
作者:村长,数据科学、指弹吉他及录音工程爱好者,浙大金融学博士在读,在data.table包和MongoDB的使用上有较多经验。
写在前面
本期依然由村长为大家供稿,只为填上一期最后挖的坑,话不多说进入正题。
问题提出
在上一期中,还记得我们留下的那个彩蛋吗?我们在对多列标准进行筛选时,在之前我们还进行了一步非常重要的提取,也就是将每一列观察值提取出某一特定的字段,而后生成一系列变量,这些变量的观测值只可能存在三种情况:醛固酮、继发性醛固酮或者NA。
经过这样的处理我们才能进行上一期公众号所讲述的下一步:以多列标准进行筛选的操作。
我们先将这段代码放上来:
clinic <- clinic[, str_c(colnames(clinic)[2:23], "_xtrct") := lapply(.SD[, 2:23], str_match, "继发性醛固酮|醛固酮")]
再来看看运行结果:
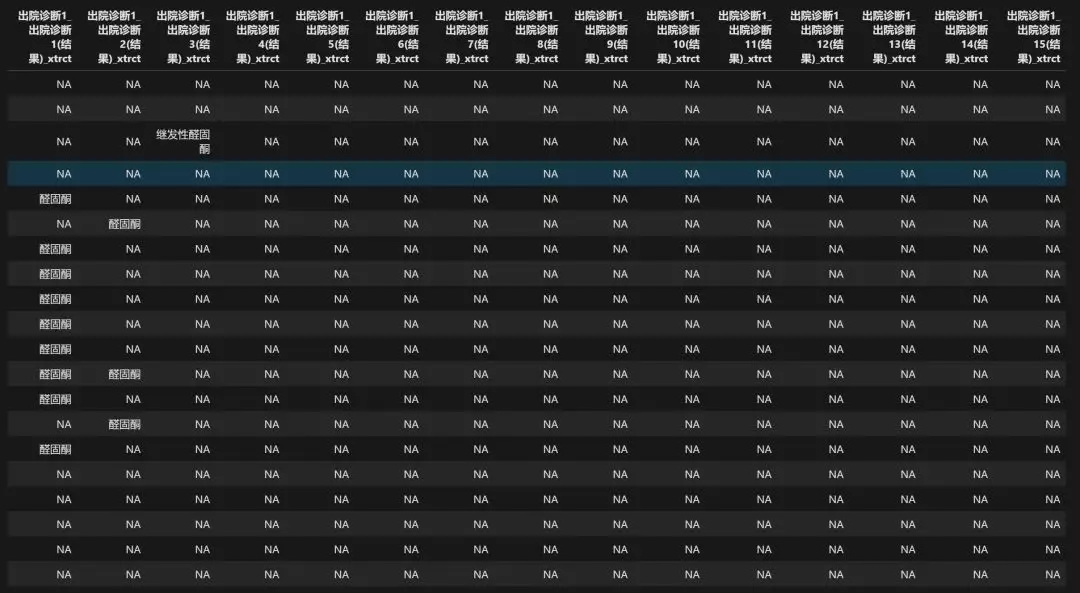
上述结果可以看出,我们重新生成了很多被处理过的变量,都带有后缀_xtrct,下面让村长对这一行代码进行详细解析。
:=
右边
关于 ':= lapply' 的用法,在这里小编不再赘述,如果大家对此不是很熟悉可以看这一期公众号:用data.table语句批量处理变量。
在这里通过链接中的推送的lapply使用原理,再加上stringr包中str_match这个函数的使用,截取出诊断结果中出现过的继发性醛固酮或者醛固酮,没有出现过的自动记为NA。代码如下:
lapply(.SD[, 2:23], str_match, "继发性醛固酮|醛固酮")
:=
左边
我们可以再回顾一下,上文链接中用data.table语句批量处理变量的推送中所提到的 ‘:=’ 左边格式的问题:
':=' 左边的格式应该是一个向量,一个带有需要被处理变量的字符格式的向量,这一点从colnames这个函数的使用可以得知。
那么对于一个字符格式向量的处理,最好的选择就是stringr这个包,在这里我们为需要提取一部分字段的变量,运用str_c这个函数,对每一个变量名加入了后缀_xtrct,从而生成一系列新的变量名,也即是我们上文中生成的那个数据集。
str_c(colnames(clinic)[2:23], "_xtrct")
最后我们把 ':=' 左右两边的代码组合在一起,放入data.table语句的j中就是我们在一开始所讲述的代码。
转载自公众号:大猫的R语言课堂

往期精彩:

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
