R 中的每个函数都是一个闭包(除了原生函数)。闭包是一个具有与之相关环境的函数。例如,R 包中的函数可以访问包的名称空间,或在面向对象时类中的方法可以访问整个类。但是通常这个术语是在从其他函数中返回函数时使用的(每当你试图对闭包进行子集化时,除了 R 的错误消息外)。如果你对此还不了解,你可以阅读这篇文章或《Advanced R》的相关章节。
我的例子中,我使用闭包来为给定的 p 值重新定义平方根的不动点函数。我认为只有通过以下实施才能强调给定 p 值:
fpsqrt <- function(p)
{
function(x) p / x
}
这实际上使算法的调用更加简洁:
fp(averageDamp(fpsqrt(2)), 2, converged)
## [1] 1.414214
缓存模式
在各种情况下,我都想缓存一些结果而不是重新计算它们。这是因为性能方面的考虑,因为无论使用哪个库,计算矩阵逆的时间关于样本大小都不是线性的。如果你有 10000 个观察值,并且要计算在蒙特卡罗模拟中得到的协方差矩阵(10000x10000)的逆,你有得好等了。为了说明这一点,我设想计算一个线性估计量。尽管估计量可以通过解析方法来得到,但我使用了不动点算法。这种情况下,不动点函数中我使用 Newton-Raphson 算法,定义如下:
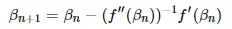
其中,
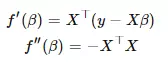
是正态分布情况下似然函数在 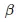 点的一阶和二阶导数。如果你对此没有什么概念,就把注意力完全放在这个模式上。在 R 中,我已经使用闭包应用了接口模式,请考虑以下实现:
点的一阶和二阶导数。如果你对此没有什么概念,就把注意力完全放在这个模式上。在 R 中,我已经使用闭包应用了接口模式,请考虑以下实现:
nr <- function(X,
y)
{
function(beta) beta - solve(-crossprod(X)) %*% crossprod(X, y - X %*% beta)
}
# Some data to test the function:
set.seed(1)
X <- cbind(1, 1:10)
y <- X %*% c(1, 2) + rnorm(10)
# Average damping in this case will make the convergence a bit slower:
fp(printValue(averageDamp(nr(X, y))), c(1, 2), converged)
## 1 2
## 0.9155882 2.027366
## 0.8733823 2.041049
## 0.8522794 2.047891
## 0.8417279 2.051311
## 0.8364522 2.053022
## 0.8338143 2.053877
## 0.8324954 2.054304
## [,1]
## [1,] 0.8318359
## [2,] 2.0545183
# And to have a comparison:
stats::lm.fit(X, y)$coefficients
## x1 x2
## 0.8311764 2.0547321
结果看起来很好。我们应该选择一个不同的容忍度,以便更接近 R 的实现,目前看来这个容忍度选择得非常宽松,但这不是现在的重点。我现在想要做的是使 nr 的返回函数依赖于预先计算的值,以避免它们在每次迭代中重新计算。在这个例子中,我将它与局部函数的定义结合起来:
nr <- function(X, y)
{
# f1 relies on values in its scope:
f1 <- function(beta) Xy - XX %*% beta
Xy <- crossprod(X, y)
XX <- crossprod(X)
f2inv <- solve(-XX)
function(beta) beta - f2inv %*% f1(beta)
}
fp(averageDamp(nr(X, y)), c(1, 2), converged)
## [,1]
## [1,] 0.8318359
## [2,] 2.0545183
一些评论:
在上面的例子中,像 f1 这样的局部函数定义是唯一依赖自由变量的地方。即 f1 依赖于封闭环境中定义的值 Xy 和 XX;这是我在上层函数中不惜一切代价要避免的。
我喜欢这种表示方法,因为我将不动点函数的逻辑保留在 nr;在给定数据的情况下,该函数知道如何计算下一次迭代的所有事。一种不同的方法是定义 nr,使其将 XX、Xy 和 f2inv 作为参数,这意味着我的代码的其他部分必须知道 nr 中的实现,并且我必须查看不同的地方以了解下一次迭代是如何进行的计算。
计数器模式
到目前为止,不动点框架不允许限制迭代次数。这当然是你总想要控制的东西。这次我使用闭包来模拟可变状态。考虑计数器的两种实现:
# Option 1:
counterConst <- function()
{
# like a constructor function
count <- 0
function()
{
count <<- count + 1
count
}
}
counter <- counterConst()
counter()
## [1] 1
counter()
## [1] 2
# Option 2:
counter <- local({
count <- 0
function()
{
count <<- count + 1
count
}
})
counter()
## [1] 1
counter()
## [1] 2
我还记得闭包很难理解,因为在上面的例子中,当 R 中几乎所有东西都是不可变的时候,它们可以用来模拟可变状态。为从 Hadley (R 领域的知名专家)的一个例子中明白这一点,我可能用头撞了几个小时墙。
为了在不动点框架中实现最大迭代次数,我结合了包装器模式和计数器模式来修改收敛准则,以便算法在给定次数的迭代后终止:
addMaxIter <- function(converged,
maxIter)
{
count <- 0
function(...)
{
count <<- count + 1
if (count >= maxIter) TRUE
else converged(...)
}
}
这使我们能够探索最初示例中发生的错误:
fp(printValue(fpsqrt(2)), 2, addMaxIter(converged, 4))
## 2
## 1
## 2
## 1
## [1] 2
现在我们可以看到算法的初始版本在 1 到 2 之间振荡。您可能会说,在这种情况下,你还可以将迭代的次数看作算法的逻辑(作为 fp 的责任)。在这种情况下,我会争辩说,代码不再反映之前介绍的算法公式。但是让我们来比较一下不同的实现:
fpImp <- function(f,
x,
convCrit,
maxIter = 100)
{
converged <- function()
{
convCrit(x, value) | count >= maxIter
}
count <- 0
value <- NULL
repeat {
count <- count + 1
value <- f(x)
if (converged()) break
else
{
x <- value
next
}
}
list(result = value, iter = count)
}
fpImp(averageDamp(fpsqrt(2)), 2, converged)
## $result
## [1] 1.414214
##
## $iter
## [1] 4
现在让我们为 fp 的返回值添加迭代次数:
addIter <- function(fun)
{
count <- 0
function(x)
{
count <<- count + 1
value <- fun(x)
attr(value, "count") <- count
value
}
}
fp(addIter(averageDamp(fpsqrt(2))), 2, converged)
## [1] 1.414214
## attr(,"count")
## [1] 4
也许这个实现应该有一个自己的名字,但是你仍然可以看到包装器和计数器模式,它和 averageDamp 函数类似。与 fpImp 相比,围绕最大迭代次数的逻辑已经从算法的具体实现中分离出来。特别是如果我考虑添加更多功能,命令式的实现不可避免地必须应付越来越多的事情。相反,我可以在我的不动点框架中插入新功能。所以我认为对扩展开放对修改封闭,这不仅仅是一件好事,如果你喜欢面向对象的话。
计数器模式当然更一般化。它仅仅反映了模拟可变状态的一种策略。只有极少数情况下,我才真的需要这样做,计数是一个重复出现的主题。
往期回顾
时间序列分析工具箱——timetk
时间序列分析工具箱——tidyquant
时间序列分析工具箱——sweep
基于 Keras 用深度学习预测时间序列
基于 Keras 用 LSTM 网络做时间序列预测
时间序列深度学习:状态 LSTM 模型预测太阳黑子(一)
时间序列深度学习:状态 LSTM 模型预测太阳黑子(二)
时间序列深度学习:seq2seq 模型预测太阳黑子

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法
