多数情况下都很稳健的模型,而无需深入挖掘任意一个模型的细节。
