
作者简介
糖甜甜甜,R语言中文社区专栏作者
公众号:经管人学数据分析
01 前言
前段时间向往的生活第二季中,托尼何老师给山争大叔洗头那一幕,着实给节目赚足了笑点。


而最近徐峥凭借《我不是药神》在电影院也收了不少观众眼泪,在这部电影里面他颠覆了当初囧系IP电影和心花路放的搞笑印象。对于现实主义的题材作品,电影本身的成功不仅在题材的选取上,更是因为监制宁浩徐峥、导演文牧野和其他主演的一起合作。《港囧》发布会,山争哥另辟蹊径,在发布会上化身“徐布斯”用大数据分析《港囧》,把观众笑声次数换算成票房收入。所以在徐峥的独特眼光中,什么样的题材、导演、演员才是他的青睐?本文用python爬取数据、并用R语言进行数据可视化处理来了解这位才子。
02 数据爬取
考虑到只有几百条数据,就简单的写了爬虫脚本,得到徐峥合作过的演员、合作次数、演员被收藏数、合作的作品名、作品导演、作品类型、作品评分。python代码如下:
1#-*- coding: utf-8 -*-
2from bs4 import BeautifulSoup
3import requests
4import pandas
5import time
6newarry = []
7user_agent = '*******'
8headers = {'User_Agent': user_agent}
9for i in range(15):
10 gradeUrl = 'https://movie.douban.com/celebrity/1274297/partners?start='+str(i*10)
11 res = requests.get(gradeUrl, headers)
12 soup = BeautifulSoup(res.content, 'html.parser').find(class_='article')
13 for item in soup.find_all(class_='partners item'):
14 partner = item.select('a')[1].text
15 times = item.select('li')[1].text
16 collect_num = item.select('li')[2].text
17 url_list = item.select('li')[1]
18 for url in url_list.find_all('a'):
19 each_page = requests.get(url.get('href'), headers)
20 sub_res = BeautifulSoup(each_page.content, 'html.parser')
21 info = sub_res.find(id='wrapper')
22 movie_name = info.select('span[property="v:itemreviewed"]')[0].text
23 print(movie_name)
24 director = info.find(class_='attrs').select('a')[0].text
25 types = ' '.join([style.text for style in info.select('span[property="v:genre"]')])
26 if info.find(class_='ll rating_num') is None:
27 rate = 0
28 else:
29 rate = info.find(class_='ll rating_num').text
30 newarry.append({
31 'partner': partner.split(" ")[0],
