一、前言
劳动力异质性导致每一个劳动者都可能成为一独特的研究个体,如何从劳动力的异质性差异中研究出共性的规律是当前学术界研究的难点。此处我们要研究的是:劳动力异质性对工作满意的的分析。
二、数据来源
数据来自中国家庭动态跟踪调查 CFPS数据;我们选用的是2016年成人问卷数据,共1022个变量,33296条记录。经过筛选及删除变量值缺失的样本数据,最终使用样本数是5249个。

三、建立指标体系
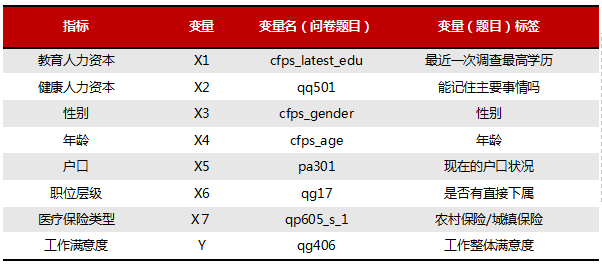
指标选取依据:一是业务,通过相关文献;二是数据,问卷中变量的获取情况及质量。最终选取指标如下:
四、决策树实现-python
训练决策树-评估-剪枝
#加载所需库
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.tree import DecisionTreeClassifier
# 导入数据
# csv文件是通过pandas模块中的read_csv函数进行读取。
# sep:指定分隔符,encoding:指定文件编码等,对于文本文件含有中文的,其文件编码通常为uft-8。
data_cart = pd.read_csv('D:/mydata/tree.csv',sep = ',',encoding = 'utf-8')
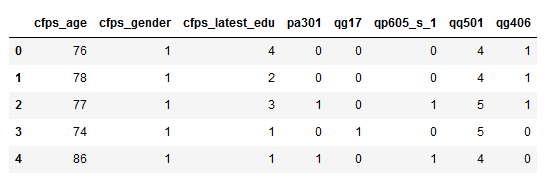
#查看数据
print(data_cart.shape)
data_cart.columns

data_cart.head()
# 拆分训练集与测试集
array = data_cart.values
X =array[:,0:7]
Y = array[:,7]
test_size = 0.30
seed = 4
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=test_size, random_state=seed)
# 一般形式:X_train,X_test, y_train, y_test =cross_validation.train_test_split(train_data,train_target,test_size= , random_state= )
#X_train:所要划分的样本特征集
#train_target:所要划分的样本结果
#test_size:样本占比,如果是整数的话就是样本的数量
#random_state:是随机数的种子。在需要重复试验的时候,保证得到一组一样的随机数。
# 采用sklearn模块构建cart决策树
cart_tree = DecisionTreeClassifier()
cart_tree

# class_weight:分类的权重,(None,权重都一样,balance分类的权重是样本中各分类出现频率的反比)
# criterion:算法类型,(默认为"gini"),"entropy"代表信息增益。"mse"表示均方误差(回归树)
# splitter:切分原则,可选(默认为"best"),"best",最优切分,"random"随机切分。
# max_features:在进行分类时需要考虑的最大特征数(默认为"None")。
# max_depth:树的最大深度,(默认为"None")
# max_leaf_nodes:叶节点的最大数量。
# min_samples_leaf:叶节点包含的最小样本数。
# min_samples_split:非叶节点包含的最小样本数。
# presort:是否要提前排序数据从而加速寻找最优分割点的过程。(True会减慢训练过程)
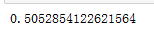
# 模型训练、预测、评估
cart_tree.fit(X_train, Y_train)
data_cart_pre = cart_tree.predict(X_test)
sum(data_cart_pre == Y_test)/float(len(Y_test))
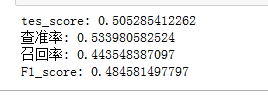
#评估具体指标
from sklearn import metrics
print("tes_score:", cart_tree.score(X_test, Y_test))
y_pred = cart_tree.predict(X_test)
print("查准率:",metrics.precision_score(Y_test, data_cart_pre))
print("召回率:",metrics.recall_score(Y_test, data_cart_pre))
print("F1_score:",metrics.f1_score(Y_test, data_cart_pre))
#绘制决策树图(需要安装graphviz工具和及配置)—https://graphviz.gitlab.io/about/
# 在cmd界面输入conda install python-graphviz来安装graphviz。
import graphviz
import sklearn.tree as tree
dot_data = tree.export_graphviz(cart_tree, out_file=None)
graph = graphviz.Source(dot_data)
graph.render("cart_tree_1")
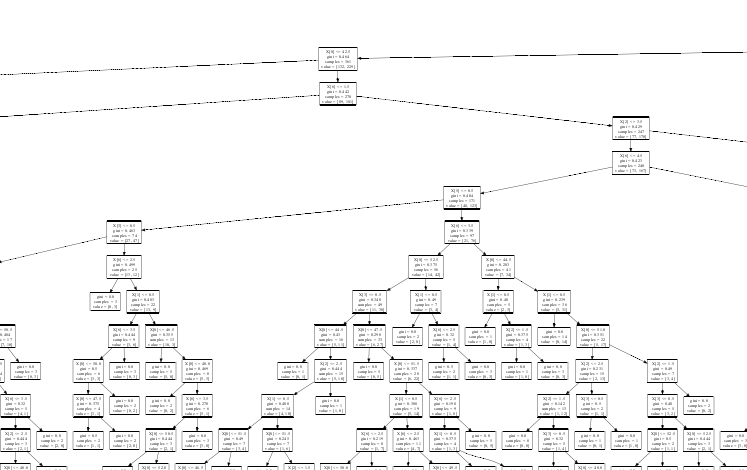
部分截图
#剪枝
#设置待选的参数
#导入所需库
from sklearn.grid_search import GridSearchCV
from sklearn.model_selection import StratifiedKFold
decision_tree_classifier = DecisionTreeClassifier()
parameter_grid = {'max_depth':[1,2,3,4,5],
'max_features':[1,2,3]}
#将不同参数带入
gridsearch = GridSearchCV(decision_tree_classifier,
param_grid = parameter_grid,
cv = 10)
gridsearch.fit(X_train,Y_train)
#得分最高的参数值,并构建最佳的决策树
best_param = gridsearch.best_params_
best_decision_tree_classifier = DecisionTreeClassifier(max_depth=best_param['max_depth'],
max_features=best_param['max_features'])
#best_decision_tree_classifier
best_decision_tree_classifier.fit(X_train,Y_train)

#评估剪枝后的决策树
best_decision_tree_classifier_pre = best_decision_tree_classifier.predict(X_test)
sum(best_decision_tree_classifier_pre == Y_test)/float(len(Y_test))
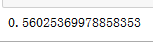
发现准确率提高。可以应用上文的绘制决策树方法,画出剪枝后的决策树。
#输出决策树规则
with open("cart0717.dot", 'w') as f:
f = tree.export_graphviz(best_decision_tree_classifier, out_file=f)
业务应用略。
数据下载地址:https://pan.baidu.com/s/1BVNMOqZ_QibPUqlqe8M5LQ
更多信息可关注课程-左手Python右手R,多算法对比,经典数据挖掘机器学习实战!

