作者简介Introduction
傅兴:R语言中文社区专栏作者
个人公众号:Rapp
在学习英语的过程中,相信很多人都有和我一样的感受:虽然花了很多时间和金钱,但是总觉得收效甚微,ROI(Return on Investment)很低。
我觉得学好英语和学好R语言有很多共同之处:
1. 要找到适合自己当前水平的学习资料(过于简单是浪费时间,难度过大容易丧失信心)
2. 广泛涉猎各种领域,用英语/R来解决工作和生活中的实际问题
3. 坚持不懈地努力
根据以上几点,我在挑选英语学习资料的时候,设置了3个标准:
1. 难度适中(客观地看待自己的英语水平)
2. 题材广泛,趣味性强(开阔眼界,积累与老外聊(ba)天(gua)时的谈资)
3. 短小精炼(可以利用5-10分钟的时间碎片来学习,容易坚持下去)
最终,我选择的是来自 BBC Learning English 的 6-Minite English:
http://www.bbc.co.uk/learningenglish/english/features/6-minute-english
这个栏目每周都有更新,而且每一期的文档(pdf)和语音(mp3)文件都可以免费下载。我们今天的目标就是用R来自动获取从2014年到2017年的所有pdf和mp3文件。
在动手写爬虫之前,我们需要浏览页面,确定需要获取的内容,并制订爬取策略。
6-Minute English的主页上有2014到2017年每一期(episode)的链接:

点击图片下方绿色的标题可以进入这一期的页面:
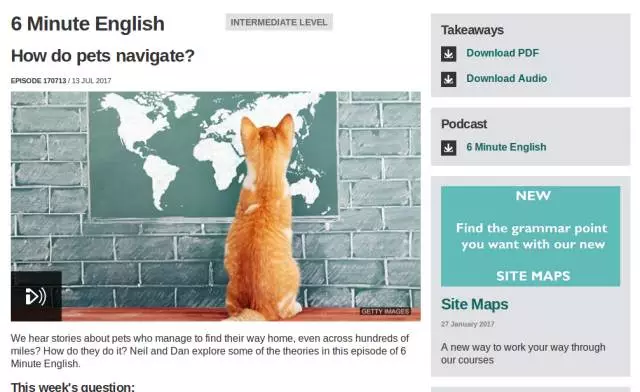
我们需要获取的目标链接就是页面右上方的 Download PDF/Audio
我们的爬取策略如下:
1. 下载并解析6-Minute English的主页,找出所有episode的链接和时间信息
2. 根据用户指定的起止日期,筛选出部分episode
3. 依次下载并解析每个episode的页面,找到pdf和mp3文件的链接
4. 下载pdf和mp3文件(首先判断pdf和mp3文件是否已经下载,避免重复下载)
具体代码和注释如下:
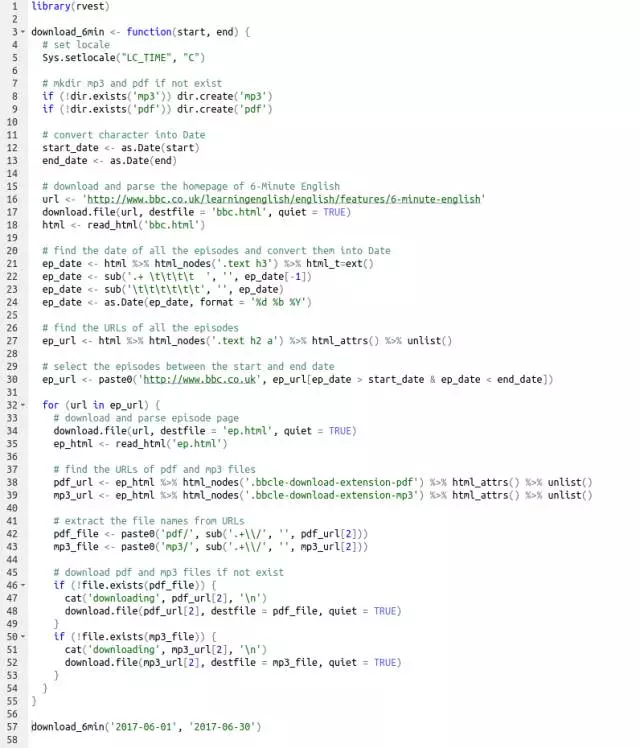
程序的输出:

提醒大家注意的是,在比较日期大小的时候一定要从字符型(character)转化成日期型(Date)。
今天的R爬虫就介绍到这里,大家学完了R爬虫,可别忘记学英语哦。如果不付诸行动,再好的学习资料也无济于事!
公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门
回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法