32 'time': times[5],
33 'collect_num': collect_num,
34 'movie_name': movie_name,
35 'director': director,
36 'types': types,
37 'rating': rate
38 })
39 time.sleep(2)
40 print(newarry)
41
42new_df = pandas.DataFrame(newarry, columns=['partner', 'time', 'collect_num', 'movie_name', 'director', 'types', 'rating'])
43new_df.to_excel('D:partner.xlsx')
44print(new_df)
03 数据分析
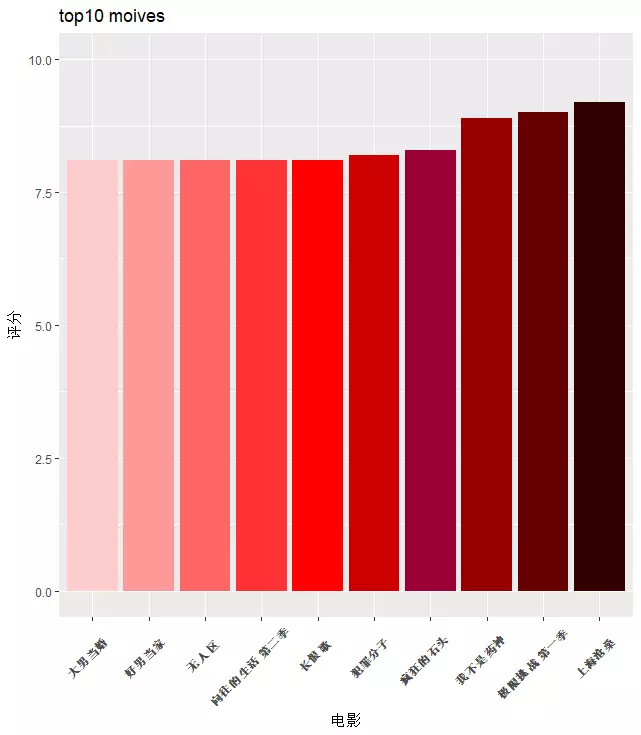
首先来看看徐峥出演的电影中,评分排前10的电影名,《我不是药神》是徐峥目前评分最高的电影,这成绩完全可以算国产片里的现象级了。还有极限挑战和向往的生活,徐峥作为临时嘉宾的那期节目也得到了不错的反响。
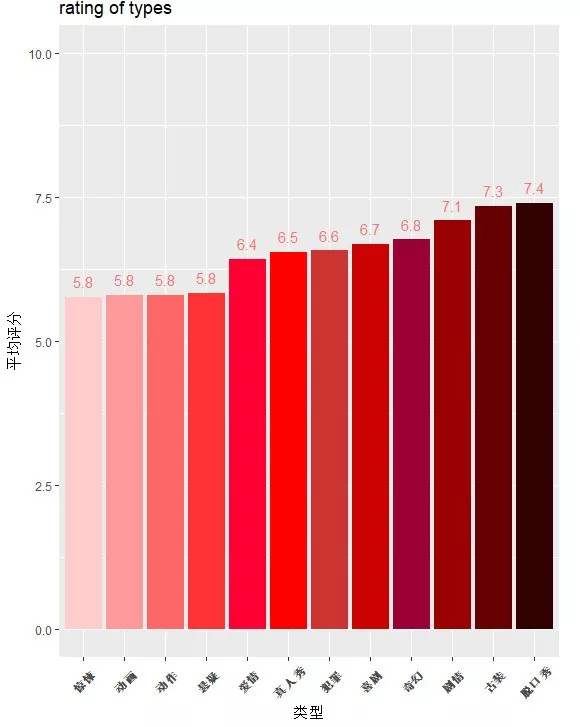
既然徐峥让观众又是悲伤涌起、又是捧腹大笑,那么看看他出演的作品中不同类型的评分情况,果然还是喜剧排名比较靠前,徐峥出演惊悚悬疑类的电影排名靠后,看来搞笑大叔的深刻印象不能让大家接受他出演惊悚片。徐峥去的真人秀和脱口秀节目也在当期取得不错的收视率和口碑。
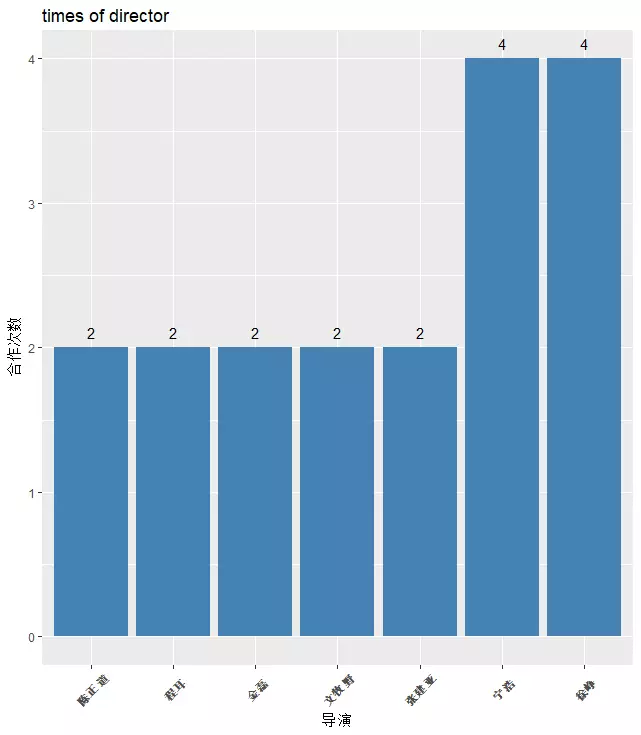
接下来看看徐峥和哪些导演合作比较紧密?徐峥出演自己自导的电影有4次,山争大哥完全没放过自己当主演的机会,接下来和宁浩导演合作4次,《疯狂的石头》《无人区》《心花路放》《疯狂的赛车》这四部都是不错的电影,除开合作伙伴的关系,这应该也是徐峥选择出演电影的原因。《我不是药神》也是宁浩监制、文牧野导演。
再来看看合作导演的作品评分情况,图a是评分排名前15的导演名字,图b是评分排名后15的导演名字,徐峥在2002年黄蜀芹导演的《上海沧桑》中并不是主演,排名第二的任静是《极限挑战》的导演,徐峥参加过的当期节目取得了9.0的豆瓣评分,看来他真的很适合参加真人秀。
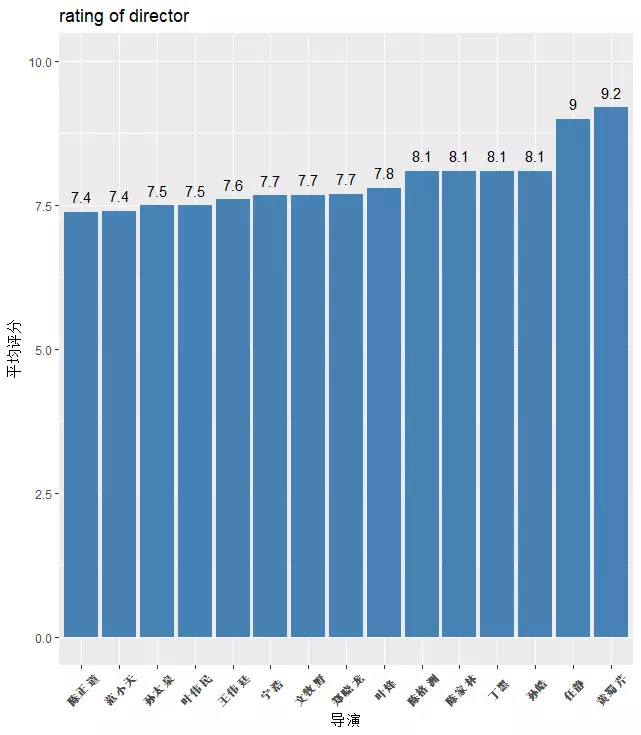
图 a
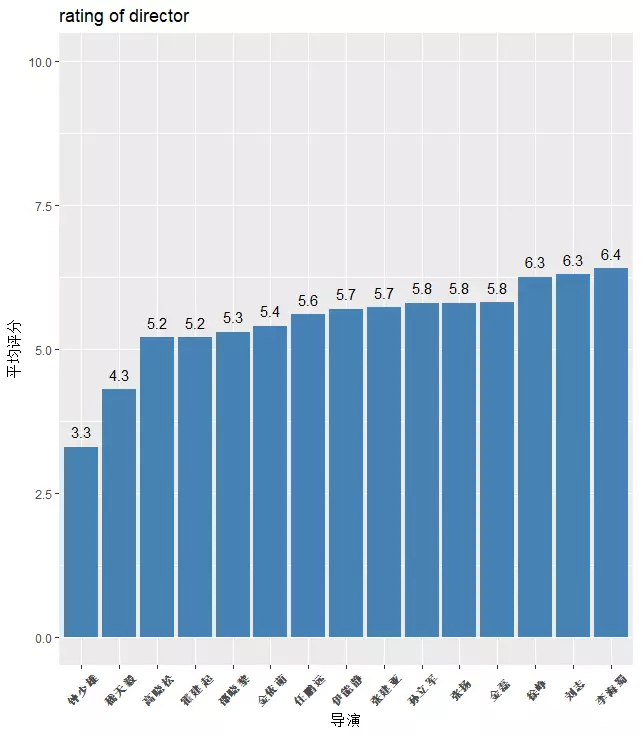
图 b
再看看徐峥合作过的演员情况,图c是和徐峥合作过的演员作品平均评分排名前10的演员,图d是作品平均评分排名后10的演员。合作最多的演员是黄渤,一共有9次的合作,《疯狂的石头》《疯狂的赛车》《无人区》《心花路放》《泰囧》等作品都取得了不错的票房和评分,但是《爱情呼叫转移Ⅱ:爱情左右》只有5.2的评分,导致黄渤没有在这前10里,而张艺兴、孙红雷、罗志祥只和徐峥合作过一期《极限挑战》就9.0靠前了,看来平均值有时候真的会掩盖重要的信息。
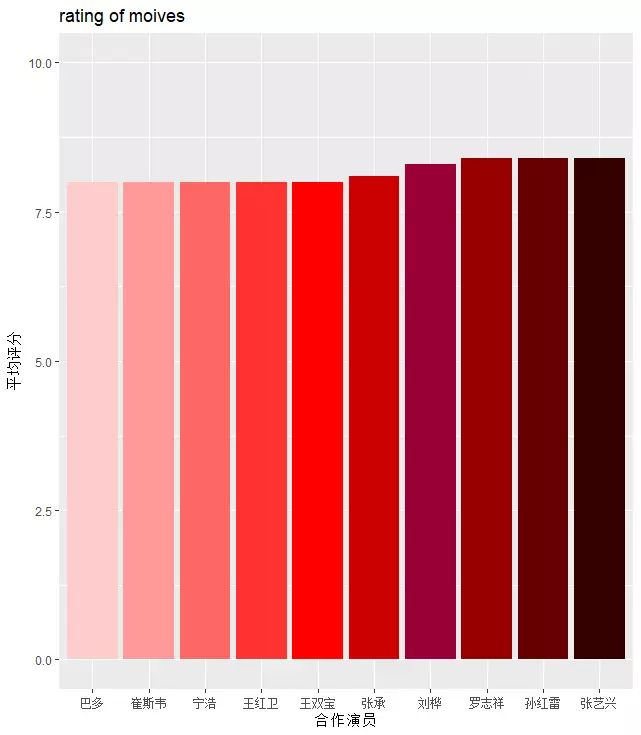
图 c
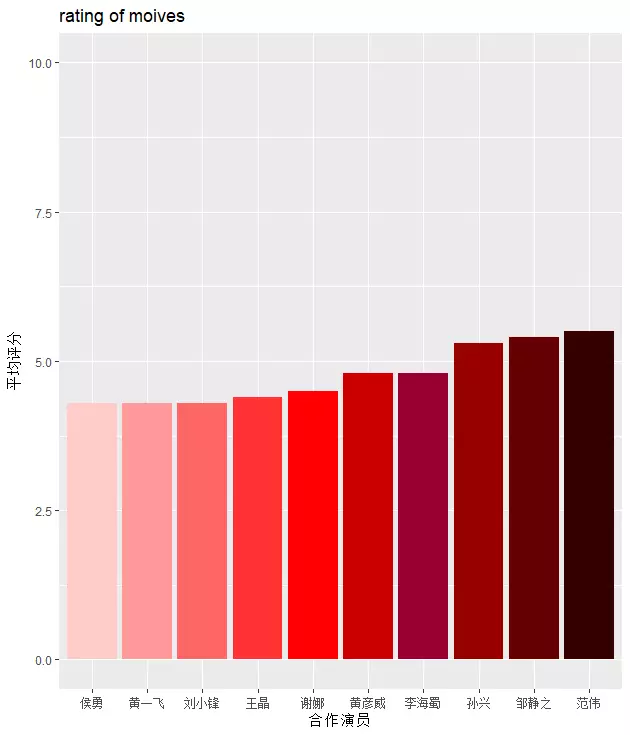
图 d
最后再看看徐峥囧系IP电影选角的演员人气情况,将演员豆瓣上被收藏的次数作为人气的测量,对比《港囧》《泰囧》《人在囧途》的演员人气,看来《港囧》的失败确实很大因素归因为选角,人气明显低于《泰囧》。
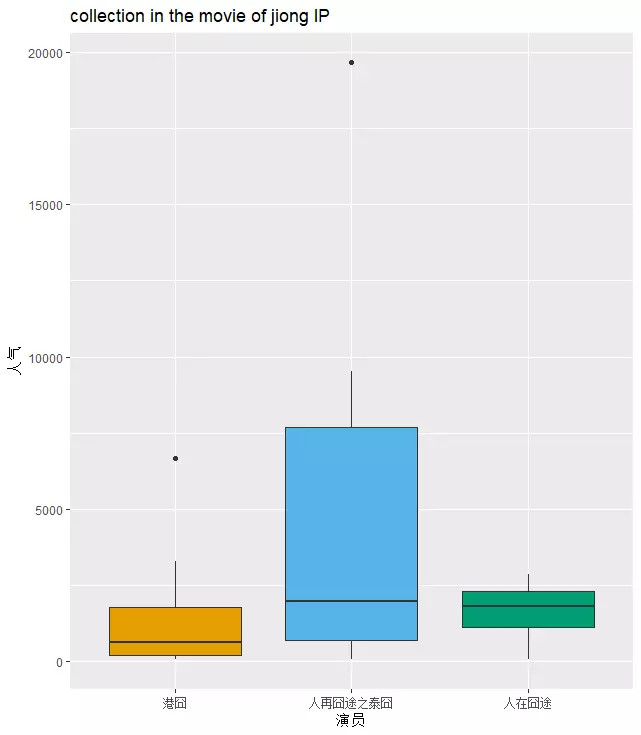
最后再将陶虹的合作演员表爬取下来,看看夫妻二人在电影圈的社交网络关系,陶虹和徐峥的共同出镜次数还挺多,合作过的电影和演员也不少,不过徐峥的出演次数更多,圈子更大,夫妻二人很和谐的搭配方式。

附上R语言的可视化代码:
1library(dplyr)
2library(plyr)# 这个包里面的count函数才能统计文本的个数
3library(tidyverse)
4library(ggplot2)
5library(readxl)
6library(xlsx)
7library(RColorBrewer)
8
9movie_data <- read_excel("D:\partner111.xlsx")
10# 徐峥合作伙伴评分排名前10和后10的演员
11left_data <- movie_data[movie_data$rating!=0, ]# 去掉没有评分的电影
12attach(left_data)
13ave_rate <- aggregate(as.numeric(rating), by=list(par_name), FUN="mean")
14ave_rate$rate <- round(ave_rate$x, 1)
15detach(left_data)
16ave_rate <- ave_rate[order(ave_rate$rate), ]
17col <- brewer.pal(9,'Blues')
18pbbPalette <- c("#FFCCCC","#FF9999","#FF6666","#FF3333","#FF0000","#CC0000","#990033","#990000","#660000","#330000")
19cbbPalette <- c("#000000", "#E69F00", "#56B4E9", "#009E73", "#F0E442", "#0072B2", "#D55E00", "#CC79A7", "#FF0033", "#339999")
20ggplot(data = head(ave_rate,10), aes(x = reorder(Group.1,rate,median), y = rate)) + ylim(0,10) + geom_bar(stat="identity",fill=pbbPalette) +
21 labs(title = "rating of moives", x="合作演员", y="平均评分")
22ggplot(data = tail(ave_rate,10), aes(x = reorder(Group.1,rate,median), y = rate)) + ylim(0,10) + geom_bar(stat="identity",fill=pbbPalette) +
23 labs(title = "rating of moives", x="合作演员", y="平均评分")
24
25# 合作的导演的作品评分
26attach(left_data)
27dir_rate <- aggregate(as.numeric(rating), by=list(director), FUN="mean")
28dir_rate$rate <- round(dir_rate$x, 1)
29detach(left_data)
30dir_rate <- dir_rate[order(dir_rate$rate),]
31ggplot(data = head(dir_rate,15), aes(x = reorder(Group.1,x,median), y = x)) + ylim(0,10) + geom_bar(stat="identity",fill='steelblue') +
32 labs(title = "rating of director", x="导演", y="平均评分") +
33 theme(axis.text.x = element_text(size = 8, family = "myFont", face = "bold", vjust = 0.5, hjust = 0.5, angle = 45)) +
34 geom_text(aes(label = rate, vjust = -0.8, hjust = 0.5), show.legend = TRUE)
35ggplot(data = tail(dir_rate,15), aes(x = reorder(Group.1,x,median), y = x)) + ylim(0,10) + geom_bar(stat="identity",fill='steelblue') +
36 labs(title = "rating of director", x="导演", y="平均评分") +
37 theme(axis.text.x = element_text(size = 8, family = "myFont", face = "bold", vjust = 0.5, hjust = 0.5, angle = 45)) +
38 geom_text(aes(label = rate, vjust = -0.8, hjust = 0.5), show.legend = TRUE)
39
40# 合作的导演次数
41attach(left_data)
42dir_time <- left_data %>% select(movie_name,director)
43dir_time <- dir_time[!(duplicated(left_data$movie_name)),]
44dir_table <- count(dir_time$director)
45detach(left_data)
46dir_table <- dir_table[order(dir_table$freq),]
47ggplot(data = dir_table[dir_table$freq>=2,], aes(x = reorder(x,freq,median), y = freq)) + geom_bar(stat="identity",fill='steelblue') +
48 labs(title = "times of director", x="导演", y="合作次数") +
49 theme(axis.text.x = element_text(size = 8, family = "myFont", face = "bold", vjust = 0.5, hjust = 0.5, angle = 45)) +
50 geom_text(aes(label = freq, vjust = -0.8, hjust = 0.5), show.legend = TRUE)
51
52# 徐峥评分排名前10的电影名
53attach(left_data)
54top_movie <- aggregate(as.numeric(rating), by=list(movie_name), FUN="mean")
55detach(left_data)
56rank_moive <- top_movie[order(top_movie$x), ]
57ggplot(data = tail(rank_moive,10), aes(x = reorder(Group.1,x,median), y = x)) + ylim(0,10) + geom_bar(stat="identity",fill=pbbPalette) +
58 labs(title = "top10 moives", x="电影", y="评分") +
59 theme(axis.text.x = element_text(size = 8, family = "myFont", face = "bold",vjust = 0.7, hjust = 0.7, angle = 45))
60
61# 囧字IP电影的演员人气对比
62jiong <- left_data[left_data$movie_name %in% c("人在囧途","人再囧途之泰囧","港囧"),]
63jiong$collection <- as.numeric(jiong$collection)
64cbbPalette <- c("#E69F00", "#56B4E9", "#009E73")
65ggplot(data = jiong, aes(x = movie_name, y = collection)) + geom_boxplot(fill=cbbPalette) +
66 labs(title = "collection in the movie of jiong IP", x="演员", y="人气")
67
68# 徐峥电影类型对比
69attach(left_data)
70agg_data <- left_data %>% select(movie_name,types,rating)
71agg_data <- agg_data[!(duplicated(left_data$movie_name)),]
72View(agg_data)
73detach(left_data)
74li = list("喜剧","真人秀","爱情","剧情","悬疑","脱口秀","犯罪","动作","惊悚","古装","奇幻","动画")
75type = c()
76ave_rating =c()
77for (i in li){
78 type_moive <- agg_data[grepl(i,agg_data$types), ]
79 ave = mean(as.double(type_moive$rating))
80 type = c(type, i)
81 ave_rating = c(ave_rating, ave)
82}
83type_rating <- data.frame(type=type, ave_rating=ave_rating)
84pbbPalette <- c("#FFCCCC","#FF9999","#FF6666","#FF3333","#FF0033","#FF0000","#CC3333","#CC0000","#990033","#990000","#660000","#330000")
85ggplot(data = type_rating, aes(x = reorder(type,ave_rating,median), y = ave_rating)) + ylim(0,10) + geom_bar(stat="identity",fill=pbbPalette) +
86 labs(title = "rating of types", x="类型", y="平均评分") +
87 theme(axis.text.x = element_text(size = 8, family = "myFont", face = "bold", vjust = 0.5, hjust = 0.5, angle = 45)) +
88 geom_text(aes(label = round(ave_rating,1), vjust = -0.8, hjust = 0.5, color = 'red'), show.legend = TRUE)
89
90
91library(igraph)
92#加载数据框
93attach(movie_data)
94agg_data <- movie_data %>% select(par_name, time)
95detach(movie_data)
96agg_data <- agg_data[!(duplicated(agg_data$par_name)),]
97nrow(agg_data)
98centre <- rep("徐峥",time=148)
99graph_data <- data.frame(centre,agg_data)
100write.xlsx(graph_data,"D:\mydata.xlsx")
101all_data <- read_excel("D:\mydata.xlsx")
102g <- graph.data.frame(all_data)
103# 徐峥的关系网络图
104#生成图片,大小是800*800px
105jpeg(filename='D:\GRAPH1.jpg',width=800,height=800,units='px')
106plot(g,
107 vertex.size=2,#节点大小
108 layout=layout.kamada.kawai, #布局方式
109 vertex.shape='none', #不带边框
110 vertex.label.cex=1, #节点字体大小
111 vertex.label.color="#CC79A7", #节点字体颜色
112 edge.arrow.size=0.2) #连线的箭头的大小
113#关闭图形设备,将缓冲区中的数据写入文件
114dev.off()
115
116# 徐峥和陶虹的关系网络图
117# install.packages("RcolorBrewer")
118library(RColorBrewer)
119col <- brewer.pal(9,'Blues')
120V(g)$label.color <- "#FF0033"# 标签颜色设置
121attach(all_data)
122all_data <- all_data[order(time),]
123n3 <- nrow(all_data[time>6,])
124n2 <- nrow(all_data[time>=3&time<=6,])
125n1 <- nrow(all_data[time<3,])
126detach(all_data)
127edge_col <- c(rep(col[3],n1),rep(col[6],n2),rep(col[9],n3))# 边根据不同的数字设置不同深浅的颜色
128V(g)$size=degree(g)/12
129jpeg(filename='D:\GRAPH2.jpg',width=1000,height=1000,units='px')
130plot(g, layout = layout.fruchterman.reingold,vertex.label.cex=1,edge.color=edge_col,edge.arrow.mode='-')
131dev.off()
往期回顾:
大家都在看

公众号后台回复关键字即可学习
回复 爬虫 爬虫三大案例实战
回复 Python 1小时破冰入门回复 数据挖掘 R语言入门及数据挖掘
回复 人工智能 三个月入门人工智能
回复 数据分析师 数据分析师成长之路
回复 机器学习 机器学习的商业应用
回复 数据科学 数据科学实战
回复 常用算法 常用数据挖掘算法